
7月5日,2024世界人工智能大会·腾讯论坛在上海世博中心举办,腾讯公布大模型的最新进展和落地案例。
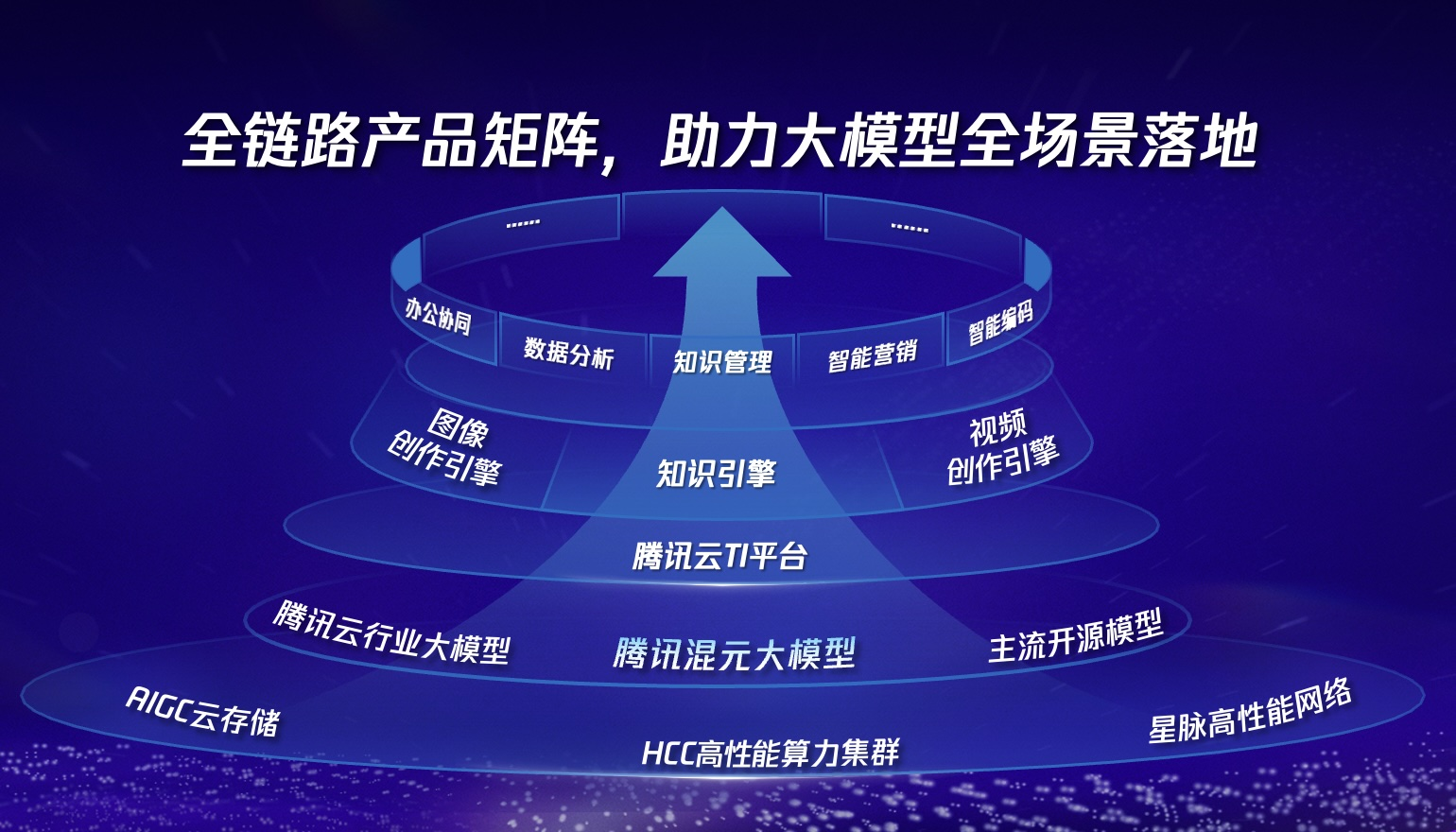
目前,腾讯围绕大模型已经构建起全链路的产品矩阵,包括底层基础设施、自研大模型、模型开发平台、智能体开发平台和面向场景的多元智能应用等,帮助企业客户将大模型快速落地到场景中去。

腾讯集团副总裁蒋杰表示,腾讯将人工智能视为公司长期战略。从语音到图像,再到大模型,每一次人工智能的浪潮里,腾讯始终坚持以自主技术创新为核心动力,结合场景推动AI的研究与落地。经过近一年的迭代升级,腾讯混元大模型在国内率先采用MoE架构,参数量已达到万亿,tokens数量超过7万亿,居国内大模型第一梯队。腾讯将发挥“专心致志、做好比特”的专长,将更多的“比特”转化成智能生产力,推动大模型等前沿人工智能技术在实体经济、文化保护、科学发现等领域的应用,为全社会的智能升级做好技术支持。
腾讯云副总裁、腾讯云智能负责人、优图实验室负责人吴运声表示,通过混元大模型底座、TI平台、知识引擎、图像创作引擎、视频创作引擎等产品的不断迭代与发展,腾讯目前已经围绕办公协同、知识管理、智能客服、营销等全场景,为产业用户提供全链路的模型服务,让大模型真正实现落地,帮助企业提质增效。
据介绍,腾讯混元大模型的单日调用Tokens已经达到千亿级别,单日调用次数超过3亿,并在云上新开放了混元-lite 256k版本、vision多模态版本,以及代码生成、角色扮演、functioncall等子模型和接口,满足不同企业和开发者的需求。
大模型工具升级,加速落地产业场景
为了进一步降低大模型的使用门槛,今年5月,腾讯云发布了“大模型知识引擎”、“大模型图像创作引擎”和“大模型视频创作引擎”三款PaaS工具,让企业能快速调用大模型的底层能力,构建适合自身场景的应用。
其中,知识引擎聚焦企业知识服务场景。通过该平台,企业用自然语言,5分钟就可以开发出一款知识服务应用,快速在客服营销、企业知识社区等业务场景落地。在本次论坛上,知识引擎发布了全新的多模态检索能力,支持图文互搜、以图搜图,能够结合知识库中检索返回的图文片段,给出图文并茂的答案。同时,知识引擎进一步扩展了企业知识类型的覆盖面,升级了泛BI对话式数据问答体验,支持超大表格、多表场景的多步骤推理、多条件筛选、求和计算,并扩展支持对接客户主流数据库。
图像创作引擎基于腾讯混元大模型底座,具备高质量的AI图像生成和编辑能力,能够为企业客户提供图像风格化、AI写真等能力。目前,图像创作引擎新增了商品背景生成、百变头像、模特换装、百变换装和线稿生图等接口,大幅降低了营销和影视行业的制作成本。
在视频领域,视频创作引擎推出复杂舞蹈编排算法,利用先进的3D建模技术和背部生成技术,上传一张图片,就可以让人物流畅地进行转身舞蹈,未来也将支持多人舞蹈的复杂编排。同时,视频转译功能接入混元文生文大模型和 TTS 技术,大幅提升转译后音频的自然度、相似度和语速效果。
