
“零一万物坚决做To C,不做赔钱的To B,要做能赚钱的To B。”2024年6月14日,在智源大会上,零一万物创始人李开复如此坚定地说道。
而与之相对,中国工程院院士、清华大学智能产业研究院(AIR)院长张亚勤院士认为,在具身智能阶段,To B的应用可能会比To C更快落地,“现阶段大模型真正赚钱的则在于B端基础设施层面,包括芯片、硬件、服务器等。”在经历了“百模大战”之后,2024年中国大模型开始走向商业化落地。但在大模型商业化的落地过程中,到底应该是To C还是To B,是行业中一直争论的焦点。一方观点认为,B端应用目前相对明确,能够快速实现在多个场景中广泛应用,且几乎覆盖了所有行业,而C端则需要一款爆款应用的出现,现阶段还需要对其有一定的耐心。
另一方观点则认为,B端没有利润,大家都在卷价格战,导致大模型利润被极致压缩。同时中国企业对软件付费的意愿并不高,所以相对来说C端能够更快速获得预期的收益与回报。
以此争论为基础,当前头部大模型厂商已经形成两条不同的大模型商业化路径:
- 一种是坚定走C端应用,以大模型头部创业公司百川智能、月之暗面、零一万物为主;
- 一种是以B端应用为主,同步兼顾C端应用,以百度智能云、腾讯云等云厂商们为主,也包括坚持两条腿走路的创业公司MiniMax,和以B端为主的智谱AI。
但总体来说,现阶段大模型创业公司更偏向于走门槛更低,回报更快的C端商业化路线。而B端商业化则逐渐成为了云厂商们的主战场。中国大模型正经历从PoC(概念验证)到商业落地的关键阶段,短期来看,大模型在C端应用门槛更低,但行业竞争更加激烈,能够成功的路径也更陡峭。在B端应用上,越来越多同质化的产品和服务、愈发“内卷”的价格,也似乎正在走中国SaaS的老路。那么,大模型商业化落地究竟该如何避免“囚徒困境”?“我们预测下半年中国大模型能够达到甚至超越GPT4水平,这是一个重要分界点”,智源研究院院长王仲远说道,“基于一个很好的基座大模型,未来两三年我们将会看到大量应用产生。”
今年年底之前,国内会进入大模型应用爆发期。其中,在C端应用赛道,大模型头部创业公司是坚定的拥护者,除零一万物之外,百川智能和月之暗面,也是坚定走C端应用路线。一方面,是B端落地周期长,投入与预期收益回报不成正比。月之暗面曾表示,大模型能力还在迭代,国内B端市场产品需要私有化部署和定制开发,整体周期长,很难跟上大模型能力的快速提升。李开复也表示,现阶段大部分传统公司都不太敢采用巨大颠覆式技术进行业务创新。更为严重的是,中国大多数公司并不认可软件价值,不愿意为软件付费。“甚至有些大公司会觉得,我用你的大模型,你用我的品牌融资,你也很划算,那我为什么要付钱给你?这种心态导致部分大公司只愿支付很低的价格采购大模型应用,大模型公司也只能给出折中的方案,能达到惊艳效果的方案寥寥无几。”李开复直言,现在有许多大模型公司在竞标时越竞越低,做一单赔一单,导致企业利润很低。但当前大模型在C端应用的商业模式,似乎并未完全走通。近期据外媒报道,OpenAI在过去六个月内,年度经常收入增长到了34亿美元。从其业务发展来看,提供收入增长的是ChatGPT系列的订阅费和通过API调用模型支付的费用。
