
本文主要是以香水产品为例,介绍首席增长官常用的:数据采集、数据分析、数据挖掘的过程和常用的算法模型。
一、香水数据处理
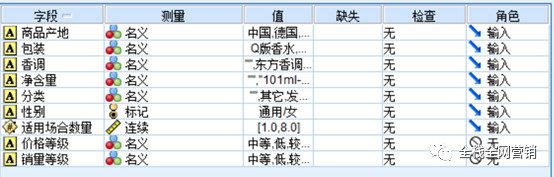
数据来源于某电商网站的香水产品的数据,包括了香水产品的商品名称、产品毛重、商品场地、包装、香调、净含量、分类、适用性别、适用场所、价格,以及评价数这几个维度,总共1009条数据:
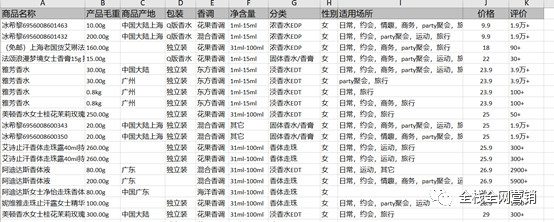

从上图可以看出,这部分数据存在一定数量的缺失值,还存在例如“性别适合场所”、“评价”两个不规范的数据维度,需要对这部分数据做规范化处理。
针对“评价”,这个维度的数据包含中文和数字的混合,末尾还有一个“+”,“+”很容易通过excel来替换掉,但是将“万”转化成准确的数值结果采用excel比较难做到,因此采用python来处理来处理;
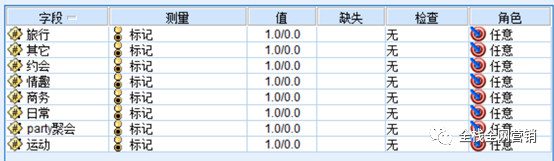
“适用场所”字段包含多个场所,要先算出所有记录的场所合集,这部分也用python来实现。最终分解成“旅行”、“其他”、“约会”、“情趣”等8个字段,其类型是0、1类型,若该香水产品有对应的适用场所,则设置为1,否则设置为0;
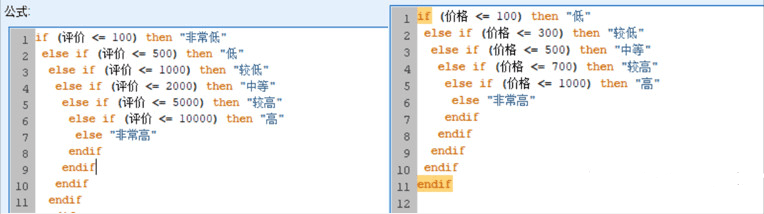
接下来还需要对香水的价格和评价数据做离散化处理,将价格等间距分为6个等级,分别是低、较低、中等、较高、高、非常高;同样的,也需要要评价数做同样处理,分为7个等级;
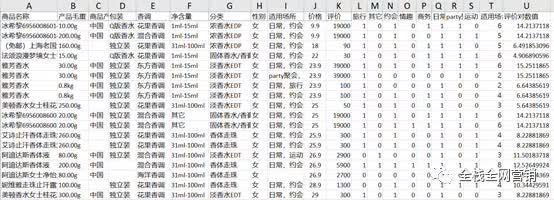
最后还需要将中国大陆、广东、浙江义乌等国内地址统一替换成中国,并且增加“适用场景数量”字段,统计不同香水适合的场所,最终如下图:
二、香水数据分析
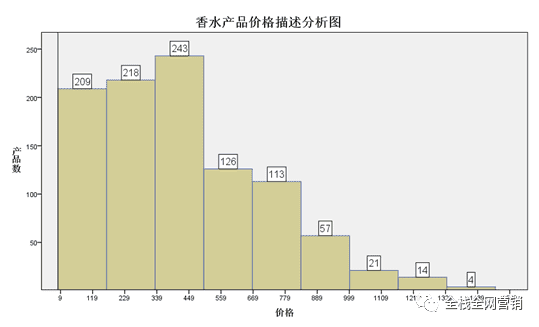
对香水产品的价格做描述分析,约92.43的产品价格在900元一下,最大值为2212元,在样本中可以查询到对应产品为香奈儿/机遇/黄色邂逅女士香水50/100ml/持久淡香精EDP EDP100ml。
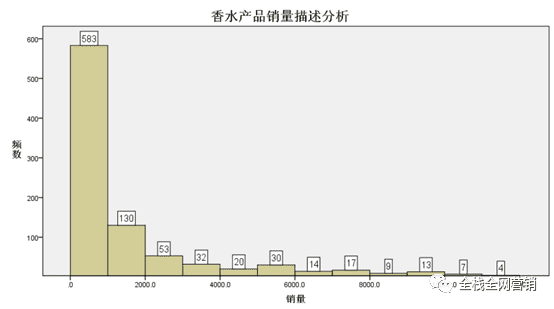
产品的评论说在一定程度上代表了产品的销量,因此此处用产品的评论量来代替产品的销量。对所有产品的销量做统计分析,发现香水产品的销量两级分化明显,有58.47%的产品销量不足1000,有约10%的产品销量大于10000,其中最大值为100000以上,为菲拉格慕香水:
在过滤掉存在的缺失值后,可以得到商品场地的分布图,在下图中法国占据了绝对比例,约为49%,德国和西班牙的香水种类比较少,分别为3.89%和3.97%。

