
俗话说得好,AB测试搞得好,产品优化没烦恼!这不,猫哥特地复盘了工作中的实战经验,梳理了AB-Test的全流程秘籍, 今儿分享给大家。
AB测试来源
越来越多的公司重视AB测试,按照猫哥的经验,之前会Excel就行,SQL是加分项。后来变成了必须懂SQL,AB测试是加分项。再到后来变成了,AB测试和SQL都是必会的东西。
因为从15年至今,人口红利肉眼可见的减少,流量竞争从增量竞争变成了存量竞争。截至2020年底,互联网用户已经高达10亿。微信,支付宝,头条,抖音这些巨型APP基本已经瓜分了用户的大部分时间,别的APP想要存活及增长,精细化运营就变成了必须。
精细化从技术上,又无法避免AB测试。往往产品的认知并不是用户的认知,所以我们需要去测试,去实验用户的喜好。选择一个用户偏爱的功能上线,才会不断提高用户满意度,我们的APP才能活下来,并有一定程度的增长。
AB测试是借鉴了实验的思维,目标是为了归因。通俗来说,就是我们想把条件分开,明确的知道,哪种条件下,用户会买账。这就需要三个条件:有对照组,随机分配用户,且用户量足够。
最早的AB测试本身是起源于医学。当一个药剂被研发后,医学工作人员需要评估药剂的效果。一般就会选择两组用户(随机筛选的用户),构建实验组和对照组。用这两组用户来“试药”。也就是实验组用户给真的药剂,对照组用户给安慰剂,但是用户本身不知道自己是什么组,只有医生指导。之后,在后期的观察中,通过一些统计方法,验证效果的差异性是否显著,从而去校验药剂是否达到我们的预期效果。
这个就是最早期的医学“双盲实验”。互联网行业其实也差不多是这么用。我们需要确认的是,当前改版,是否有效果,也就是说,我们需要验证效果的“药剂”变成了一个“改版”。
业务把将web或者app界面或者流程,拆分为多个版本。然后将流量分层(或者分流),不同的人群使用的某个功能或者触发的策略不同。但是这里的人群一定要满足同质化的特性。所以无论分层还是分流,我们都需要将用户随机分配,且同一用户不能处在两个组内。
通俗来说,AB测试是一种互联网人口红利减少的背景下,为了提高用户满意度,留下用户而使用的一种利用数学原理来精细化运营的评估方法。
从本质上来说,AB-Test是对某唯一变化的有效性进行测试的实验
AB测试适用场景
当然,AB测试也不是每种迭代或者改版都能用。一般来说,三种场景可以使用AB测试,三种场景不能使用AB测试。
产品迭代可以使用AB测试。比如界面优化,功能增加,流程增加,这些都可以使用AB测试。因为我们是在原有基础上做一定更新迭代,可以直接使用AB测试。
算法优化可以使用AB测试。同理,算法筛选,算法优化这些我们都可以使用AB测试来测试。因为我们也可以通过流量切分构造实验组和对照组来验证效果。
市场营销的部分场景可以使用AB测试。内容的筛选,时间的筛选,人群的筛选,我们也可以使用AB测试来实验验证效果。
但是,当变量不可控,或者样本量比较小不足以支撑AB测试,或者我们的投放是全流量投放。这三种情况是不支持使用AB测试的。
变量不可控,比如我们业务有两个APP,我们想做一个策略,验证是否能够提高用户使用了A产品,再去使用B产品的概率。这种是不支持AB测试的,因为用户关闭一个APP后,非常多的不可控因素。
样本量较小也不支持AB测试,因为从统计学上来说,我们要验证一个数据是否有效,还是需要一定的样本量的。
至于全量投放,比如我们开了一个发布会,换了一个logo,这种全量投放,怎么做AB测试?你可以让用户不来参与发布会还是让用户不看到新logo?!
