
想必做SEO的人,多多少少都会懂点搜索引擎原理,虽说对于专业的算法不必进行深入研究,但还是需要简单了解一下搜索引擎的工作原理,对其策略及算法原理有个简单的认知,这样才能更好地做好SEO工作。正所谓,知其然,更要知其所以然嘛。
那么,搜索引擎到底是怎么工作的呢?
想必如果大家特意了解过的话,无论是网络上还是SEO相关的书籍,对于搜索引擎的工作原理讲解得都相对清楚,在此小编不会太深入讲解其中复杂高深的搜索引擎架构和检索技术,而是以科普的方式,将搜索引擎工作原理简单梳理一下,以帮助大家更好地理解认知。
接下来以痞子瑞《SEO深度解释》一书中关于搜索引擎的大概架构跟大家进行讲解:
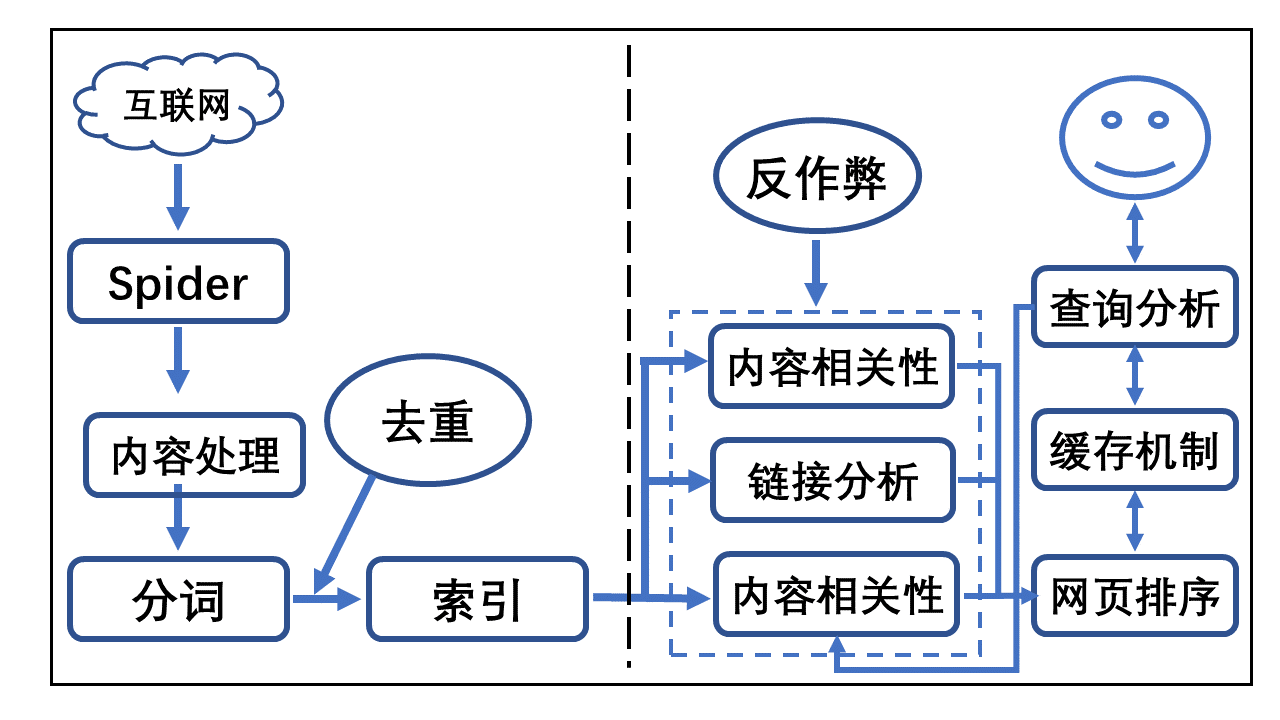

如上图所示,搜索引擎的大致架构分为虚线左右两个部分:
抓取建库,即主动抓取网页进行一系列处理后建立索引,等待用户搜索;
匹配结果,即分析用户搜索意图,进而展现用户所需要的搜索结果。
1、抓取建库
关于抓取建库,即搜索引擎主动抓取网页,并进行内容处理、索引部分的流程和机制一般如下:
第一步:派出爬虫Spider,按照一定的策略把网页抓取回到搜索引擎服务器;
第二步:对抓取回来的网页进行内容处理,消除噪声、提取该页面主题文本内容等;
第三步:对网页的文本内容进行中文分词;
第四步:分词完毕后判断该页面内容是否与已索引网页重复,剔除重复页,对剩余网页进行倒排索引,然后等待用户检索。
2、匹配结果
当有用户进行搜索查询时,搜索引擎工作的流程机制一般如下:
第一步:先对用户所查询的关键词进行分词处理,并根据用户的地理位置和历史检索特征进行用户需求分析,以便使用地域性搜索结果和个性化搜索结果展示用户最需要的内容;
第二步:查找缓存中是否有该关键词的查询结果,如果有,进一步综合该用户的各种信息分析判断其真正需求,对缓存中的结果进行微调或直接呈现给用户;
第三步:如果缓存不存在该用户所查询的关键词,那么就在索引库进行调取排名呈现,并将该关键词和对应的搜索结果加入到缓存中;
第四步:搜索结果网页排名是根据用户的搜索词和搜索需求,对索引库中的网页进行相关性、重要性(权重)和用户体验的高低进行综合分析所得。
3、大白话解读版本
以上就是搜索引擎的工作原理的大致流程,倘若看完之后还有点懵,也没关系,接下来小编以“相亲”为例跟大家好好讲解一番~~
准备好了嘛?大白话版本的搜索引擎原理要来咯~
为了方便大家理解,先来个游戏设定:
媒婆:搜索引擎/爬虫Spider
适龄少女:网页
男求亲者:用户
OK,剧情开始咯~
一位男求亲者(用户)想要找对象,由于身边的资源有限,因而只能去求助媒婆(搜索引擎)帮忙牵桥搭线,以便更快地物色到适合自己的对象。
于是他就找到了这个媒婆,跟媒婆讲述了自己对对象的基本要求:“身高不低于160CM、中等身材、温柔体贴、最好是个老师”(用户搜索关键词)
好了,媒婆收到了男求亲者的要求之后,就会根据这个要求,从她的早早准备好的适龄少女资料库(网页)进行筛选,排除掉身高160CM以下的、不是中等身材的、不够温柔体贴的;然后将符合要求的适龄少女按照相应要求满足程度进行排序,优先推荐是老师的少女。当然,倘若媒婆的资料库里暂时没有完全匹配的,也会适当根据自身经验来进行推荐。(匹配结果)
【而媒婆搜集这个适龄少女资料库的过程就相当于爬虫抓取建库的过程~】
媒婆建立这个资料库,需要通过各种渠道,例如走访方圆十公里,甚至更远的地方,(爬虫Spider)了解并收集适龄少女的相关信息,然后对这些信息进行加工整理归档,按优质进行排序,以便男求亲者上门时可以根据其要求快速匹配合适的适龄少女。
男求亲者根据媒婆的推荐进行了解对方的信息,从而最后确定要不要进入相亲见面环节~
怎么样?这样一梳理,是不是对搜索引擎的大致流程有一个比较深刻的理解了呢?
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/market/75322.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