
AB实验,一般经常叫他的英文名,ABTest,是一种有效的对比测试方法。
通过对比两个不同的方案,选择其中较好的结果作为决策依据。
ABTest在自然科学与互联网行业领域经常被用于研究影响因素的效果优化以及不同条件下的优劣评估,是一种非常有效且严谨的实验方法。
这一回我想与大家分享的是对于ABTest功能设计的总结以及一些问题引发出的思考。谈及ABTest就不得不提及谷歌发布的《Overlapping Experiment Infrastructure: More, Better, Faster Experimentation》这篇论文,互联网行业中各类ABTest功能设计可以说是大多源自此文,因此在介绍ABTest一些功能设计基础时本文也将引用谷歌这篇论文介绍的内容。那么话不多说,旅途开启。
01
—
ABTest
简介前文已简单提及ABTest的核心方法与作用。在互联网行业中,常用于软件亦或是网站功能的调优,通过抽样进行实验,来验证方案是否有提升。
ABTest的原理其实并不难理解,保证除了需要实验的参数因素不变,观察实验中的两个方案各自的表现。从这里可以看出其实ABTest的本质就是控制变量法。
在互联网行业领域中,互联网产品的载体一般为软件或是网站,使用者为人。互联网产品的ABTest即为针对人的实验。一次ABTest的流程,如下。
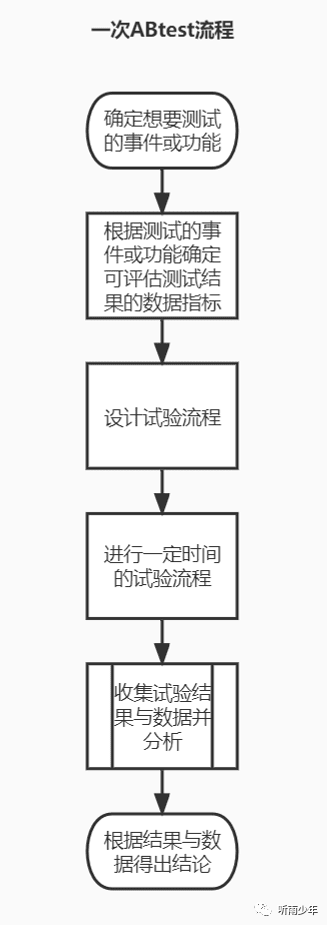

02
—
ABTest的功能设计
(一)实验评估指标的确定
实验的开始需要确认需要研究的命题,对于互联网产品而言,一般都是功能流程、界面元素衍生的行为效果优化以及探索性的效果分析。
在进行实验前,需要确认对于研究的命题,该用什么指标来评估实验的结果。
这个会影响到实验中该制定怎样的实验方案。
现以网页或者软件中常见界面元素设计为例,在某个软件或网站的推广广告素材中,现在设计了一版新的下载引导按钮方案,如何定义结果效果呢?用数据数值来体现结果是非常直观的,所以将方案的结果定义为一个代表结果的指标,此时这个指标可以是下载引导按钮的人均点击次数。
实验评估指标的确定,需要严格地与命题相关,且必须要能代表实验流程的结果。
实验命题是研究新的下载引导按钮是否比现有的更好,则实验流程则是需要将分别引入到两个不同方案中,然后根据他们在不同方案中对按钮的点击事件进行埋点、事件上报,进而对数据进行对比分析。
(二)用户分流
实验方案是将用户分别引入到两个不同的方案中,为了保证实验的准确性,需要确保除了下载按钮的样式不同,其他因素诸如界面中其他元素、用户年龄、性别或地域等其他因素尽可能的在两个方案中相同。此时可以随机的将用户分入两个方案,即可相对的减少其他因素因偶然性集中,保证其他因素不会成为不平等的影响因素。用户的分流是ABTest功能中非常重要的一步。
