
导读:今天分享的主题是“Impala落地与优化:神策数据多维分析平台构建实战”,分为五个部分:
- 神策产品技术架构
- 基于Impala的实时分析引擎
- 查询性能优化
- 查询资源预估
- 未来计划


01
神策产品技术架构
1. 神策数据产品架构
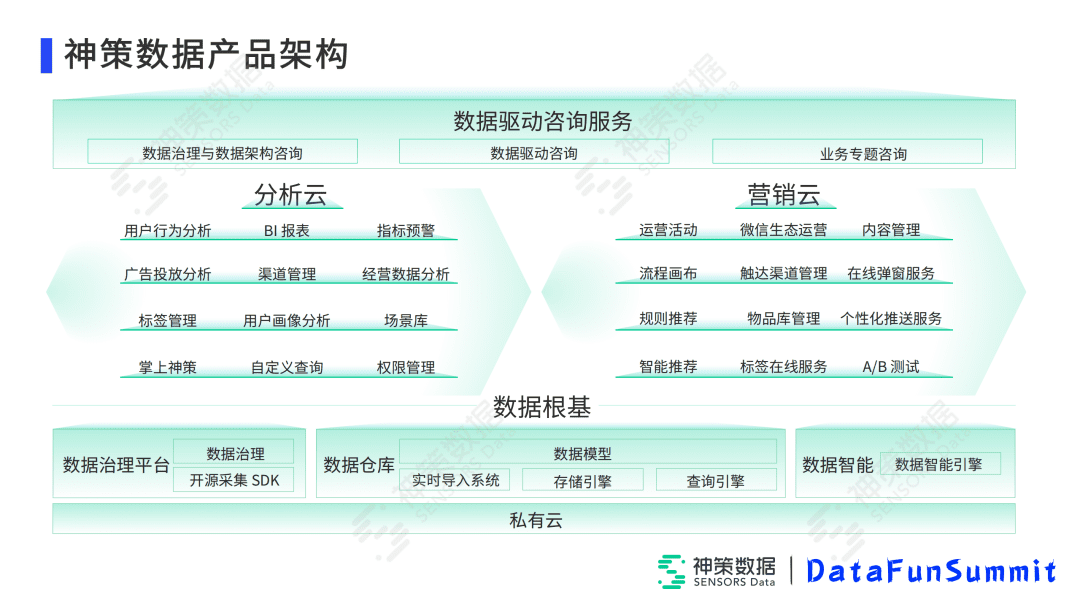
这是整个的产品架构图,分为三个部分,第一部分是数据根基,其次是营销云和分析云。数据根基部分分为采集、传输、治理、存储、查询,以及数据智能几个部分,底层有我们的私有云平台。在分析云部分,除了已经升级了的用户行为分析、指标预警、用户画像等,还有最新研发的广告投放分析以及经营数据分析,我们希望能给用户提供一个完整的分析体验。其次就是营销云,现在已经提供了完整的运营活动、微信生态运营,以及流程画布,我们希望能够打造一个用户体验的产品的数据闭环。我们在上层也会提供一个数据驱动的咨询服务,来帮助用户更好的完善自己的数据分析体验。
2. 神策数据技术架构
接下来介绍一下神策数据技术架构。
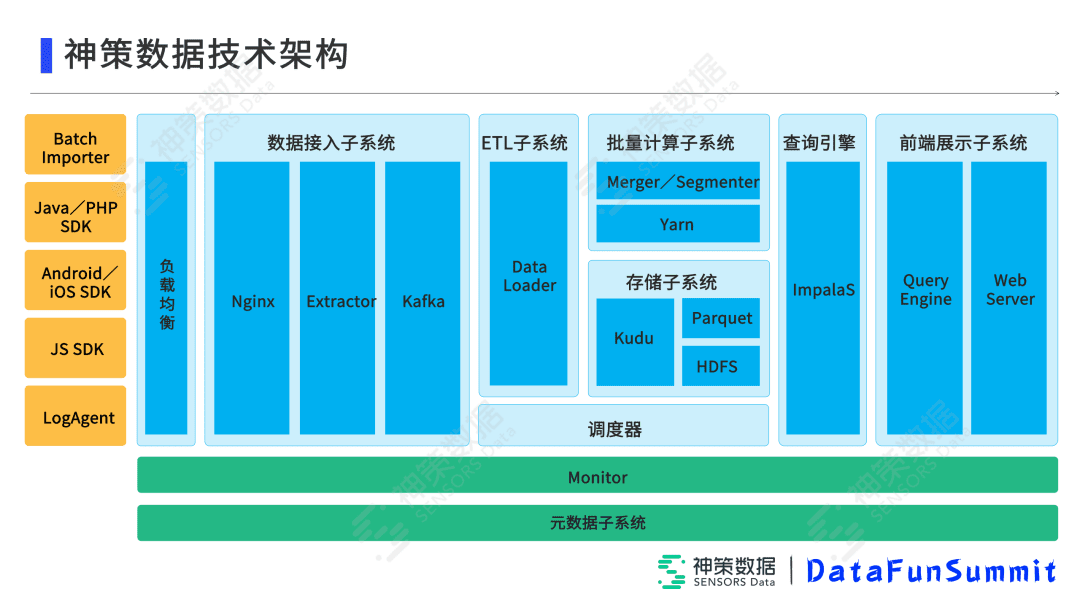
首先最左侧黄色的部分是各个导入的SDK,包括服务端SDK、客户端SDK,以及导入工具比如LogAgent、Batch Importer等。