但据媒体推算,5月ChatGPT Plus订阅的总收入可能在6000万美元左右,整个ChatGPT Plus会员费年化收益逾7.2亿美元,在34亿美元总收入中,只占1/5。OpenAI赚钱的大头很可能来自API,而为API付费的多数是B端的企业客户。
事实上,目前国内大模型创业公司都在持续探索在C端应用落地的商业模式。比如月之暗面旗下的kimi推出了“打赏”功能,金额从5.2元到399元不等。
对于kimi推出的打赏功能,王小川认为这意味着用户不是为工具买单,而是把大模型当成一个伙伴来看,“这是正确的商业理念”。同时,王小川也认为,中国商业环境里To B的市场规模比To C小10倍,To B收的是人民币,花的是美金。大厂都会卷这件事情,只是没想到大家这么狠,都卷到0了,这肯定是大厂射程范围内的。大模型创业公司想要实现突围,就要做差异化。相比于其他类型创业公司,这一波大模型创业公司做C端商业化的特点,是做“超级模型”+“超级应用”,也就是技术+产品的双驱动路线。如月之暗面有专注于长文本能力的大模型kimi,并基于kimi推出了Kimi Chat App,其通过C端用户对产品的体验和功能进行直接反馈的即时反馈机制,使得Kimi Chat能够迅速进行产品迭代和优化。Kimi智能助手在2024年1月的访问量达142万,在大模型创业公司的“AI ChatBots”产品中居于首位,月环比增长率为94.1%,增长速度在大模型创业公司中排名第一。但Kimi Chat并不属于一款真正的超级应用。在王小川看来,超级应用必须要满足三个条件,包括应用可靠性高,能够充分理解用户意图,DAU在3000万~3亿之间。“回顾移动互联网时代或更早期的技术革命,每次新技术的出现都需要一定的周期,包括技术能力的提升、成本的降低以及硬件的支持。当这些条件具备时,能够解决真实用户需求的C端爆款应用才会出现。”王仲远如此说道。现阶段,我们仍需对C端爆款应用的出现保持一定的耐心。不过,王仲远认为,智能体(Agent)很有可能会成为爆款应用的一个方向,大模型可以让它成为真正意义上的智能助理。这是C端应用重要方向,也是令人兴奋的前景。也有行业人士表示:“因为Agent是和过去移动互联网完全不一样的东西,大家会率先开始在Agent中找相关的应用落地。”无疑,大模型在C端的商业应用门槛更低,但与此同时,该赛道的竞争也更加激烈。除这些大模型明星创企之外,百度、腾讯、科大讯飞,字节跳动、360都发布了AI应用助手,可以说各大厂都在加注C端应用,而凭借着自身在生态、用户等方面构筑的优势,大厂们在C端赛道会容易被用户所接受。不过,大模型尚处于发展初期,真正的超级应用尚未出现,于任何玩家而言都有机会。在此过程中,如何走通C端应用的商业模式,也成为大模型在C端落地的关键。当然,行业中也有一部分人,认为大模型率先商业化落地场景应该在B端。