AB测试原理简介
AB测试最核心的原理,就四个字:假设检验。检验我们提出的假设是否正确。对应到AB测试中,就是检验实验组&对照组,指标是否有显著差异。
既然是假设检验,那么就是先假设,再收集数据,最后根据收集的数据来做检验。
先来说说假设。
假设一般成对出现,分为零假设 和 备选假设。
在AB测试中,零假设是:实验组&对照组 指标相同,无显著差异;备选假设则相反,实验组&对照组 指标不同,有显著差异。
举个例子。我们优化了某算法,想提高页面的点击率。针对这个场景的AB测试,零假设就是 新算法&老算法的页面点击率无明显差异,备选假设是 新算法&老算法的页面点击率有显著差异。
再来说说检验。
一般来说,我们是通过具体的指标属性来找寻相应的检验方法。那么问题来了,指标如何分类呢?
指标可以分为两种类别:
1、绝对值类指标。也就是我们平常直接计算就能得到的,比如DAU,点击次数等。我们的一般都是统计该指标在一段时间内的均值或者汇总值,不存在两个值之间还要相互计算。
2、相对值类指标。与绝对值类指标相反,我们不能直接计算得到。比如某页面的CTR,我们是用 页面点击数 / 页面展现数。我们要计算点击数和展现数,两者相除才能得到该指标。类似的,还有XX转化率,XX点击率,XX购买率一类的。我们做的AB实验,大部分情况下都想提高这类指标。
根据指标我们可以知道,该如何计算最小样本量,以及实验周期,以及对应的检验方法。
AB测试详细流程
我们先看一个图,结合这个实验的流程图,我们一点点来说:


选取指标
在做AB测试之前,我们一定要清楚,我们实验的目标是什么。并落地到具体的几个指标上,这几个指标对于我们度量实验结果,有非常明显的帮助。但是,指标也要分层级,唯一一个核心指标+多个观察指标。
核心指标用来度量我们这次实验的效果,以及计算相应的样本量。观察指标则用来度量,该实验对其他数据的影响(比如对大盘留存的影响,对网络延迟的影响等等)。
建立假设
建立假设就如同上文所说,我们建立了零假设和备选假设,零假设一般是没有效果,备选假设是有效果。
选取实验单位
大家应该都使用用户粒度来作为实验单位,但是总体说来,实验单位一般有3种。我们不用掌握,但是很多情况下面试官会问到,大家可以作为了解。
1、用户粒度:这个是最推荐的,即以一个用户的唯一标识来作为实验样本。好处是符合AB测试的分桶单位唯一性,不会造成一个实验单位处于两个分桶,造成的数据不置信。
2、设备粒度:以一个设备标识为实验单位。相比用户粒度,如果一个用户有两个手机,那么也可能出现一个用户在两个分桶中的情况,所以也会造成数据不置信的情况。
3、行为粒度:以一次行为为实验单位,也就是用户某一次使用该功能,是实验桶,下一次使用可能就被切换为基线桶。会造成大量的用户处于不同的分桶。强烈不推荐这种方式。
计算样本量
样本量计算,我们需要了解一下中心极限定理。具体书面定义和推导过程,大家可以在网上百度一下就好,我们这里就通俗的解释一下。中心极限定理的含义,就是只要样本量足够大,无论是什么指标,无论对应的指标分布是怎样的,样本的均值分布都会趋于正态分布。
基于正态分布,我们才能计算出相应的样本量和做假设检验。具体的样本量计算推导过程,大家如有需要,可以关注后加我微信私聊,这里就放结论。
整体公式如下:

由于指标可以分为将绝对值指标和相对值指标。对应的,我们在计算绝对值指标和相对值指标时,标准差的计算方式也会不同。具体如下:

我们举两个例子说明一下,让大家更有体感。