通过Nginx进入到日志文件接收系统,Extractor会对文件进行解析,包括一些校验、处理、清洗等等,最后生成复合神策协议的规范的文件,进入到Kafka数据系统。
Data Loader是神策数据自研的一个数据接收系统,它会实时订阅Kafka中的数据,将这些数据实时写入到Kudu中,并且在一段时间内有定时子任务将Kudu中数据转存到Parquet文件格式中,保证了实时写入并且利用了列存的优势能够快速的读取。
上层还有Yarn的任务调度系统,它会定时的调度一些Kafka的消费任务,以及预处理的一些任务。
接下来就是基于Impala构建的实时查询引擎,在上层客户会传给Query Engine一个可以解析的Request,查询引擎Query Engine会将它翻译成业务可理解的SQL,查询引擎会给它返回结果,同时在前端展示子系统中也有自己的缓存,保证能够降低Impala的一些压力。另外整个系统底层还有Monitor可以进行监控。
02
基于Impala的实时分析引擎
1. 用户行为需求
随着时间的增大,维度越来越多,并且维度的取值也非常分散,但是我们又希望能够满足客户各种维度下钻的需求,可以看出我们的查询模式是非常多样化的。其次就是我们要能实时响应客户的需求,并且它的查询频率是较低的。所以用户分析构建是将灵活性排在第一位,其次是及时性,最后是时效性。
2. Impala架构特点
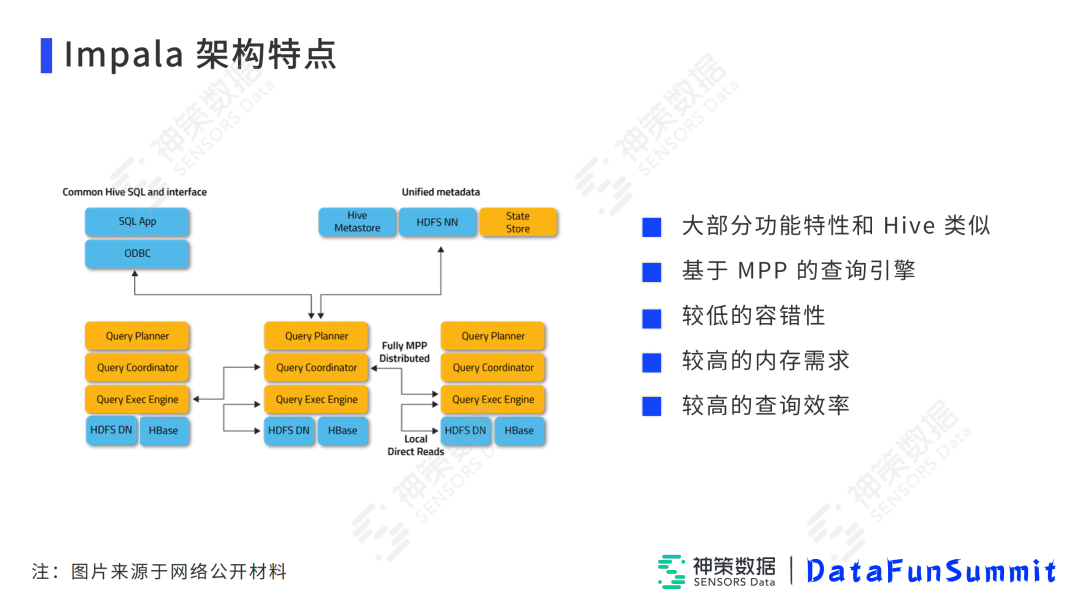
首先Impala是基于MPP查询引擎的,它的计算和存储是在同一台节点上,并且共享自己的内存、磁盘、CPU等,这样每个节点可以方便的进行并行计算。
Impala包含3个进程:StateStore进程、CatalogD进程、ImpalaD进程。StateStore进程主要负责监控集群里各个节点的ImpalaD的健康状态、实时接收ImpalaD进程的注册订阅消息,CatalogD进程通过Hive Metastore去缓存元数据信息,如查询需要用到的表信息、各种属性字段信息,以及每个查询需要用到的Parquet文件地址,将这些数据缓存起来,并且可以通过Statestore将这些缓存的元数据分发给各个Impalad节点,每个Impalad维护一份自己的缓存数据。Impalad又分为两种角色,一种是Coordinator角色负责接收请求以及汇总查询结果反馈给前端,一种是Executor角色负责执行计划。可以看出虽然Impala有较高的内存需求,但是它的查询效率是非常高的,这也是我们选择它的重要原因。针对它较低的容错性和较高的内存需求问题,我们会在后续迭代中进一步完善。
