


来源 | 伯虎财经(bohuFN)
作者 | 楷楷

在近日举办的2024年云栖大会上,阿里再次成为了焦点。
今年5月,阿里云宣布旗下通义千问的多款商业化及开源模型进行大幅降价,最高降价幅度高达97%;云栖大会上,通义千问三款主力模型再次大幅降价,最高降幅达85%。
自阿里在5月率先“开卷”之后,字节跳动旗下云服务火山引擎、百度智能云、腾讯云、科大讯飞等均官宣旗下大模型大幅下调价格,行业降价幅度达到了90%左右。
不仅国内大模型厂商跟进价格战,行业风向标 OpenAI 也在今年7月推出了GPT-4o mini ,商用价格较GPT-3.5 Turbo 便宜了60% 以上。
可以预见,在阿里再掀“价格战”之后,大模型价格还将继续下调,甚至可能走向“负毛利”。在互联网行业的发展史中,“亏本换规模”并不是某个企业的孤例,要改变整个行业的商业模式,必然需要投入更高的成本。
但在这个过程中,如何平衡价格、质量与服务也成为了大模型企业必须思考的问题,企业想要“活下来”,就不能只吃“低垂的果实”。
01 规模比利润更重要
国内大模型已从“以分计价”的定价模式走向“以厘计价”的新时代。今年5月,阿里通义千问大模型的API调用输出价格,从0.02元/千Tokens降至0.0005元/千Tokens。
在9月再次降价之后,阿里云Qwen-Turbo(128k)、Qwen-Plus(128k)、Qwen-Max 三款模型每千 tokens的最低调用价格再次刷新下限,分别降至0.0003元、0.0008元、0.02元。
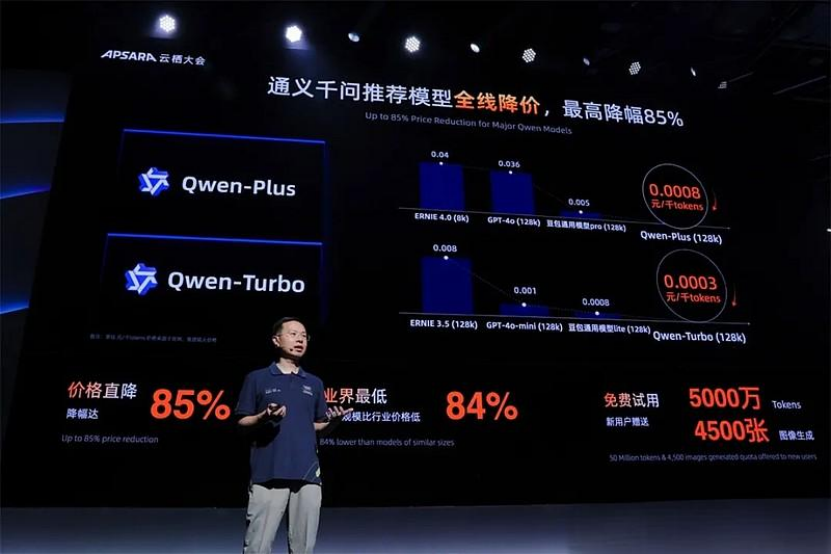
对于再次降价,阿里云CTO周靖人表示,每一次降价都是一个非常严肃的过程,要从整个产业发展,开发者、企业用户的反馈等各方面进行权衡,(降价)不是“价格战”,(大模型价格)还是太贵了。
随着一个行业的成熟发展,其走向降价趋势也是必然的,比如半导体行业的“摩尔定律”,即处理器的性能大约每两年翻一倍,但工艺的进步会使成本下降为之前的一半。
但目前来看,大模型行业的降价速度已经远超“摩尔定律”,降价幅度接近100%,在这样的背景下,大模型企业还能盈利吗?或许对大模型行业来说,当前规模比利润更重要。
一方面,暂时让渡利润已是大模型行业的共识,业内人士认为,大模型行业甚至可能已经到了“负毛利时代”。
据《财经》杂志报道,阿里云、百度智能云等多位负责人曾透露,今年5月以前,国内大模型推理算力毛利率高于60%,和国际同行基本一致,但在5月接连降价后,毛利率则跌至负数。
在大模型降价以后,使用者数量会持续增多,短期内调用次数越多,大模型的亏损就越大,因为每次调用模型都要消耗价格不菲的算力,也就是说大模型企业不仅要降低售价,还要面临更高的成本投入。
但另一方面,大模型降价带来的效果也是显著的。以阿里云为例,在大模型降价以后,阿里云百炼平台的付费客户数比上一个季度增长了超过200%,更多企业放弃私有化部署,选择在百炼上调用各类AI大模型,目前百炼已服务超30万个客户。
过去一年,百度文心大模型的降价幅度也超过90%,不过,百度在2024年Q2财报电话会上披露,文心大模型日均调用量超6亿次,半年内增长超10倍。
如此看来,大模型企业宁愿牺牲利润也要降价,所求的正是“预期”,即牺牲短期利益来换取长期回报。
有业内人士估计,目前各家大模型企业在模型调用领域的收入不会超过10亿元,相较于百亿元级别的总营收,这笔收入只是“九牛一毛”。
但在未来1-2年,大模型调用次数至少有10倍以上的指数级增长,短期来看,用户规模越大,大模型的算力成本越高;但长期来看,在云服务领域,算力成本有望随着客户需求增长逐渐摊薄,企业将会迎来“回报期”。