案例1-相对值指标:
某产品点击率1.5%,波动范围[1.0%,2.0%],优化了该功能后,需要AB测试计算样本量
P:1.5%,p:2.0%(由于波动范围是[1.0%,2.0%],所以至少是2.0%
总样本量 = 16 * (1.5%*(1-1.5%)+2.0%*(1-2.0%))/ (2.0%-1.5%)^2=22000
案例2-绝对值指标:
某产品购买金额标准差是25,优化了该功能后,预估至少有5元的绝对提升,需要AB测试计算样本量
σ=25,Δ=5
总样本量 = 16 * 25*25*2/5*5=800
总样本量,是指我们的实验单位,必须满足这个数量,实验结果中的数据检验才可信。也就是说,我们的实验桶和基线桶之和必须达到这个流量,才能收集数据及检验指标。
流量分割
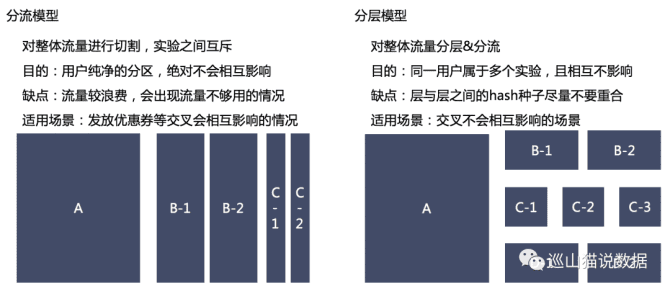
流量切割有两种方式:分流和分层。
分流是指我们直接将整体用户切割为几块,用户只能在一个实验中。但是这种情况很不现实,因为如果我要同时上线多个实验,流量不够切怎么办?那为了达到最小样本量,我们就得延长实验周期,要是做一个实验,要几个月,相信我,你老板一定会和你聊聊人生理想的。
另一种方式,分层。就是将同一批用户,不停的随机后,处于不同的桶。也就是说,一个用户会处于多个实验中,只要实验之间不相互影响,我们就能够无限次的切割用户。这样在保证了每个实验都能用全流量切割的同时,也保证了实验数据是置信的。
两种方式用图来表达如下:
实验周期计算
相应的,最小样本量有了,我们切分了流量,知道了实验桶一天大概能有多少样本量(也可以算小时,如果产品的流量足够大)。我们直接用 最小样本量 / 实验桶天均流量 即可以得到相应的实验周期。
线上验证
很多公司不会做线上验证。当然,不验证也没关系,就是有可能会踩坑,所以还是建议大家在实验上线后进行线上验证。
线上验证主要是2个方向,一个是验证实验策略是否真的触发。即我们上线的实验桶,是否在产品上实际落地了。比如你优化了一个产品功能,你可以去实际体验下,实验桶产品是否真的有优化。
另一个是验证同一个用户只能在同一个桶中,要是同时出现在两个桶中,后期数据也会不置信。这个上文有说过。
数据检验
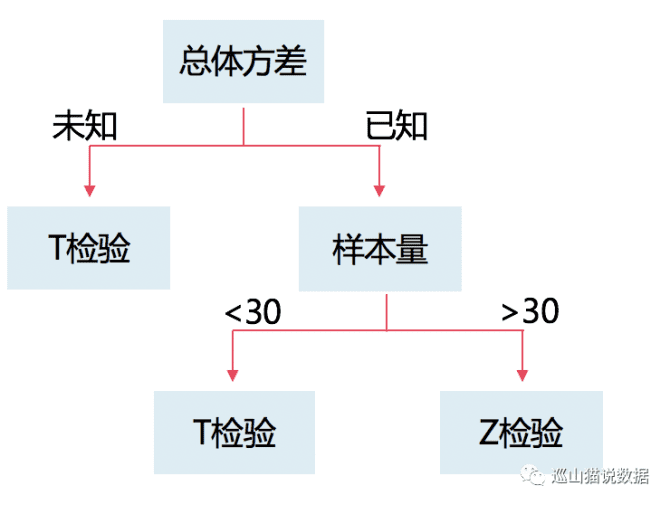
数据检验,大家可能都听过。比如Z检验,T检验,单尾检验,双尾检验,算P值,算置信区间等等。我们这里先说说哪种情况用Z检验,哪种情况用T检验。因为这个问题经常会碰到,也是AB测试中,面试官的必问问题。
大家应该都看过这个图:
贾俊平老师的书中就有这个图,具体的公式和原理书中有非常明细的介绍,关注公众号之后领取的“ 资料 ”中就有这本书的电子版PDF。
按照上文我们说的指标分类,一般情况下,绝对值指标用T检验,相对值指标用Z检验。因为绝对指标的的总体方差,需要知道每一个用户的值,这个在AB实验中肯定不可能。而相对值指标是二项分布,可以通过样本量的值计算出总体的值,就如同10W人的某页面点击率是10%,随机从这10W人中抽样1W人,这个点击率也是10%一样。
再来说说具体的检验。一般情况下我们可以用两种常用方法:
1、算P值,也就是算当零假设成立时,观测到样本数据出现的概率。统计学上,将5%作为一个小概率事件,所以一般用5%来对比计算出来的P值。当P值小于5%时,拒绝零假设,即两组指标不同;反过来,当P值大于5%时,接受零假设,两组指标相同。