3. 基于Impala的系统架构
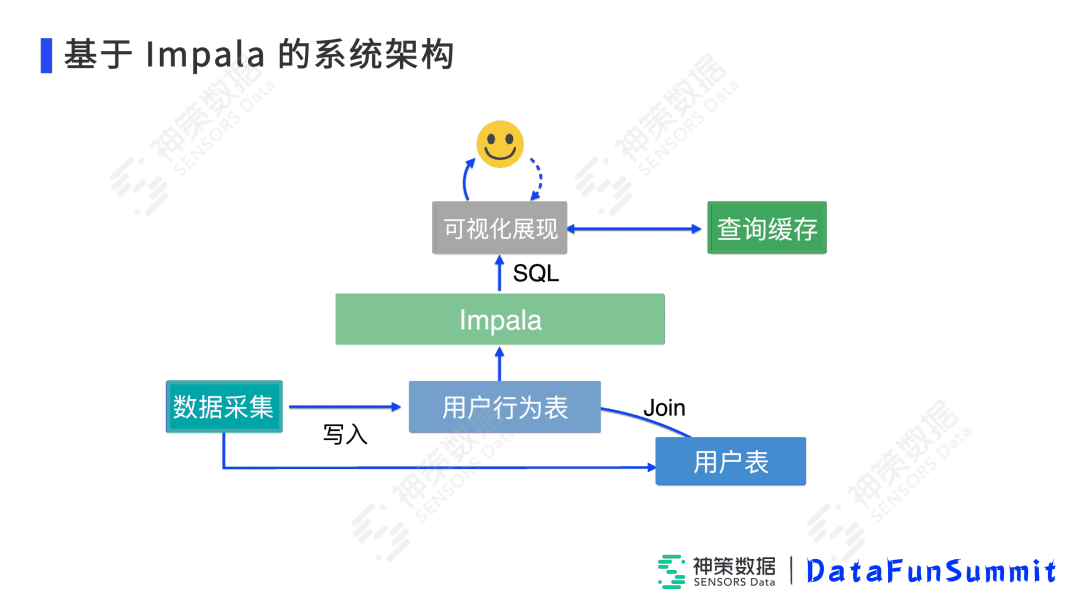
这是基于Impala的系统架构。各种SDK以及导入工具,首先将数据写入Kudu,最终转换成Parquet文件格式中,底层支持用户行为表、用户表,同时也支持客户自己导入的如维度表,以及系统也支持一些Iterm表给用户自己定义。针对上层Impala来说,它的用户行为表是将Kudu和HDFS上的数据Union起来的,所以它不需要再去拷贝数据,它看到的是一张视图。在上层,我们也做了一些查询缓存,来防止Impala有过大的压力。
03
查询性能优化
接下来介绍一下我们的查询优化,包括五个部分,分别是旧存储模式、新存储优化、基于用户行为序列的查询优化、外连接消除优化和预处理表达式优化。其中部分功能已经提交到社区。
1. 旧存储模式
说到查询优化,不得不先说一下存储优化,首先介绍下旧的存储模式。

旧的存储模式是数据按天、按Event进行分区,同时每个区的数据文件大小都有一定的规则,保证最优的扫描效率;其次它的数据是部分有序的。但是现在这个存储也面临着一些问题,针对这里提到的三类场景的优化,没有达到非常好的效果。