由于商品的评价数跨越范围比较大,且商品销量的两级分化严重,如果直接用评价数来绘制箱型图做分析,会产品大量的离群点。因此对商品的评价数以2为底做对数处理,再按照各个字段对“评价对数值”做分析。
下图是用箱型图描述各个产地香水销量分布,与其他国家的香水产品相比,西班牙和英国的香水产品销量明显偏低,其他国家并没太大的差别。

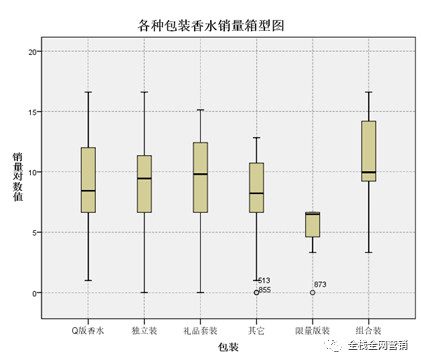
下图是各包装香水销量箱型图,可以看出组合香水的整体销量要高于其他包装的香水,因为组合装的香水往往比较齐全,并且比较优惠,对价格敏感的消费者有较大的吸引力。而限量版香水的销量明显要低于其他包装的香水,主要原因是由于限量版香水的发行量少而且价格较高。其他品包装的香水销量并没有明显的差别。
将不同香调的香水销量做分析,可以看出花果香调和混合香调的香水产品整体的销量要略高于其他香调的香水,而东方香调和其他香调的香水整理销量偏低。东方女性使用香水的习惯教西方女性保守,味道偏好轻盈简单的清淡味道,因此花果香调的香水卖得最好。木质香调等较浓郁的香水遮盖体味功能强,比较适合西方人。

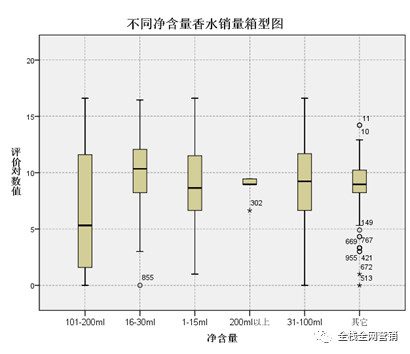
在净含量方面,包装较小的产品销量比较高,包括1-15ml、16-30ml、31-100ml。包装小的产品便携性强,而且我国大部分的香水使用者使用需求并不如欧美国家的消费者高,因此偏好小包装的香水。而101-200ml以及200ml以上规格的香水,不方便携带,而且如果不及时使用完毕,会有变质等问题。
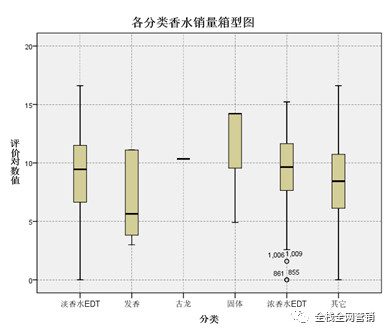
按照分类分析,淡香水EDT和浓香水EDP的销量好,主要是淡香水味道清淡,符合东方女性的消费特征;浓香水主要是针对年纪较大的商务女性和中年女性,也有一定的市场。
接下来对影响香水销量的因素做决策树分析,对香水的适用场所做关联分析,对香水总体做聚类分析,具体如下面的流程图所示:
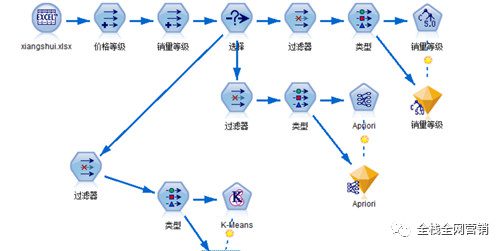
三、影响香水销量的因素分析
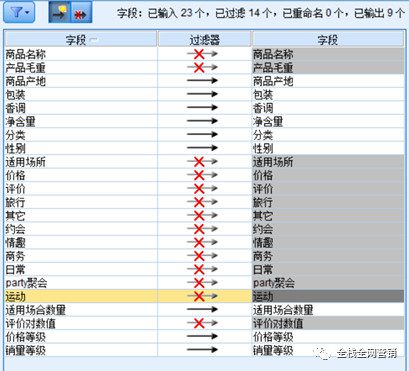
这部分的主要目的是分析各个因素对销量的影响程度。需要对这部分的数据做过滤筛选,剔除出缺失值,并且过滤掉包括商品名称、适用场所、价格、评价等维度,针对商品产地、包装、香调、净含量、分类、性别、适用场景数量、价格等级、销量等级这几个维度做分析。
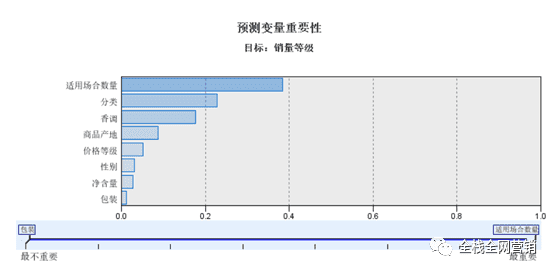
这部分采用C5.0决策树算法分析,挖掘影响香水产品销量等级的因素。可以得到下图。在影响产品销量的因素中,适用场景是最重要的,其次是商品场地、香调和分类,包装、净含量、价格等级、性别影响比较小。
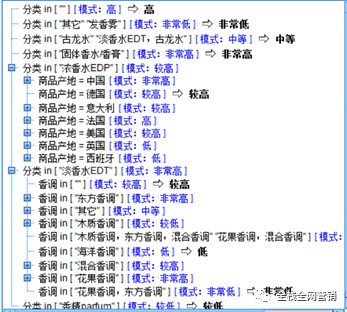
通过决策树分析,可以得到一些结论(这部分就省略了,留在给小密圈的伙伴分享了,哈哈大笑)。
四、香水适用场所关联分析
这部分是需要对香水适用场所做关联分析,需要对数据做预处理,这里我们根据之前的处理生成了不同的8个字段,将含有该类型适用场景的值设置为1,否则设置为0,同时需要对不需要参与分析的字段做过滤处理,最终得到:
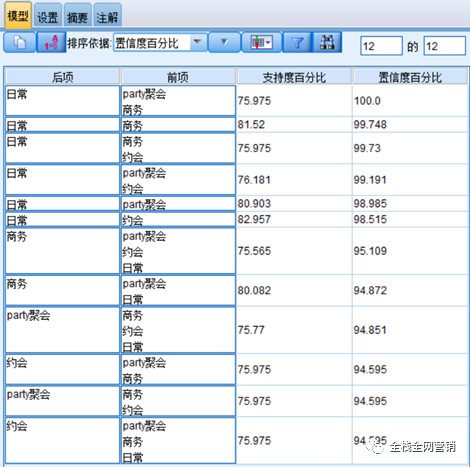
进行关联分析的时候,采用Apriori算法,将最低条件支持度设置为75%,最小规则置信度设置为95%,最终得到12条关联规则,如下图:
五、香水聚类分析:
对香水产品做聚类分析,将商品产地、包装、香调、净含量、分类、性别、使用场景数量、价格等级、销量等级作为聚类分析对象,如下图:
经过初步的测试,这里将聚类的模型的聚类数设置为5,因为如果设置为4类,那么最终得到的聚类质量较差,而且其中预测变量重要性最高的是香调,但得到的类别区分度不高,差异不明显。
当聚类数设置为6或者更高时,虽然聚类质量有所增加,但并不明显,区分过细,容易出现过拟合的情况,结果也没有意义。

