
产品或服务在市场上的成败和营销组合策略密不可分。那如何才能把营销组合这个利器用好呢?你想知道的保姆级指南都在这里了!
什么是营销组合建模
准确的营销组合模型可能是产品成败的关键!
营销组合建模定义
营销组合模型的主要目的是了解各种营销活动如何推动产品的业务指标。品牌用她来作为决策工具,来评估各种营销活动在提高投资回报率 (RoI) 方面的有效性。
营销组合模型怎么做呢?
营销组合建模把营销和促销活动(增量驱动因素)与其他(基本)驱动因素的贡献对于业务指标的贡献进行拆解。这些影响营销组合的因素可以定义为:
增量驱动因素:由电视和平面广告、数字广告、价格折扣、促销、社会推广等营销活动产生的业务增量。
基本驱动因素:基本驱动是在没有任何广告的情况下实现的。这是多年来品牌建立起来的资产。除非有经济或大环境变化,基本驱动因素通常是固定的。
其他驱动因素:作为基本驱动因素的一个子部分,由于营销活动的长期而积累的品牌价值带来的增量。
营销组合建模为营销人员带来的好处
1. 更好地分配营销预算
通过确定最合适的营销渠道(例如电视、线上广告、印刷、广播等)来实现营销目标并获得最大收益回报。
2. 更好地执行广告活动
通过 MMM,可以指导在高效营销渠道中的最佳支出量,以避免效益的饱和。
3. 预测营销收益
使用MMM 可以根据计划的营销活动预算预测收益,例如支出增加 10%,会期待收益增加多少。另一方面,为了实现业务指标提升 10%, 所需的支出水平是多少。
变量对营销组合模型的影响
在建立营销组合模型的时候,只有将前面提到的主要变量考虑在内,才能对销售做出准确的预测。
营销组合元素被分解为三个变量:增量、基础和其他。这三类变量可以进一步细分为一系列影响产品或服务市场表现的因素。了解这些变量中对于营销人员准确基于促销活动和产品分销预测其业务影响至关重要。
基本变量
基本变量是独立于营销组合变量,不受营销行为营销影响的变量。它们受各种其他因素的影响,如品牌价值、季节性和其他非营销因素,如 GDP、增长率、消费者情绪等。确定这样一个基线对于了解营销活动对产品销量和产品分销的影响至关重要.
一些基本变量包括:
1. 价格:价格是决定营销组合策略的一个非常重要的因素。价格决定了目标消费群以及广告、促销和分销策略。
定价模式是影响营销组合的关键因素之一,因为:
- 定价将产品的价值传达给客户,并对业务绩效产生直接影响
- 对定价的影响取决于产品的弹性
2. 分销:在营销组合模型中,分销是指销售产品商店或地点的数量、库存单位(产品分类)的数量和流动速度。分销策略受市场结构、公司目标、资源以及整体营销策略的影响
产品的分销也是关键,因为:
- 强大的产品分销链加上有针对性的营销活动直接对业务成果产生作用。
- 产品的丰富分类让消费者有更多种选择,进行挑选和购买。
3.季节性:季节性就是周期性的变化。往往季节性带来潜在的机会是巨大的,也是一年中商业上最关键的时期。例如,电子产品的销售主要是在假期前后。
4. 宏观经济变量:宏观经济因素极大地影响企业及其营销策略。了解 GDP、失业率、购买力、增长率、通货膨胀和消费者情绪等宏观因素非常重要,这些因素虽然不受企业控制,但他们会对其产生重大影响。
增量
所有营销组合元素都可以大致分为三类:
1. ATL(Above-the-Line)线上营销:线上营销包括大部分非针对性且覆盖面广的广告活动。ATL 活动的主要目标是帮助建立品牌并提高消费者的认知度和熟悉度。