- 首先是在复杂分析的场景中,数据是需要按用户以及查询的事件时间是完全有序的,但是因为存储不是全局有序的,后面需要对上亿甚至几十亿条数据做全排序。内存不够的情况下,会落到磁盘上,这样查询就会非常慢。
- 第二点就是有一些事件是高频查询,会经常用到,但是有一些事件可能是客户导入的,并不需要实时查,如两年以前的数据,如果放在HDFS上并不是有非常好的效果。
- 第三点是有一些事件是需要频繁更新的,比如说最近两天的订单状态(已购买、已配送等)是会实时更新的,用HDFS的Parquet格式存,没有办法做到这一点。
2. 新存储优化
针对上面三类场景,我们进行了一些优化。
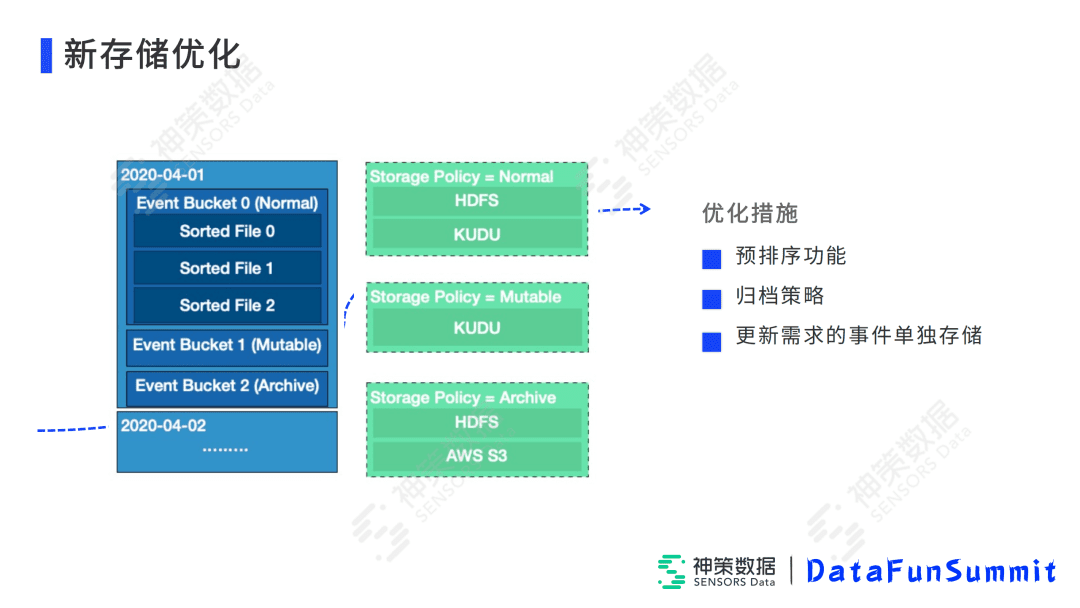
在新的存储模式下,
- 首先,它是按照天、用户ID、时间进行预排序,保证底层存储格式的更进一步的有序性。
- 第二点就是针对一些不需要实时查询的数据,如两年前的数据,我们支持客户自定义的归档策略,把它放到AWS S3这种性价比较高的存储上,帮助客户节约成本。