“To B马上能商业化,基本不用烧钱”。金沙江创投主管合伙人朱啸虎在谈到AIGC时,曾反复强调这个观点。他的逻辑是“中国的AIGC短期内肯定做ToB,起来快。iPhone、大哥大、电脑出来的时候,都是To B先用,马上能提高生产力、见到效果,企业愿意花钱。To C要等到iPhone 3时刻”。事实上,王仲远与朱啸虎持同一观点。王仲远表示,三年内能看到To B场景,五年内看到To C的场景。B端应用目前相对明确,许多大模型已在多个场景中广泛应用,几乎覆盖所有行业。在王仲远看来,2023年之前的弱人工智能时代,只能针对特定场景、特定任务训练特定模型,从而达到特定效果。而2023年之后,随着步入通用人工智能时代,其最大的特点是泛化性、通用性和跨领域的特性,这将影响几乎所有行业。如大模型在生成摘要方面效果非常好,因此对所有与文书相关的工作、文案处理等效率提升作用显著,文生图、文生视频技术则能产生有创意的图片和视频,是提升效率的工具。“大模型作为生产力和效率工具的作用非常明确。”王仲远如此说道。但如果说,大模型在C端的商业化应用,还可以凭借对行业的Know-how,从0到1构建核心能力,那么,面向B端的商业化落地,更多的还是一种生态资源实力的比拼。原因在于,此前有不少大企业和中小企业对大模型其实都颇为感兴趣,但当真正的进行落地应用时,却又很难能做出最后决策:二是对大企业来说各个业务和部门繁多且交叉复杂,使用大模型的试错成本很大;三是中小企业则是由于成本限制和缺乏专业数据处理的经验,容易导致AI模型的实际应用效果很难与自身业务快速适配,企业存在“赔了夫人又折兵”的创新担忧。字节方面的高管此前曾粗略地算过一笔账,企业要想用AI做一项创新,至少要消耗100亿Token,如果按照大模型之前的售价,平均需要花费80万元……很明显,现在大模型想要在B端落地商业化的前提,就是价格要让大家都用得起。一名火山引擎内部人士表示,虽然行业在讨论用AI大模型重构业务,但在日常工作生活里很少能感受到大模型能力的落地,“降价本质上是降低使用门槛。”也正因此,近2个月来,由字节掀起了一波大模型降价潮,甚至腾讯云、百度智能云、阿里云等宣布部分大模型产品可以免费使用。
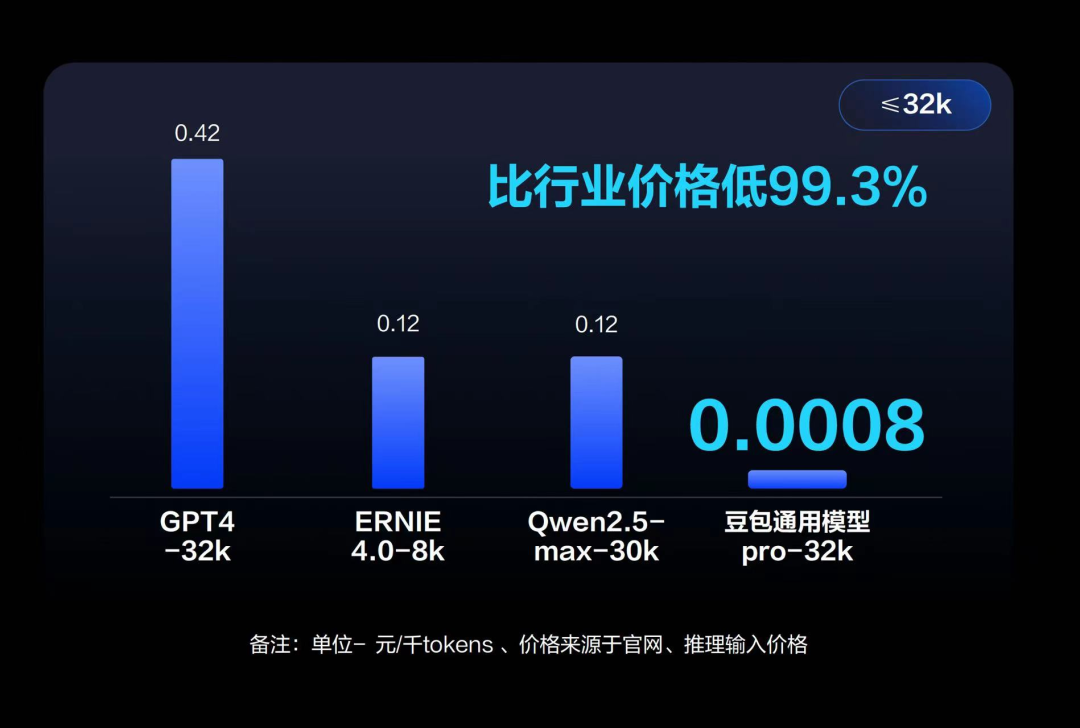
大模型降价乃至免费或许会暂时带来些许成本压力,但对一众云厂商们来说,其靠着更低的价格,却能够更快地构建出自身的AI开发生态的同时,也能够降低企业使用大模型的门槛和试错成本,从而推动大模型能够在更多B端业务场景中落地。
大模型面向B端的落地应用,实质上成为了一场在算力、生态、产品等多方面的比拼。而在这场比拼中,云厂商们无疑成为主要玩家。王小川认为,此轮降价是仅限于云服务厂商的动作,“核心要看你的商业模式是什么,如果你是做To B服务,降价最后卖的(就)不是模型本身,是整套云服务。”猎豹移动董事长兼CEO傅盛也认为,降的最凶的都是有云服务的大公司,通过大模型来获取云客户,“羊毛出在猪身上,降得起”,而大模型创业公司没有这样的生态,必须另寻商业模式。