这里结合谷歌论文《Overlapping Experiment Infrastructure: More, Better, Faster Experimentation》(下称谷歌论文)中的方法说明一下用户分流。
首先是用户流量的分配方式。
用户分流,需要保证用户进入某个实验方案后,不会再进入另一个方案。一般来说一次AB实验,即分为实验组与对照组,实验组即体验到新方案的用户组,对照组则为保持旧方案的用户组,用新旧方案对比来观察效果。
此时如果单纯的对用户进行简单的随机分配,则同一个用户可能会在不同时间进入实验组与对照组,让本次实验产生不具有参考性的行为。
另一方面则是简单的随机分配如果将用户分配到两个不同的实验中,如果两个实验有一定的联系,则同样会对实验产生影响。此时需要尽可能的保证用户分配时,保证以下两点。
- 1. 用户在一个实验中,只进入一个用户组
- 2. 在多个实验同时进行时,一个用户只能参与一个实验
为了保证以上两个前提,直接对用户随机分配就行不通了。此时我们需要找到用户的唯一标识来代表用户,当发现用户已经进入某个实验并成为了某个组的用户后,则不再对他进行分配。
在谷歌论文中介绍了使用取模的方法,例如研究用户群体时,可以对用户ID进行取模1000(或者100也可以,原理都是对流量进行划分,从中按序号取出对应序列的用户);如果是研究使用设备时,则可以对设备ID+用户ID组合进行取模。目前哈希取模是最为常用的方式。
(三)用户分流的改进
用户分配好以后,可以开始进行实验了。比如说取模后0到19为用户组一,20到59为用户组二,60到99为用户组三。
这样一个实验中就可以分配用户组一为对照组,另外两个用户组作为实验组。但是此时就有一个问题,如果我想同时进行多个测试,就得先根据测试的不同,先对方案分配用户,然后对分配完的用户再针测试中的方案对进行一次分配。
如果之后每一次进行同时多个实验都要这么处理,显然不够灵活。在谷歌论文中,为了灵活处理同时多实验的用户分流,引入了流量域、层的概念。先了解一下谷歌论文中几个名词的定义。
- 域:指的是流量被划分后的各个部分。例如我们把用户分成各50%的两个部分,即分成了两个域。
- 层:指的是系统参数构成的一个子集。例如从上例第一个50%的域中,我又将用户分成了3类,各有一定占比,用UI、搜索结果和广告结果区分。
- 实验:指的是在一个流量被划分的部分中,对0个或者多个系统参数进行修改并请求处理的过程。这个可以简单理解我开启了一次AB实验。
那么结合谷歌论文中的示例图,以提升广告点击率为例说明一下这个分流思路。
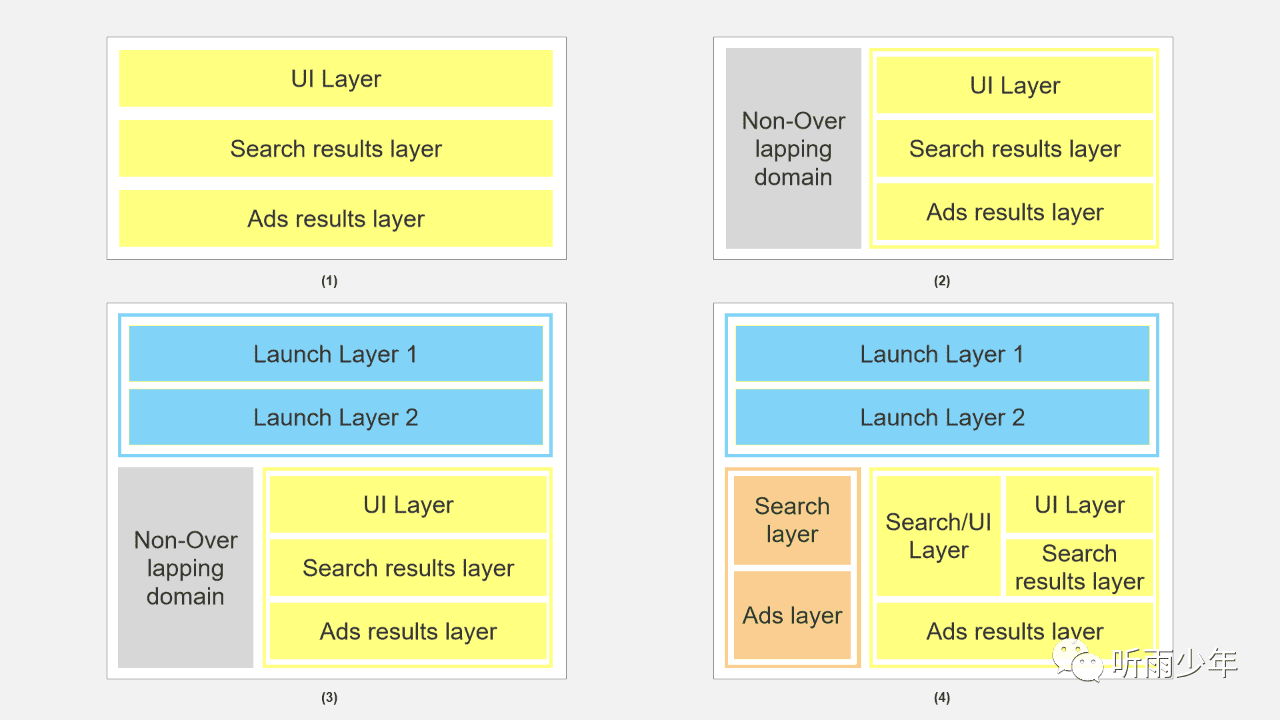
如图(1)所示,根据UI、搜索结果以及广告结果将所有分成3个层,此时就可以同时做这3个参数的实验。