- 第三点是针对一些需要实时更新的事件,我们可以单独把它存储到Kudu中,可以用户自定义什么时候把它放到HDFS上,更加的有灵活性,支持各种各样的场景。
3. 基于用户行为序列的查询优化
在刚才存储格式进行优化后,我们接下来看如何针对复杂查询也就是基于用户行为序列的查询,怎么进行优化。
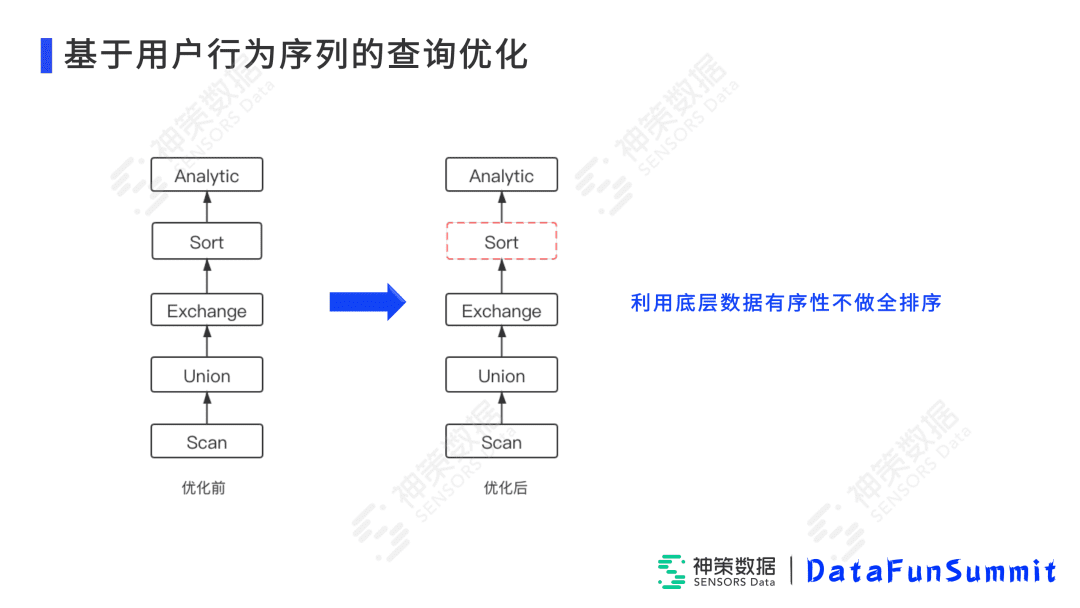
首先看左边的查询计划。首先底层间进行扫描,每个节点扫描出一部分数据,接下来在这个节点上做Union,比如将HDFS或Kudu上的数据进行汇总。汇总后,各个节点会进行1个Exchange,exchange后会将相同用户ID分发到相同的Impalad节点,然后会进行一个全排序,最终再到ETL后算出一个结果。可以看到,这可能会排序几亿甚至几十亿的数据量,这是非常消耗内存资源的,也是非常慢的,是很大的瓶颈。因此,可以利用底层扫描数据的有序性,在上层Exchange里做一个Shuffle exchange,保证给到上层节点的数据都是按用户、按时间排好序的,这样我们就可以干掉sort节点,直接进入UDTF的算子中。可以看出,我们直接对这个查询计划进行了一个优化。
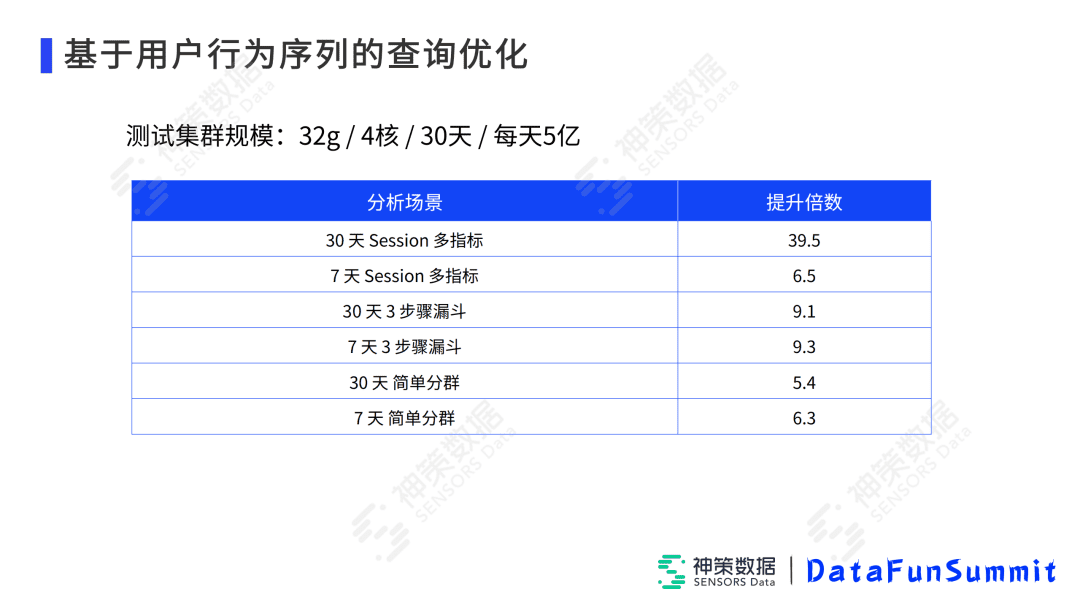