面向未来,于大模型创企而言,行业淘汰赛也正在加剧,云厂商通过降价抢占市场规模,也势必会挤占大模型创企的生存空间。与此同时,面对技术迭代进展的漫漫征途,如果大模型创业公司的商业化进展不及预期,那么估值处于第二、第三梯队的创业公司,也将会面临淘汰。但云厂商们一味的通过降价来收割市场规模,真的能够加速大模型商业化落地吗?如果说大模型在C端的商业化落地应用,还处于你好、我好、大家好的状态,在B端则可以说是“杀”疯了。云厂商们通过价格战来“跑马圈地”,这对于大模型商业化发展究竟是好还是坏?事实上,现阶段大模型在B端商业化落地进程,与中国SaaS服务非常相似。大模型也是提供标准的泛化能力,在面向企业服务时同样需要进行私有化部署和定制化发展。毕竟,大模型的训练迭代升级,离不开高质量的数据,如果企业将私有数据“投喂”大模型进行训练,训练结果却被友商抄走,则得不偿失。背后原因则在于,一方面中国SaaS厂商众多,内卷非常惨烈,大打价格战,也导致企业利润低,并且SaaS其实是一个标准化的产品服务,但在国内落地的过程中,逐渐变形,被定制化和项目制所绑架,这也是导致其利润低的原因之一。另一方面,则就像前文李开复所言,国内企业对软件的重视程度并不高,企业不认可软件的价值,不愿意为软件服务付费,加之中国SaaS服务内卷,并未出现一个足够与国外头部相抗衡的产品。中国企业很擅长用价格换规模,移动互联网时代如此,大模型时代亦如此。现阶段,除了B端的大模型在集体降价,甚至不少C端的大模型产品也在大量烧钱投流买量。但王仲远表示:“价格低确实更有利于更多场景的尝试和爆发,但我们的基础模型能力还没有逼近GPT4,还需要进一步提升,这意味着它依然需要大幅资金投入。过早的价格战或者低于成本的价格战,不利于后续投资。”价格降下去容易,但想要再增长上去,却非常难。价格战能够持续扩大自身的市场占有率和规模,但只有当规模足够大时,才能够平摊自己的成本支出,实现盈利。实际上,如果一个大模型被广泛认为特别好用,随着使用规模扩大,规模效应自然会显现。模型规模上去了,其价格以及工程师们通过各种工程架构系统优化所带来的成本降低也会随之而来。不管是C端,还是B端,大模型商业化落地都面临着激烈的竞争。于C端应用创业者而言,技术的领先性只是暂时的,一定要把握时间窗口,打出自己的品牌知名度和用户壁垒。而于B端应用,最重要的则是持续迭代大模型本身的技术能力和渠道能力。有百度内部人士表示:“长期来看,模型厂商最终竞争的还是模型本身的能力,只有把基础模型效果做得足够好,才能构筑竞争壁垒。”但不管如何,当前大模型商业化进程仅仅是初期,仍需要全行业正向循环,避免走中国SaaS服务的老路。本文来自投稿,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/model/119437.html


 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