2、算置信区间。一般情况下,我们都会用95%来作为置信水平。也就是说,当前数据的估计,有95%的区间包含了总体参数的真值。这么说可能比较绕,我们可以简单理解成 总体数据有95%的可能性在这个范围内。
我们计算两组指标的差异值,如果我们算出的差异值置信区间不含0,我们就拒绝零假设,认为两组指标不同;但是如果包含0,我们则要接受零假设,认为两组指标相同。
当然,我们也可以直接算出Z值或者T值,查表对比。但是这种不是很常用,还是以P值及置信区间为主流。
还有些公司,会将所有指标计算到为不同流量区间内的自然波动。比如我有三个指标,日活100W,那么可以拆分成多个流量区间,比如 1w、2w、5w、10w、20w、50w,100w这几个流量比例,然后依次计算这3个指标,在这些流量下的自然波动阈值,如果高于阈值,我们就认为实验有效。这种就会方便很多,但是不够严谨。
最后来说说单尾检验,双尾检验。单尾检验的前提是我们不仅认为两组指标不同,还明确了大小,一般情况下,我们都认为实验组的效果高于基线组。而双尾检验只是认为两组指标不同,未明确大小。通常来说,我们更推荐使用双尾检验,为什么呢?
因为实验本身就是一种利用数据来做决策的方法,我们不要再人为的带入主观设想。而是用双尾检验,我们不仅能量化涨了多少,还能量化掉了多少,因为实验结果有正有负,不一定都是有效果的(正向的),还可能有负向的效果,我们也可以将有负向效果的实验记录下来,沉淀成知识库,为后期实验避坑。
当然,生活中有些事件是可以用单尾检验的。比如我们优化了制造灯泡的流程,提升了灯泡的质量,那对于灯泡的质量检验我们就采用单尾检验就好,因为我们只关心灯泡质量是否和预期一样,有所提升。
AB测试案例串讲
我们先来按照上节课的流程串讲一个案例。
大体背景如下:
某社交APP增加了“看一看”功能,即用户之间可以查阅到对方所填写的一些基础信息。现在要分析该功能,是否有效果。
我们得到这个问题,需要脑子里想到AB测试的整体流程图(如下)。
从流程图中,我们需要想到几个问题:
1、实验前:如何选指标,如何做假设,如何选实验单位,根据实验指标和单位,如何计算最小样本量,以及实验的周期
2、实验中:需要验证是否所有用户仅处于同一个桶,还需要验证线上实验桶策略是否符合预期
3、实验后:需要回收数据,通过计算P值或者置信区间Diff的方法,校验该功能是否有效
从该功能来说,我们需要考虑的主要指标是用户之间建立联系的率值是否有提升。因为社交是为了让用户之间建立联系,增加这种查阅资料的功能,是为了让用户通过资料查阅,与感兴趣的用户建立联系。
所以该功能,我们的指标选择为加好友率。这时候,零假设就是该功能无效果,即两个桶的加好友率无明显差异。备选假设则相反。实验单位我们为了避免数据的不置信,我们选择以用户为实验单位。
假设我们的原有添加好友率如下 ,那么我们计算整体样本量如下:
P:45%,p:47%(由于波动范围是[44%,46%],所以至少是2.0%)
总样本量 = 16 * (45%*(1-45%)+ 47%*(1-47%))/ (47%-45%)^2 = 19864
由于实验桶和基线桶的比例是1:1,所以我们分配为实验桶1w样本,基线桶1w样本量。但是由于我们不能一上来就全量试验,所以我们开20%的流量为实验桶(假设DAU的20%是2000/天,即实验桶的DAU为2000/天),那么,我们预计要实验5天(1w/2000)。