ATL 营销的例子包括电视广告、广播广告、印刷广告(杂志和报纸)和产品植入(电影院和剧院)。
线上营销的优势包括:
- 为吸引大量观众
- 为产品创造知名度
- 长期品牌建设
2. BTL(Blow-the-Line)线下营销:线下广告包括针对目标消费者群体的非常具体、令人难忘和直接的广告活动。通常被称为直接营销策略,线下策略更多地关注转化而不是建立品牌。
BTL 活动的示例包括促销、折扣、社交媒体营销、直邮营销活动、店内营销、活动和会议。
线下营销的优势:
- 专门针对个人客户
- 推动立竿见影的影响
- 帮助衡量营销活动的有效性和转化率
3. TTL(Through-the-Line)营销:Through-the-Line 广告同时使用 ATL 和 BTL 营销策略。最近的市场消费趋势需要整合 ATL 和 BTL 策略以获得更好的结果。
TTL 营销的一个例子是 360° 营销——以品牌建设和数字营销(数字广告和视频)转化双管起齐下。
其他
多项营销举措的长期影响可分为以下几类:
1. 竞争
密切关注竞争是保持品牌优势的关键。市场竞争可以是直接的,也可以是间接的。
- 直接竞争对手:直接竞争对手是拥有相同产品的企业。例如,苹果 iPhone 与三星 Galaxy 竞争。
- 间接竞争对手:间接竞争对手是那些不提供类似产品但以另一种方式满足相同需求的人。例如,亚马逊 Kindle 和平装书是间接竞争,因为它们是替代品。
2.光环( Halo )和 蚕食(Cannibalization) 影响
光环效应是一个术语,表示消费者偏爱某个品牌的产品,因为他们对同一品牌的其他产品有过积极的体验。光环效应可以被视为衡量品牌实力和品牌忠诚度的指标。例如,消费者喜欢 Apple iPad 平板电脑是基于他们对 Apple iPhone 的积极体验。
蚕食效应是指由于同一品牌的其他产品的性能而对一个产品产生的负面影响。这主要发生在品牌有多个相似类别的产品的情况下。例如,消费者对 iPad 的偏爱会蚕食 MacBook 的销量。
在营销组合模型中,对同一品牌其他产品的基本变量或增量变量进行测试,来了解其对所考虑产品的光环或蚕食效应的影响。
新变量出现
随着营销环境的变化,出现了许多新平台,以及品牌与客户互动的方式,尤其是千禧一代客户。这也导致需要在营销组合模型中考虑新的变量。
其中一些变量是
产品/市场趋势:市场趋势/产品趋势是推动产品基线结果和了解消费者对产品需求的关键。
产品发布:营销人员规划营销策略将新产品推向市场并支持新产品的发布。
活动和会议:品牌需要寻找机会与潜在客户建立关系并通过定期活动和会议推广他们的产品。
行为指标:接触点、在线行为指标和回购率等变量可为企业提供更深入的客户洞察。
社交指标:品牌在 Twitter、Facebook、YouTube、博客和论坛等社交平台上的影响力或认可度可以通过关注者、页面浏览量、评论、浏览量、订阅和其他社交媒体数据等指示性指标来衡量。也可以通过社交聆听收集其他社交媒体数据,比如所在行业的对话和趋势。
营销组合方法
数据准备可以帮助确定可能影响营销组合模型的关键可衡量指标。
营销组合策略所包含的每个变量类别都涉及一组用于衡量不同营销活动绩效的指标。如下表:
有时候,一些特殊情况可能会阻碍营销人员基于上述指标开发完整的营销组合模型:
- 缺失值
- 异常值
缺失值
数据分析的挑战之一是缺失值。缺失值是变量数据不可用。通常,这是由于记录数据期间的错误或由于数据不可用而发生的。缺失值可能会导致有偏差的变量,进而可能影响业务结果。