最后我们在这样一个测试集群(规模是10个节点,每个节点32g内存4核CPU,非SSD的磁盘,大概模拟了30天的真实数据,每天约5亿条数据)上对计划进行了分析。可以看出,我们对不同的分析模型不同的天进行了测试,基本上有6倍到40倍的提升,内存会降为之前的1/5。比如7天的3步漏斗,之前大概需要30秒左右,现在基本上能把它变到10秒以内,这个效果还是非常明显的,并且已经推给了客户升级。
4. 外连接消除优化
接下来要讲的是一个已经提交给社区的外连接消除优化。
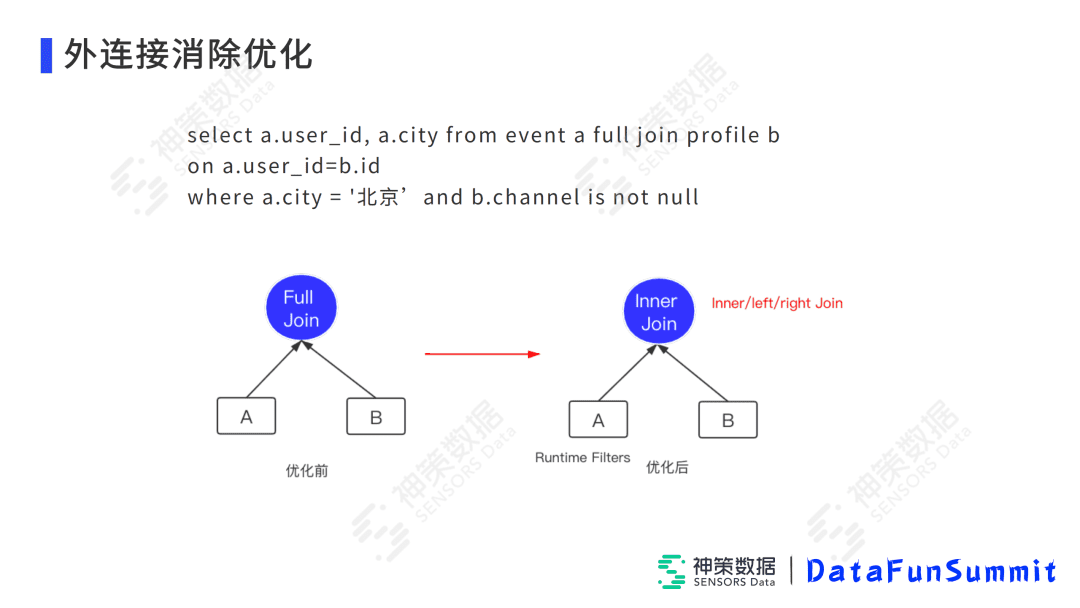
比如针对上图中的SQL,将Event和Profile表连接起来,加了左表和右表的属性过滤,并且属性是非null的。本来是使用Full Join的,但是在这种场景下,可以转换成Inner Join。转成Inner Join后,可以利用它自带的将B表的ID构建1个哈希传递给左表,左表构建一个类似于Runtime Filter的数据结构,这样在Join之后,分发给上层的算子的数据量会大幅度减少。
5. 预处理表达式优化

这个SQL也是从漏斗的SQL中截取的一部分。比如在内层会对一些事件还有属性做过滤得到一个Funnel_step_ID,在上层的聚合中会用到这个ID。通过预处理表达式,复杂的表达式case when是在底层的Scan层去做的,Scan层是多线程的。如果没有做优化,则在上层的union层做表达式计算,效率非常低。