如图(2)所示,引入了一个非重叠层的概念。图(1)称之为重叠层,此时一个用户进入这个域后,可能会进入3个实验中的其中一个。而当一个用户进入图(2)中左侧的非重叠层,则只会进入一个实验,例如专门留了20%的用户进行专项的实验,与此同时重叠层则由其他80%的用户分成3个层,可以同时进行3个实验。
使用如上方法对用户分配后,如此一来就可以很灵活地进行各种测试。测试的设计人员,可以根据不同参数先划分好域,然后再选择对应的域进行用户分层,进而设计实验。有趣的是域和层是可以互相重叠的,意思就是除了可以在域中划分层,层中还可以划分域,例如在UI层中再分成各占50%用户的两个域,再进行实验。这个方式看上去很灵活,不过是需要十分大的用户量来支持的。假如我只有5000的日活,做一个实验时将用户对半分,如果再对其中一部分分层,可参与测试的用户就非常有限了。所以说这里重要的是方法,在实际使用过程中还是简洁点,也便于使用者理解。
除此之外,谷歌论文中还引入了一个启动层(launch layer)的概念。
发布层与之前介绍的用于实验的层略有不同,根据谷歌论文描述:
(1)一个启动层处于默认域中,例如启动层拥有这个层的全部流量
(2)启动层是参数的一个独立分区,例如一个参数最多只能同时在一个启动层和一个正常层中(在同一个域内)
(3)为了让启动层和正常层配合重叠起作用,启动层中的实验有不同的含义。具体而言就是启动层为参数提供了另一种默认值。换一句话说,如果正常的实验层中实验的方案参数没有实验导致测试的参数修改覆盖,此时启动层中的实验将使用指定的备用的参数值,使得启动层的实验就像一个普通的正常测试一样。
如果正常的的实验层中的方案参数进行了修改,此时启动层也会使用该参数,而不是系统默认值以及启动层实验中的值以上是谷歌论文中对于启动层的说明。其实可以将其理解为有实验进行时,启动层会与其中一个保持一样的测试方案,当实验的测试参数修改,例如实验不同的下载引导按钮样式改变了,启动层中的样式也会跟着改变。
我们可以将实验结果较好且理想的实验方案同步到启动层,将其当作灰度测试,逐步提升参与实验的用户量,当确认效果全量开放以后删除这个启动层。启动层可以当作区别于AB实验这种对比测试性质的一个验证性实验层,非常适用于灰度测试以及功能全量上线的流程。
(四)AA实验
前面谈了用户的分流,那么是不是就可以马上使用这个流程进行测试了呢?此时还不行。用户分流时使用唯一标识进行哈希取模后,理论上说所有用户进入不同实验与用户组的概率是一样的,即如果我进行了一个实验分成实验组和对照组,这两个组中的用户性别之类的分布应该是均衡的,不会有显著的区别。
如果用户分流以后开始进行实验流程了,反馈的数据结果是否没有问题,例如埋点是否正常,上报的日志是否有误进而导致最终计算的数据是否有误这些问题,该如何进行验证呢?