要解决缺失值,我们首先需要了解它为什么会出现。缺失值的一些最常见原因是:
- 数据在整个分析时间段内不全。
- 没有发生某个事件。
- 人们跳过了对调查问卷的某些问题的回答。
- 调查问卷某些问题不适用。
- 随机的丢失了数据。
而处理缺失值的方法一般都被分为几类:
插补:插补是一种用估计值填充缺失数据的方法。均值、中位数和众数是常用的插补方法。
预测:时间序列预测可用于预测/反向预测缺失的记录。除了预测之外,我们还可以使用 4 周移动平均来估计缺失值。
用零替换:当交易或促销活动发生时才有数据,我们应该简单地用零替换丢失的数据,以表示当天没有交易或促销。
删除:调查问卷中,通常会用删除修复缺失值。在调查中,我们无法猜测人们的选择,因此删除缺少数据是比较好的选择。
其他:如果需要,也可以使用其他复杂的技术来处理缺失值,例如预测和 KNN 插补。
异常值
MMM 的主要目标之一是尝试解释尖峰,也称为异常值。异常值可能出现也可能不出现。
出现异常值的原因可能是季节性、新产品发布、活动、促销、折扣、竞争对手的行为等。也可能是完全是随机的。通过区分随机引起的异常值和特定原因引起的,可以在模型中包含正确的变量并对其进行测试来检查它们是否可以解释异常值。
比如:在产品发布期间和圣诞节和感恩节等节日期间,电子产品的销售额要高得多。
营销组合建模中的分析类型
通过探索性的数据分心,营销人员可以了解他们的营销计划的结果。
理解各种营销活动的结果所涉及的统计分析可以大致分为两种不同的类型:
- 单变量分析
- 双变量分析
单变量分析
单变量分析是被分析的数据仅包含一个变量。单变量分析主要用于描述营销组合变量数据并发现其规律。
可以用以下方法:
- 集中趋势(均值、中值和众数)
- 分散(范围和方差)
- 最大值和最小值
- 四分位数
- 标准差
单变量分析用于
分析数据中的模式:例如,仅在假期商家提供更高的折扣
确定创建新变量的可能性:例如,如果假期期间和非假期期间提供的折扣存在明显差异,可以创建两个单独的折扣变量——假期折扣和非假期折扣分别测试它们的影响
识别数据中的任何异常值:单变量数据可以使用频率分布表、条形图、直方图、饼状图、折线图
双变量分析
双变量分析是了解营销组两个不同变量之间关系的分析。
在 MMM 中,双变量分析帮助我们
- 确定与因变量有关系的关键变量
- 确定变量与因变量表现出的关系类型
双变量分析的类型:
- 数值和数值变量:可以使用散点图和折线图将两个数值变量之间的关系可视化。
- 数值和分类变量:数值和分类变量之间的关系可以使用折线图或组合图进行可视化。
- 分类和分类变量:分类和分类变量之间的关系可以使用堆积柱形图和组合图进行可视化。
数据转换
数据转化,可以帮助做出更加准确的预测和高效的营销组合模型。
数据转换是将变量替换为该变量的函数。例如,可以用 X 的平方根或对数替换变量 X。
本质上,变换代表响应曲线。某些变量与销售额没有线性关系。例如,电视 GRP 通常与销售额存在非线性关系。电视 GRP 的增加只会在一定程度上增加销售额,之后增长将趋于饱和。
双变量分析就可以了解营销组合中两个不同变量之间关系。
数据转换的实际应用一般有两种:
- 广告Adstock效应
- 滞后效应
什么是广告Adstock效应?
Adstock广告是一个术语,用于衡量从第一次开始广告时所产生的记忆效应。营销人员可以把Adstock广告用作销售响应建模中的变量,例如回归分析,它代表广告的半衰期。
什么是滞后效应?