但是通过计算,用户的一次活跃周期是7天,所以我们为了让实验效果可信度更高,计划实验7天。
实验上线后,我们对线上数据进行了验证,确认了以下两个问题:
1、实验策略在实验桶已生效,在基线桶未生效。即相关的看一看功能在实验桶已上线,基线桶保持原样;
2、同一个用户仅处在同一分桶中,未出现一个用户处于两个桶的情况。
实验到期后,我们对线上数据进行了回收。由于我们这个是相对值指标,所以我们使用Z检验。
检验方法有以下两种:
1、算P值,P值小于5%,拒绝原假设,即产品功能有效果。这个场景中(假设)P=0.002,即我们判断产品有效果。
2、算执行区间的差值,如果不含0,则拒绝零假设。同样,我们这里假设算出来期间不含0,我们认为该产品有效果。
以上,就是一个整体的AB实验案例。我们从筛选指标,到设计实验(选取实验单位,计算最小样本量,计算实验周期),到实验上线,再到后面的效果验证。
但是不知道大家注意没有,这个实验有些地方设计的并不合理。因为社交用户之间会有网络效应,即一个用户会影响另一个用户,所以我们实验分桶这么设计并不合理。
AB测试注意事项
下面,我们就来讲讲AB实验的注意事项。
1、网络效应:
这种情况通常出现在社交网络,以及共享经济场景(如滴滴)。举个例子:如果微信改动了某一个功能,这个功能让实验组用户更加活跃。但是相应的,实验组的用户的好友没有分配到实验组,而是对照组。但是,实验组用户更活跃(比如更频繁的发朋友圈),作为对照组的我们也就会经常去刷朋友圈,那相应的,对照组用户也受到了实验组用户的影响。本质上,对照组用户也就收到了新的功能的影响,那么AB实验就不再能很好的检测出相应的效果。
解决办法:从地理上区隔用户,这种情况适合滴滴这种能够从地理上区隔的产品,比如北京是实验组,上海是对照组,只要两个城市样本量相近即可。或者从用户上直接区隔,比如我们刚刚举的例子,我们按照用户的亲密关系区分为不同的分层,按照用户分层来做实验即可。但是这种方案比较复杂,建议能够从地理上区隔,就从地理上区隔。
2、学习效应:
这种情况就类似,产品做了一个醒目的改版,比如将某个按钮颜色从暗色调成亮色。那相应的,很多用户刚刚看到,会有个新奇心里,去点击该按钮,导致按钮点击率在一段时间内上涨,但是长时间来看,点击率可能又会恢复到原有水平。反之,如果我们将亮色调成暗色,也有可能短时间内点击率下降,长时间内又恢复到原有水平。这就是学习效应。
解决办法:一个是拉长周期来看,我们不要一开始就去观察该指标,而是在一段时间后再去观察指标。通过刚刚的描述大家也知道,新奇效应会随着时间推移而消失。另一种办法是只看新用户,因为新用户不会有学习效应这个问题,毕竟新用户并不知道老版本是什么样子的。
3、多重检验问题:
这个很好理解,就是如果我们在实验中,不断的检验指标是否有差异,会造成我们的结果不可信。也就是说,多次检验同一实验导致第一类错误概率上涨;同时检验多个分组导致第一类错误概率上涨。
举个例子:
出现第一类错误概率:P(A)=5%
检验了20遍:P(至少出现一次第一类错误)
=1-P(20次完全没有第一类错误)
=1- (1−5%) ^20
=64%
也就是说,当我们不断的去检验实验效果时,第一类错误的概率会直线上涨。所以我们在实验结束前,不要多次去观察指标,更不要观察指标有差异后,直接停止实验并下结论说该实验有效。
AB测试面试踩坑
针对这些问题,有很多时候,面试官在问问题时,会设下一些坑,我们来举两个例子。
例1:滴滴准备升级司机端的一个功能,该如何校验功能效果?