随着行业的持续发展,AI对算力的拉动会越来越明显,阿里CEO吴泳铭曾表示,在算力市场上,超过50%的新需求都是由AI驱动产生的,大模型正在加速商业化。
一方面,降价大大降低了企业客户的使用门槛和试错成本,特别是对政务、制造、能源等传统行业来说,它们的业务规模更大,增量空间也更大。
当大模型能够像其他基础设施一样人人可用时,大模型的市场空间才能有望实现大幅增长,在这之前,大模型企业难免需要让利给企业和开发者。
另一方面,大模型降价后存量收入会下降,但增量收入会增长。以百度为例,大模型不仅带来了直接收入,比如文心大模型等产品的调用等,还能带动间接业务的收入,比如百度智能云业务。
过去几年,外界对百度智能云战略不乏质疑,其在公有云市场并不占优势,但在AI公有云这个细分市场,百度开始弯道超车。目前,百度智能云的大模型收入占比已从2023年四季度的4.8%提升到了2024年二季度的9%。
所以,目前大模型行业的共识,就是规模比利润更重要,这一观点在互联网时代也是老生常谈,比如“千团大战”“网约车大战”“电商大战”等。大模型企业不能回避“价格战”,就只能将活过价格战作为初步目标,希望能成为淘汰赛结束后的最终受益者。
02 阿里着力“AI大基建”
阿里也深知这一道理,其在近日宣布大模型再次降价后,也提出了“AI大基建”的概念。阿里云副总裁张启表示,现在的AI相当于1996年前后的互联网,当时的上网资费很贵,这也限制了移动互联网的发展,只有把资费降下来,才有可能谈未来的应用爆发。
所以,阿里除了在2024年云栖大会上提出大模型再次降价之外,还发布了新一代的开源大模型,一口气上架了100 多个模型,涵盖多个尺寸的大语言模型、多模态模型、数学模型和代码模型,创造了大模型开源的“数量之最”。

阿里云CTO周靖人表示,阿里云坚定不移地推进开源战略,希望把选择留给开发者,让开发者会基于自己的业务场景去做模型能力增强和推理效率增强的权衡与选择,同时也能更有效服务企业。
根据阿里的统计,截至 2024 年 9 月中旬,通义千问开源模型下载量突破 4000 万,Qwen 系列衍生模型总数超过 5 万个,成为仅次于 Llama 的世界级模型群,而Llama正是大模型开源界的“头把交椅”,全球下载量接近3.5亿。
在“百模大战”结束之后,多位行业大佬均认为“卷模型不如卷应用”,大厂也开始聚焦“卷生态”。百度董事长李彦宏曾表示,“没有构建于基础模型之上的、丰富的AI原生应用生态,大模型就一文不值。”
目前,通过国家网信办备案的大模型已达190多个,注册用户超6亿,但仍难以解决大模型“最后一公里”问题,难点不仅是大模型应用太少,还有大模型不够“接地气”,比如在医疗、金融等专业领域中,单纯依靠“喂数据”训练,大模型还是很难直接落地应用。
大厂不可能躬身入局每一个细分行业来完成“最后一公里”,但可以通过打造完整的应用生态,由下游企业或其他开发者自行“炼成”符合需求的模型产品,不仅能进一步优化资源配置,也能在这个过程中积累更多高质量数据,最终反哺给基础大模型开发。
阿里选择降价、开源,本质就是希望降低大模型的使用门槛,通过更低的价格来验证大模型的应用价值,让更多企业和创作者参与进来。只有大模型能够真正满足企业的复杂业务场景需求,生态才能发展起来,行业才能进入新的阶段。
不过,“百模大战”最终可能只会留下3-5家大模型企业,目前来看,行业第一梯队已经呼之欲出,它们也可能会是大模型行业未来最基本的底座。
因此,头部的大模型企业更不可能主动放弃价格战,让出自己的市场份额。除此以外,不少独角兽也希望凭借价格战杀出一条“生路”,部分企业也认为小模型或更具性价比。