滞后效应用于表示当该变量值存在某种固有顺序时,滞后变量的先前值的影响。这种效应比如某些研究中很有用,不同的受试者接受一系列治疗时候,想调查前一时期的治疗是否对当前时期的结果有影响。
了解广告Adstock效应和滞后效应对于开发营销组合模型来衡量广告支出的影响都至关重要。例如,在电视上播放的广告可能比在数字模式下播放的广告更容易记住。
S 曲线变换的意义:
实际上,大多数广告活动都会对 KPI 产生非线性影响,并且表现出收益递减。研究表明,在达到某个阈值之前,初始广告支出几乎没有影响,在此阈值之后,可以观察到对 KPI 的显着影响。然后,往往会随着支出达到饱和点而后其影响再次减弱。这整个影响可以用 S 曲线变换的形式表达。从营销组合的角度来看,使用Gompertz、Chapman Richards 和 Weibull 以及 Morgan-Mercer-Flodin 转换会更准确。
营销组合建模技术
想知道如何构建最有效的营销组合模型?这些技巧可以帮助您入门!
虽然营销组合的重要性显而易见,但大多数营销人员仍然不确定如何构建营销组合模型。“回归”方法可以预测所有营销变量的最有效组合。
在回归中,数据分为两类:因变量 (DV) 和自变量 (IDV)。分析自变量如何影响因变量的结果是回归的关键。通过这样做,营销人员将能够准确估计公司净利润的营销组合。
最常用的营销组合建模回归方法是:
- 线性回归
- 乘法回归
1. 线性回归模型
当 DV 是连续的并且假设 DV 和 IDV 之间的关系是线性的时,可以应用线性回归。
可以使用以下等式定义关系:
这里‘y’是要估计的因变量,X是自变量,ε是误差项。βi 是回归系数。观察到的结果 Y 和预测的结果 y 之间的差异称为预测误差。回归分析主要用于:
- 因果分析
- 预测变更的影响
- 预测趋势
然而,这种方法在大量数据上表现不佳,因为它对异常值、多重共线性和变量相关性很敏感。
2. 乘法回归模型
加性模型意味着解释变量的每个附加单元的恒定绝对效应。只有当企业发生在更稳定的环境中并且不受解释变量之间相互作用的影响时,它们才适用。但在定价为零等场景下,销售额(DV)将变得无穷大。


为了克服线性模型固有的局限性,通常首选乘法模型。与加性线性模型相比,这些模型更加实用现实情况。在这些模型中,IDV 相乘而不是相加。
有两种乘法模型:
- 半对数模型
- 对数模型
在对数线性模型中,自变量相乘。
Salest = exp(Intercept) * exp(β1*Pricingt) * exp(β2*Distributiont) * exp(β3*Mediat) * exp(β4*Discountst) * exp(β5*Seasonalityt) * exp(β6*Promotionst) *…
这也可以改写为
Salest = exp (Intercept + β1*Pricingt+ β2*Distributiont+ β3*Mediat+ β4*Discountst+ β5*Seasonalityt+ β6*Promotionst+ …)
对目标变量做对数变换可以使模型形式线性化,可以变为可加模型。因变量是对数变换的;这是加法模型和半对数模型之间的唯一区别。
Ln (Salest) = Intercept + β1*Pricingt+ β2*Distributiont+ β3*Mediat+ β4*Discountst+ β5*Seasonalityt+ β6*Promotionst+ …
对数线性模型的一些好处是:
- 系数 β 可以解释为业务成果(销售额)相对于自变量单位变化的百分比变化。