考点1:常见的AB测试流程设计
考点2:网络效应
解法:
针对考点1:AB测试的流程是 确定目标 –> 确定实验单位 –> 确定最小样本量 –> 确认流量分割方案 –> 实验上线 –> 规则校验 –> 数据收集 –> 效果检验
针对考点2:实验分桶,以两个量级相近城市分割,避免网络效应的相互影响
例2:某app,用户活跃周期是14天,这时,上线了一个实验,计划跑20天在看效果,结果有位新同学,在10天时做了统计推断,发现数据已经有了显著差异,认为可以停止实验,这样做对吗?
考点1:实验周期应该跨越一个活跃周期
考点2:多重检验问题
解法:
由于AB测试的实验周期尽量跨越一个用户活跃周期,且在实验结束时再做统计推断,所以该做法不对,建议跑慢20天再看数据效果
AB测试小Tips
1、用户属性一定要一致
如果上线一个实验,我们对年轻群体上线,年老群体不上线,实验后拿着效果来对比,即使数据显著性检验通过,那么,实验也是不可信的。因为AB测试的基础条件之一,就是实验用户的同质化。即实验用户群,和非实验用户群的 地域、性别、年龄等自然属性因素分布基本一致。
2、一定要在同一时间维度下做实验
举例:如果某一个招聘app,年前3月份对用户群A做了一个实验,年中7月份对用户群B做了同一个实验,结果7月份的效果明显较差,但是可能本身是由于周期性因素导致的。所以我们在实验时,一定要排除掉季节等因素。
3、AB测试一定要从小流量逐渐放大
如果上线一个功能,直接流量开到50%去做测试,那么如果数据效果不好,或者功能意外出现bug,对线上用户将会造成极大的影响。所以,建议一开始从最小样本量开始实验,然后再逐渐扩大用户群体及实验样本量。
4、如果最小样本量不足该怎么办
如果我们计算出来,样本量需要很大,我们分配的比例已经很大,仍旧存在样本量不足的情况,那么我们只能通过拉长时间周期,通过累计样本量来进行比较
5、是否需要上线第一天就开始看效果?
由于AB-Test,会影响到不同的用户群体,所以,我们在做AB测试时,尽量设定一个测试生效期,这个周期一般是用户的一个活跃间隔期。如招聘用户活跃间隔是7天,那么生效期为7天,如果是一个机酒app,用户活跃间隔是30天,那生效期为30天
6、用户是否生效
用户如果被分组后,未触发实验,我们需要排除这类用户。因为这类用户本身就不是AB该统计进入的用户(这种情况较少,如果有,那在做实验时打上生效标签即可)
7、用户不能同时处于多个组
如果用户同时属于多个组,那么,一个是会对用户造成误导(如每次使用,效果都不一样),一个是会对数据造成影响,我们不能确认及校验实验的效果及准确性
8、如果多个实验同时进行,一定要对用户分层+分组
比如,在推荐算法修改的一个实验中,我们还上线了一个UI优化的实验,那么我们需要将用户划分为4个组:A、老算法+老UI,B、老算法+新UI,C、新算法+老UI,D、新算法+新UI,因为只有这样,我们才能同时进行的两个实验的参与改动的元素,做数据上的评估
9、特殊情况(实际情况)
样本量计算这步,可能在部分公司不会使用,更多的是偏向经验值;
假设检验这一步,部分公司可能也不会使用;
大部分公司,都会有自己的AB平台,产运更偏向于平台上直接测试,最后在一段时间后查看指标差异。
对于这两种情况,我们需要计算不同流量分布下的指标波动数据,把相关自然波动下的阈值作为波动参考,这样能够大概率保证AB实验的严谨及可信度
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/product/53009.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