面向想要自己训练大模型的行业客户,腾讯云推出了向量数据库和一站式机器学习平台TI平台等工具。腾讯云向量数据库Tencent Cloud VectorDB每日支撑超过3700亿次向量检索请求,可支持千亿级向量规模存储,百万级 QPS 及毫秒级查询延迟,适用于大模型的训练推理、RAG场景、AI应用以及搜索推荐服务,实现企业数据接入AI的效率比传统方案提升10倍。
TI平台提供从数据预处理、模型构建、模型训练、模型评估到模型服务的全流程开发支持,帮助企业加速开发,降本增效。在TI平台的助力下,阅文集团、瑞金医院-上海市数字医学创新中心等已经训练出了自己的行业大模型。
阅文集团副总裁黄琰介绍,去年7月,阅文集团发布了国内网络文学行业首个大模型“阅文妙笔”。经过近一年的探索实践,妙笔大模型在辅助网文多模态创作、支持用户与角色对话、网文AI多语种翻译等方面均有实践和落地。在大模型加持下,海外翻译成本下降90%,效率提升近百倍,更多小语种市场获得了增长机会,中国网文“一键出海”、“全球追更”已成为可能。在此过程中,阅文也创新重塑了业务与模型优化深度融合的协作流程,进一步实现了大模型的迭代优化。
瑞金医院-上海市数字医学创新中心首席技术官黄飞跃介绍,基于瑞金医院高品质的医学数据,团队构建了面向惠民和助医的医学大模型群。去年发布了瑞金医学大模型,推出体检报告生成和电子病历生成系统,并在瑞金院内应用。以体检报告生成为例,平均每5秒即可自动生成一份总检报告,为医生节约50%+的撰写时间。
今年,瑞金医院进一步发布了瑞金AI医生。基于瑞金医院深厚的医学沉淀,AI医生能够实现“见多识广、望闻问切”,一方面,AI医生学习了丰富多样的疾病案例和领域专业知识,成为一个专精特全的医学专家;另一方面,通过多模态交互方式,AI医生可以直接在线上使用,实现望体征、闻声音、问病情、切病因,真正成为用户身边的健康助手。
开源全球最大个甲骨文多模态数据集,助力甲骨文研究
在当天的论坛上,“数字甲骨共创中心”宣布将全球最大的甲骨文多模态数据集正式开源。该数据集包含一万片甲骨的拓片、摹本,以及甲骨单字对应位置、对应字头、对应隶定字以及辞例分组、释读顺序等数据。基于该数据集,研究人员可开发甲骨文检测、识别、摹本生成、字形匹配以及释读等方向的智能算法,助推甲骨文研究加速数字化和智能化。
据介绍,数字甲骨共创中心由安阳师范学院甲骨文信息处理教育部实验室、腾讯SSV数字文化实验室、腾讯优图实验室、中国社会科学院甲骨学殷商史研究中心、中国社会科学院考古研究所安阳工作站、厦门大学多媒体可信感知与高效计算教育部重点实验室、郑州大学汉字文明研究中心等单位共同发起建立,吸纳了来自中国社会科学院古代史研究所、复旦大学、英国剑桥大学、法国高等研究实践学院、日本立命馆大学、美国罗格斯大学、加州大学洛杉矶分校等高校和研究机构的专业科研力量支持。
此次开源的甲骨文多模态数据集集合了甲骨文数字化研究的最新成果。一方面,该数据集吸收了当前业界最先进的甲骨文研究资料,包括剑桥大学博士秦培超发布的镜元甲骨文字库,该字库考虑了人工智能标注需求的字库进行了细粒度的异体字标识;以及清华大学黄天树教授发布的《摹本大系》,得益于其具有大量甲骨片清晰字形,降低了标注的难度。