- 模型中的每个自变量都在其他变量增量已经实现的基础上。因此,它们更接近实时场景。
在 Log-Log 模型中,除了目标变量之外,自变量还要进行对数变换。
Salest = exp(Intercept) * β1*Pricingt * β2*Distributiont * exp(β3*Mediat) * exp(β4*Discountst) * exp(β5*Seasonalityt) * exp(β6*Promotionst) *…
以线性形式重写模型,
Ln (Salest) = Intercept + β1*Ln (Pricingt)+ β2*Ln (Distributiont)+ β3*Mediat+ β4*Discountst+ β5*Seasonalityt+ β6*Promotionst+ …
Log-Linear 和 Log-Log 模型之间的主要区别在于响应系数的解释。在 Log-Log 模型中,系数被解释为响应自变量 1% 变化带来的业务成果(销售额)变化百分比
β = %ΔDependent_Variable / %ΔExplanatory_Variable
这意味着目标变量对解释变量的弹性恒定。在对数线性模型中,不能直接估计弹性,但可以根据每个时间段的系数 β·X 计算弹性。它的绝对值随着解释变量的增加而增加。
模型优化
模型误差会影响营销组合模型的准确性。我们来看看下面的技术如何最大限度地减少模型中的误差。
营销组合模型预测和实际结果中难免会出现误差。在许多情况下,模型可能在训练数据上表现良好,但在验证(测试)数据上表现不佳。为了解决这个问题,营销人员需要在偏差-方差之间权衡。
偏差是我们模型的预测值与实际值之间的差异。具有高偏差的模型在训练和测试数据上均会出现较高的误差。
方差是由于对训练集的微小变化敏感而产生的误差。有这个问题的模型在训练数据上表现很好,但在测试数据上有很高的误差。
偏差-方差权衡
在模型中,可能会出现这两个常见的问题。模型可能存在欠拟合(模型无法捕获趋势)或过拟合(模型捕获噪声和参数)。欠拟合的模型可能具有高偏差和低方差。另一方面,过度拟合的模型可能具有低偏差和高方差。因此,营销人员需要通过偏差-方差权衡在两者之间取得平衡,以开发出准确的模型。
数据的正则化
为了达到这种平衡,正则化是一个重要方法。通过正则化,可以向目标函数添加惩罚项,并使用该惩罚项完全控制模型复杂度。
有两种主要的用于正则化的营销组合建模回归技术是:
- Lasso 回归
- Ridge 回归
- Elastic-net 回归
Lasso 回归
在Lasso回归中,我们可以通过添加一个惩罚项(系数的绝对值之和)来最小化目标函数。这也称为最小绝对偏差方法。通过惩罚绝对值,估计系数缩小到零,从而避免过度拟合并且使得模型的学习速度更快。
Ridge 回归
在Ridge回归中,我们尝试通过添加惩罚项(系数的平方和)来最小化目标函数。当预测变量之间存在多重共线性问题时,一个变量的系数取决于模式中其他预测变量。通过添加惩罚项,共线变量的系数将缩小,但其中显着的预测关系予以保留。
Elastic-net 回归
Elastic-net 回归是 ridge 和 lasso 的混合体,结合了两者的惩罚项。通常可以当作首选方法,因为它结合了两种模型的优点。
模型选择
选择最合适的营销组合模型对于营销人员能够做出准确的预测和估计至关重要。选择模型时需要考虑两个主要因素:
商业逻辑
市场组合模型必须反映实际的市场情况。模型应该适应市场随时间的变化。
例如,智能手机的价格可能具有弹性,因此这款智能手机的销量可能在很大程度上取决于定价。如果价格大幅上涨,可能会对智能手机的销售产生负面影响。在这种情况下,产品价格可以用作模型中的变量来捕捉这种趋势。