如上图所示,预测变量最重要性依次是分类、香调、净含量、产地、性别、包装和适用场景数量。其中,分类是聚类的主要依据,而适用场景数量则是对结果影响最小的因素。
本次聚类的之类相对比较良好,平均silhouette为0.2。经过对数据的分析可知,在进行聚类时,数据分布不均,例如,同一种分类的香水,可能含有不同的净含量、也可能来自不同的地方。因此本次聚类分析中涉及的香水大致可以分为5类。
六、初步的营销建议(此处省略很多字)
综合上述分析,对于希望提升销量的商家来说,在销售的香水产品的选择上,需要选择消费者欢迎,总体销量好的产品:
1、制定价格方面,商家可以将产品价格定位在大众消费品的水平上,并保持正常利润空间,更多考虑运用价格策略扩大产品销路,吸引更多消费者。具体来说,淡香水EDT的销量与价格呈现负相关,而浓香水EDP的销量与价格呈正相关,说明浓香水的买家比较重视品质,对价格不敏感,而淡香水EDT的买家对价格敏感,因此对于不同类型的产品要有具体的价格策略……;
2、产品分类方面,香水的产地、香调、净含量都会对销售产生很大的影响,因此选择正确的类型的香水是提升销量非常重要的方面,法国、意大利是世界上最重要的香水奢侈品产地,有着巨大的影响力……
3、销售策略方面。由于消费者在购买香水的时候体现了明显的价格敏感性,价格低的香水产品销量更好。另外,目前我国香水消费中很大一部分你还是作为礼品,因此,可以制定一个短期促销策略,降低价格……
文:全栈全网营销
相关文章推荐:
《3年时间,从0增长到200亿,他的套路都在这里!》
《新晋网蓝luckin coffee的裂变营销》
《重新定义新用户,看CGO如何破解新用户增长难题?》
更多精彩,关注:增长黑客(GrowthHK.cn)
增长黑客(Growth Hacker)是依靠技术和数据来达成各种营销目标的新型团队角色。从单线思维者时常忽略的角度和高度,梳理整合产品发展的因素,实现低成本甚至零成本带来的有效增长…
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/9861.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