另一方面,AI相关技术的应用也为数据集的信息丰富提供了支撑。比如由腾讯优图实验室联合安阳团队开发的甲骨字检测模型,可以对甲骨片上的字进行一个初步的标注;字形降噪与匹配模型,为检索提供了最直接的方法;甲骨校重算法,可以实现拓片与大系摹本的配准,使得大系摹本可以直接辅助拓片的标注;同时双方联合打造的协同创新平台,也大大提升了数据标注的效率。
腾讯数字文化实验室负责人舒展在分享中介绍,守护中华文脉,焕活汉字源头。用人工智能助力甲骨文“破译”和活化利用,我们一直在探索,将“甲骨文AI破译”纳入探元计划支持的创新探索型项目的定向命题。联合数字甲骨共创中心发布甲骨文AI破译需求,揭榜挂帅,期待与有技术储备、有意愿共创、致力于AI助力甲骨文破译的科研机构形成解决方案。经过遴选评审的共创伙伴将获得资助,共创甲骨文AI考释破译的新算法、新工具、新方法。
近年来,腾讯持续探索数字科技与文化深度融合,运用前沿数字科技帮助文化遗产保护传承,发起并推动了AI助力甲骨文研究、三星堆文物修复、国博数字人等多个项目,用数字技术推动文化遗产焕活。
AI也在持续助力天文探索。2021年,腾讯联合国家天文台,发起了“探星计划”,基于优图实验室的计算机视觉技术,用AI+云提高探星效率,辅助快速射电暴和近密双星系统中脉冲星搜索。
快速射电暴是目前天文界研究热点,相比脉冲星,快速射电暴因发现时间晚、AI训练数据少、出现频率低,发现难度相比脉冲星要大很多。为此,优图团队通过设计全新的端到端AI算法,引入多示例学习和大模型注意力机制,显著提升了模型精度和数据处理速度。
截至目前,“探星计划”从巡天观测数据中发现了3颗快速射电暴、41颗脉冲星。
2024大模型十大趋势,走入“机器外脑”时代
会上,腾讯研究院联合上海交通大学、腾讯优图实验室、腾讯云智能发布了《2024年AI大模型十大趋势》报告。报告指出,人工智能正在迅速发展,大模型技术正成为赋能各行各业的关键。从算力底座、智力增强到人机协作,大模型正在重塑人类社会,成为人类可依赖的“外脑”。
十大趋势包括算力底座、推理分析、创意生成、情绪智能、智能制造、游戏环境、移动革新、具身智能、开源共享、人机对齐等层面。
具体来说,算力底座的量变和提效为大模型行业的发展提供了算力的保障。海量GPU和新一代大模型的组合,使人工智能在三个方向上有了实质性的飞跃:推理分析、创意生成和情绪智能。这意味着AI第一次拥有了类人的交互能能力,新一代AI正在成为人类的“机器外脑”,提供智力的外挂。
随着大模型与人机协作的深入,个体创作的门槛进一步降低,越来越多的个体借助大模型外脑成为“斜杠青年”、“超级生产者”,甚至开启自己的“一人企业”。端侧模型的优化将大幅提升提升移动设备的体验,为大模型带来了新的应用入口。在工业领域,多模态通用感知技术正在提升生产力,而游戏与大模型的共生关系为Agent训练提供了新的舞台。开源模型的成熟,为技术共享与创新提供了强大的生态支持。最后,人机对齐成为确保大模型安全与治理的核心议题,指引着人类走向一个更加智能、高效和伦理的未来。
本文来自投稿,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/model/120561.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