根据我们在开发营销组合模型方面的丰富经验,以下是一些符合商业逻辑的建议:
- 产品的媒体广告应该在模型中具有正系数。
- 品牌其他产品的促销活动,可能会出现光环或蚕食。
- 其他产品的光环影响应该低于营销活动对产品的影响。
- 由于商业电视广告TVC 具有更高的品牌召回率,因此 TVC 的广告Adstock价值应高于数字广告。
- 折扣和促销活动将对销售产生直接影响
- 产品既可以由产品的品牌也可以由销售该产品的合作伙伴进行推广。
统计学意义
模型生成后,应该检查有效性和预测质量。根据不同的商业目的,可以采用各种模型统计数据
以下是营销组合建模中最常见的统计数据。
1. R 平方
R 平方衡量数据与拟合回归线的接近程度。它也被称为决定系数。R 平方始终介于 0 和 100% 之间:0% 表示模型并没有反应响应数据围绕其均值的任何。100% 表示模型完全反应了响应数据围绕其均值的变化。
R平方的一般公式是:
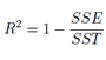
其中 SSE = 平方误差总和,SST = 总平方和。
2. 调整后的 R 平方:
调整后的 R 平方是 R 平方的改进版本,已经对模型中预测变量数量进行了。只有当新的预测着实用的时候才会增加。调整后的 R 平方可用于比较包含不同预测变量数量的回归模型。
3.系数
回归系数是未知总体参数的估计值,描述预测变量与响应之间的关系。在线性回归中,系数是乘以预测值的值。
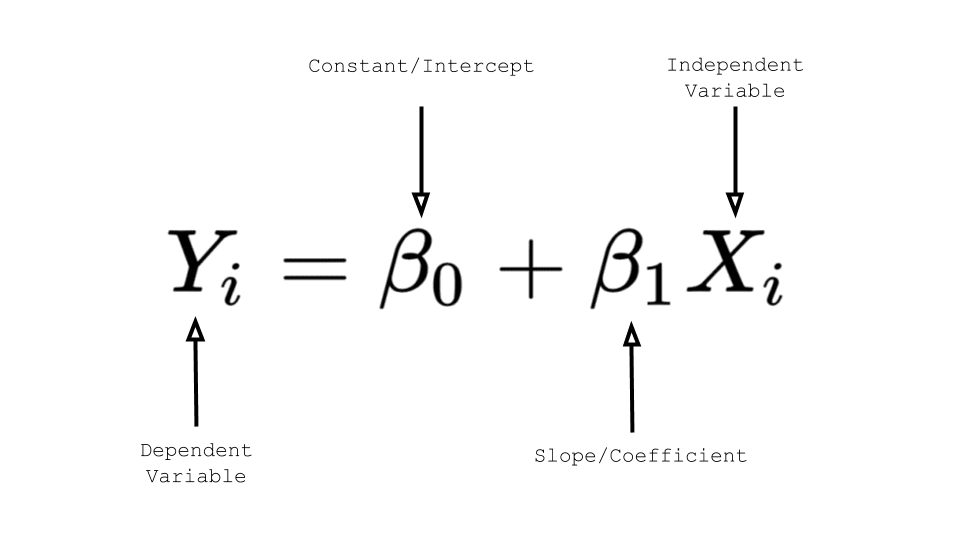
每个系数的符号表示预测变量和响应变量之间关系的方向。正号表示随着预测变量的增加,响应变量也增加。负号表示随着预测变量的增加,响应变量减少。
4. 可变通胀因素
方差膨胀因子 (VIF) 检测回归分析中的多重共线性。多重共线性是指模型中的预测变量(即自变量)之间存在相关性。VIF 估计回归系数的方差因模型中的多重共线性而膨胀的程度。模型中的每个变量都将针对所有其他可用变量进行回归以计算 VIF。
VIF 通常计算为
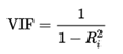
其中 Ri2 是通过回归“i”获得的 R 平方值,预测变量针对所有其他变量。
5. 平均绝对误差 (MAE)
MAE 测量一组预测中误差的平均幅度。它是预测和实际观察之间绝对差异的平均值,其中所有个体差异具有相同的权重。
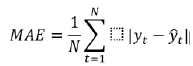
其中 yt 是时间‘t’的实际值,并且ŷt 是时间‘t’的预测值。
6. 平均绝对百分比误差 (MAPE)
MAPE 是每个观测值或预测值的平均绝对百分比误差减去实际值除以实际值:
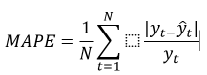
其中 yt 是时间‘t’的实际值,并且ŷt 是时间‘t’的预测值
驱动因素的量化
你的营销组合模型是否按照预期执行?下面的这些技术可以计算营销组合模型的效果。
应用模型后,营销人员需要分析可用数据以判断模型的表现。有两种广泛的分析方法:
1. 计算贡献
业务指标被分解为基础贡献和由于季节性和其他因素造成的贡献。营销组合模型可以帮助确定销售的关键驱动因素。计算贡献取决于所使用的模型类型:
线性模型
假设数据为每周粒度,从 MMM 中,我们将得到回归方程(Business metric = Base + ®1* Driver1 + ®2*Driver2…),其中 ® 是每个驱动因素的对应系数