事实上,今年5月的大模型价格战并非始于阿里,而是一条名为“DeepSeek V2”的鲶鱼,在行业普遍推理价格还是百元/Tokens的背景下,其将支持32k上下文的模型API定价为1元/百万Tokens(计算)、2元/百万Tokens(推理)。
目前来看,大模型淘汰赛或还会持续2-3年,虽然最终留下的大模型企业并不会多,为了活下去,企业们也不得不使出浑身解数,但问题是,当“低垂的果实”都被摘完之后,当下大模型行业的解题思路早已不是“便宜就完事”。
03 0模型能力仍是关键
不过,对于大模型“价格战”一事,行业也有不同的看法。零一万物创始人李开复曾表示,没有必要打疯狂的价格战,因为大模型不光要看价格,还要看技术,如果是技术不行,然后靠赔钱来做生意,(公司)不会对标这样的定价。
火山引擎总裁谭待在谈及价格战时也表示,当前主要关注的是应用覆盖,而不是收入,要有更强的模型能力才能解锁新场景,这才更有价值。
目前来看,“价格战”的本质还是因为产品能力不足,各家模型能力趋于同质化,暂时无法形成断档的差距,所以才希望通过价格战来增加大模型的普及,也能帮助厂商增加市场份额。
但等到市场摘完“低垂的果实”,新问题也会接踵而来,企业能否扛下下一阶段的价格战;大模型能否和对手拉开差距;自己会否成为最终能够留下来的企业,这些问题依然需要解决。
所以,大模型企业在打价格战的同时,也深知产品、技术、现金流的重要性,既要抗住降价压力,又要和对手拉开技术差距,持续提升模型性能和产品落地,才能形成良性的商业闭环。
一方面,大模型企业并非单纯依赖“价格战”。通常来说,大模型的推理包含时间、价格、生成 Token 数量三个变量,不能抛开单位时间内的并发数量,只看 tokens 价格。
因为在实际跑业务的过程中,推理事件越复杂,越有可能要增加并发量。但目前降价大模型普遍使用的是预置模型(不支持增加并发量),真正大规模、高性能、支持高并发的模型推理均未有大幅降价。
另一方面,通过技术来进一步优化大模型的推理成本。以百度为例,旗下的百舸异构计算平台对智算集群的设计、调度、容错等环节进行了专项优化,能够实现万卡集群上的模型有效训练时长占比超过98.8%,线性加速比、带宽有效性分别高达95%,帮助客户解决算力短缺和算力成本偏高等问题。
微软CEO萨蒂亚·纳德拉曾举例表示,过去一年 GPT-4 性能提升了6倍,但成本降低到了之前的1/12,性能/成本提升了70倍。不难看出,大模型技术的发展才是行业持续降价的底气。
最后,则是打造出更有差异化的产品。低价策略能够帮助大模型企业筑造生态,但随着AI领域的不断发展,创新速度的加快也使得技术更新换代周期缩短,是否能够持续提供有竞争力的产品,能否在实际应用中解决用户痛点,才是大模型企业的核心竞争力。
目前,大模型行业的商业逻辑,已经从卷模式、卷成本,迈入到卷生态、卷技术的新阶段。当然,低价还是快速建立生态壁垒的重要手段,但通过技术降低成本,才是推动大模型快进到“价值创造阶段”的关键要素。
接下来,大模型企业的新战场将会是“性价比”,要在当前的价格基础上,进一步提高大模型的质量和性能,让模型能力更强、更多元,这么做或许不一定能孵化出“超级应用”,但吸引更多中小企业、创业公司的加入,才有机会为大模型企业带来爆发式增长的机会。
文章封面首图及配图,版权归版权所有人所有。若版权者认为其作品不宜供大家浏览或不应无偿使用,请及时联系我们,本平台将立即更正。
本文来自投稿,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/model/124425.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