在AB实验前,可以通过AA实验来进行功能的验证。
AA实验与AB实验非常类似,只不过AA实验中并不需要将实验方案中的参数值分成不同方案进行试验,而是全部使用相同的参数值以及保证其他条件都一样。在保证参与实验的参数与条件一致的情况下,如果最后出现了数据的明显异常,则证明AB实验流程中某个环节存在问题,是用户分流、埋点还是其他问题,此时就可以排查了。
03
—
实验的数据分析当我进行了一次实验,目标是测试一个手机应用中,不同推广文案导致的图片点击率哪个更好,我得到了其中某个图片的人均点击数量优于另外一个方案,是否就能将其当作结论马上上线使用呢?
如果用户量足够多,越接近用户总量,那么这个结论可靠性就越高。但如果只是抽样进行了实验,则结论未必可靠。这就涉及了实验中是否存在偶然性、随机性导致了实验结果更好。为了确认结论是否因随机性导致,此时需要采用假设检验的方案进行验证。之所以要做这一步验证,是因为AB实验是对用户抽样以后进行测试,样本是否能代表总体,样本的数据结果是否有随机性影响,都需要确认以后才可以下结论。
由于假设检验涉及诸多统计学知识,所以这一部分仅结合AB实验进行说明,详细的假设检验方法以及验证方法朋友们可以学习概率论相关书籍的知识。
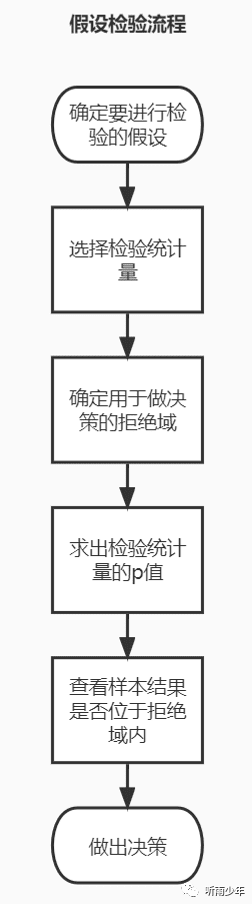
假设检验的第一步,将你认为的结论作为原假设,与原假设对立的观点作为备选假设。例如原假设为新的文案提升了广告图片的点击率,备选假设则是没有。
第二步则是选择检验统计量。此时需要了解实验评估指标的概率分布。
对于人均点击次数这样的均值指标,需要使用t检验,此时数据属于t分布。t检验用于样本含量小且总体标准差未知的正态分布,利用t分布推算差异产生的概率,进而比较两个平均值差异是否显著。如果差异显著,此时方可下结论说,新的广告文案提升了点击效果,否则只能视为一次偶然。
而对于留存率、点击率这类漏斗类的指标,需要使用卡方检验,此时数据属于卡方分布。卡方分布用于检查实际结果与期望结果之间何时存在显著差别,主要有两个用途,一个是检验拟拟合优度,另一个则是检验两个变量的独立性。卡方分布通过卡方这个检验统计量来比较期望结果与实际结果之间的差别,进而得出观察频数极值的发生概率。
两种检验方式有各自的检验统计量,需要根据实验方案以及评估指标进行选择。
第三步选择确定拒绝域,拒绝域是拒绝原假设的检验统计量所有数值的集合,此时先要定义显著性水平,显著性水平表示希望在观察结果的不可能达到多大时拒绝原假设,用α表示,常取5%或者1%,拒绝域的零界点用c标识,拒绝域则定义为小于显著性水平的数值,即P(x<c)<α。
第四步为求p值,p值是某个小于或者等于拒绝域方向上的一个样本数值的概率。p值可通过查询概率表获得。
第五步查看样本结果是否位于拒绝域以内,若p值小于显著性水平,则位于拒绝域以内。
第六步做出决策,若样本结果位于拒绝域以内,则有充分证据拒绝原假设,此时可以接受备选假设。
以上只是简单的介绍假设检验的流程,其中设计的统计学知识与检验方法,限于本文主题与篇幅便不再多言,有兴趣的朋友可以通过概率论相关的书籍学习。最重要的是,AB实验得到数据后,并不是本次实验的结束,如果没有客观的分析来佐证结论,光靠表象数据来决策的AB实验,其实也就是一次拍脑袋决策罢了。
04
—
关于ABTest的一些思考通过ABTest功能设计以及假设检验,似乎就完成了一次实验。不过对于实验依然有一些实际操作中的问题值得关注。
(一)小样本量与t检验