预测值按周计算 (Predicted value = Base + ®1* Driver1 + ®2*Driver2…),将系数 (®) 与每周级别的相应驱动因素值相乘以计算驱动因素的贡献 == ®1* Driver1, ®2*Driver2…
对数线性模型
假设数据为每周粒度,从 MMM 中,我们将得到回归方程Ln (Business metric) = Base + ®1* Driver1 + ®2*Driver2…其中 ® 是每个驱动因素的相应系数。
预测值按周计算(Predicted value = Base + ®1* Driver1 + ®2*Driver2…),将系数 (®) 与每周级别的相应驱动因素值相乘以计算驱动因素贡献 = ®1* Driver1, ®2*Driver2…
2. 原因分析
原因分析解释了不同时期每个驱动因素对业务指标的贡献的变化。借助原因分析,可以将同比 (YOY) 或季度环比 (QOQ) 增长的变化归因于驱动因素对业务指标的贡献。
预算优化
优化是从所有可行解决方案列表中得出最理想解决方案的过程。优化问题可以根据约束变量的类型、变量的性质、所涉及的方程的性质、变量的允许值、目标函数的数量等分为不同的类别。设计营销组合优化问题涉及多个步骤。
1. 构建模型
此步骤涉及模型目标、模型变量和模型约束。
- 目标:这是衡量要最小化或最大化的模型性能。例如,在 MMM 的情况下,目标一般是最大化 KPI(销售额)。
- 变量:变量是模型中要优化的驱动变量。例如,电视支出、在线支出等营销驱动因素是模型的变量。
- 约束:是一些函数来描述变量之间的关系并定义变量的最大允许值。例如,2017 财年的总支出低于 1 亿美元。
2. 识别优化算法
一旦构建了模型,就会根据优化问题的性质选择合适的算法进行优化。有许多可用于优化的方法。其中一些(基于问题类型)是:
- 非线性约束优化:IPOPT、GRG Non-Linear、ANTIGONE、CONOPT、KNITRO、SNOPT 等。
- 线性优化:BDMLP、Clp、Gurobi、OOQP、CPLEX 等。
- 全局优化:ASA、BARON、icos、PGAPack、scip 等。
3.优化方案
优化的结果可以是全局的,也可以是局部的。这取决于所使用的求解算法的类型。因此,对于相同的目标,不同的求解方案返回不同类型的解。最佳解决方案是根据业务环境选择的。
- 全局最优:这是优化引擎尝试使用所有可能的变量值并最终为目标找到一个最佳解决方案的解决方案。
- 局部最优:在这种解决方案中,优化引擎具有大量变量选项,并且在求解时,最终会在相邻的一组解决方案中得到次优解决方案。
4. 优化范围
营销优化是通过改进营销活动策略以最大化预期业务。由于 MMM 的性质大多是非线性的,因此通常要使用非线性约束算法进行优化。以下为营销组合优化的一些例子,这些例子回答了战略规划的关键问题,例如营销杠杆的影响、跨不同营销渠道的优化、跨时间段优化等等。
- 要将当前销售水平提高 x%,不同营销渠道所需的支出水平是多少?比如,要将销售额提高 10%,要在电视广告或折扣或促销活动上投入多少?
- 如果当前支出水平增加了 x%,业务指标(销售额、收入等)会发生什么变化?比如,在电视上额外花费 2000 万美元,可以获得多少销售额?这些额外的支出将分配到哪里?
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/market/51735.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