在实际进行ABTest的过程中,我们并不像谷歌一样不愁流量,也许手上的产品就只有几千甚至于几百、几十的用户量,此时在用户量较低,做完ABTest以后,是非常需要使用假设检验来确认结果的。
在学习假设检验的过程中,在很多教科书介绍t检验时,当样本量小于30时,则为小样本使用t检验;超过30则为大样本,此时则使用Z检验。为什么是30?其实在做实验的时候不要拘泥于30这个数字,因为这就是一个曾经科技还不发达时难以使用大数据样本的年代,对于t分布划分的一个参考数据。当样本量增加时,t分布会越来越接近正态分布,此时做假设检验时则可以直接使用正态分布代替t分布了。这就是30这个数字存在的意义,只不过是人为地划定一个标准,来定义t检验的使用范围。
通过t检验中30这个样本数据,我想分享给大家的是千万不要陷入一个误区,大于30就是大样本,此时因为样本数据足够大就不需要假设检验来验证假设。客观,是很难做到的。
(二)为什么不建议让一个用户进入多个实验
在进行ABTest的过程中,也许会同时进行多个实验,如果实验的参数基本没有什么影响,理论上说确实可以让用户同时参与多个实验。但是这件事是功能策划者以及实验设计者难以保证的。
ABTest其实就是控制变量法,如果让用户进入了多个实验,此时就是增加了实验中的变量,为了严谨以及客观的结论,用户最好在同一时间只参与一个实验,同时在实验期间内只进入成为一个用户组的成员。
(三)关于数据时效性的关注
对于互联网产品的ABTest而言,大多都会聚焦于以天为单位的核心行为与指标,因为人类就是以天为单位进行生活的。
我们常见的留存率、使用时长以及访问次数这类行为类指标,都会因为夜间休息白天使用而产生影响,此时对于产品数据的使用会根据人的习惯而体现规律。此时实验用天为单位的指标作为实验评估指标的粒度是完全没问题的。
但是也需要考虑更小粒度的数据来进行实验。例如优化广告曝光点击效果,此时以人均曝光次数、人均点击次数为实验评估指标,通过小时粒度观察早上10点到晚上10点这12个小时的数据,并不会比以天为粒度的数据缺少客观性,因为看广告这个行为的频率与习惯与24小时运作的人类生活习惯并没有非常强的关联,如果可以快速的获取数据就可以更加快速的决策。
同理在进行广告投放进行用户增长时,观察一天引入的用户数量的同时,也可以观察对比不同小时时间段的增长效果,可以有效的分析投放的时间影响。
甚至基于需求都还可以考虑到分钟粒度的数据。所以在进行ABTest功能设计以及实验时,对于数据粒度的需求和应用也需要充分考虑。
(四)最后的碎碎念
行文下来,不甚满意。
我对于谷歌论文的理解并不是很深刻,也许还存在错误,希望读者多多赐教。本想把假设检验也详细说明,但是这部分丰富的数理统计以及概率论知识让这部分内容的介绍,并不是一篇文章里的章节能说清楚的,所以本文还是集中在ABTest这个主题上做分享介绍。
听闻字节跳动与快手有非常强悍的ABTest平台,在撰文搜集资料期间也阅读了一些公司分享的公开文章,让我对这后面的技术设计、产品功能设计更加着迷。
奈何没有什么机会能参与实践,是我的一大遗憾了。
总之不论文章好坏,希望能对ABtest感兴趣的朋友们提供帮助。这本来是一篇写给我自己的总结,今天也分享与你。
祝你生活愉快。
文:听雨少年 一个平凡的人,一个想变得有趣的人,一个愿意聆听故事的人。
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/coo/76475.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