下图展示的是我们的优化:
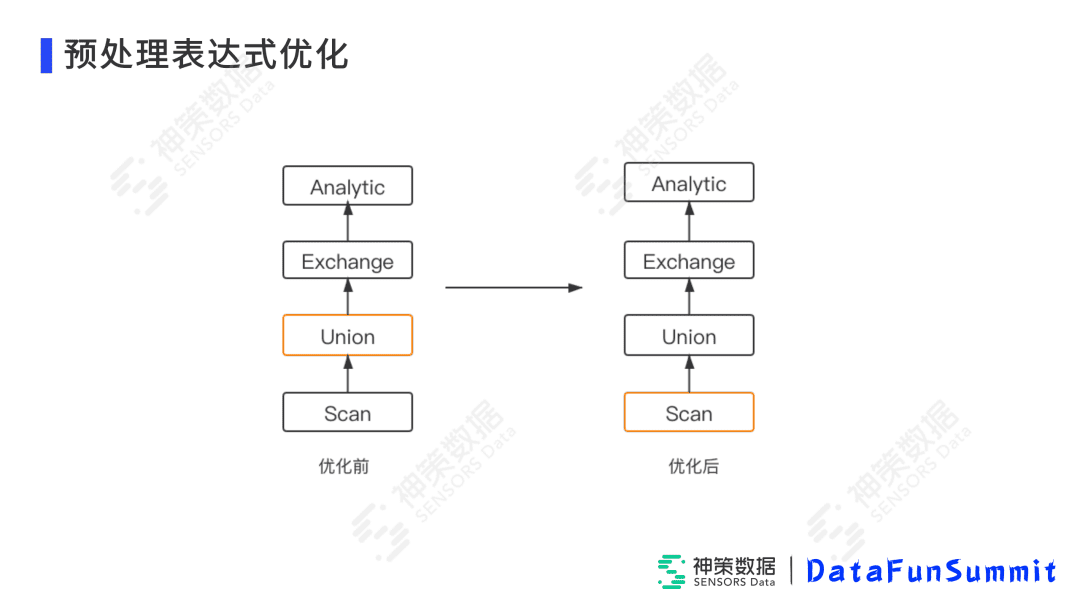
首先,针对漏斗的例子,本来是在Scan层,Scan层上再Union层计算复杂表达式,并且把所有数据全部传递给上层,但是在优化之后,进行下推,把case when或者正则匹配的过滤在Scan层做,这样Union的时候就已经不需要传递多余的属性,直接把最终列的属性传递给上层,这样就可以减少数据发送量。其次,可以利用Scan的多线程的操作模式,大大提升效率。
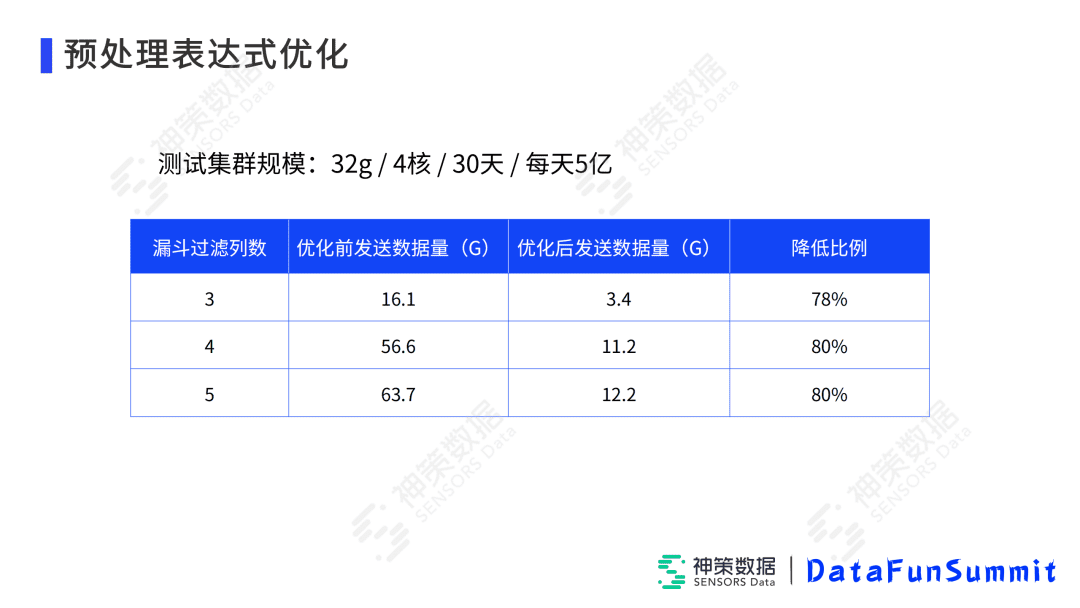
在上面讲的测试集群上进行测试,针对漏斗使用的列数不同,它需要发送的数据量会大幅减少,基本上能减少80%以上。比如漏斗里,需要城市(如北京)、订单金额(如大于200元)、订单状态(如成功)这样3列过滤,本来需要把3列的数据都Scan出来发送到上层,但是优化之后,不需要发送3列,直接算出最终的那一列,数据量减少到3.4G,效果是非常明显的。
04
查询资源预估
1. 现状与解决对策
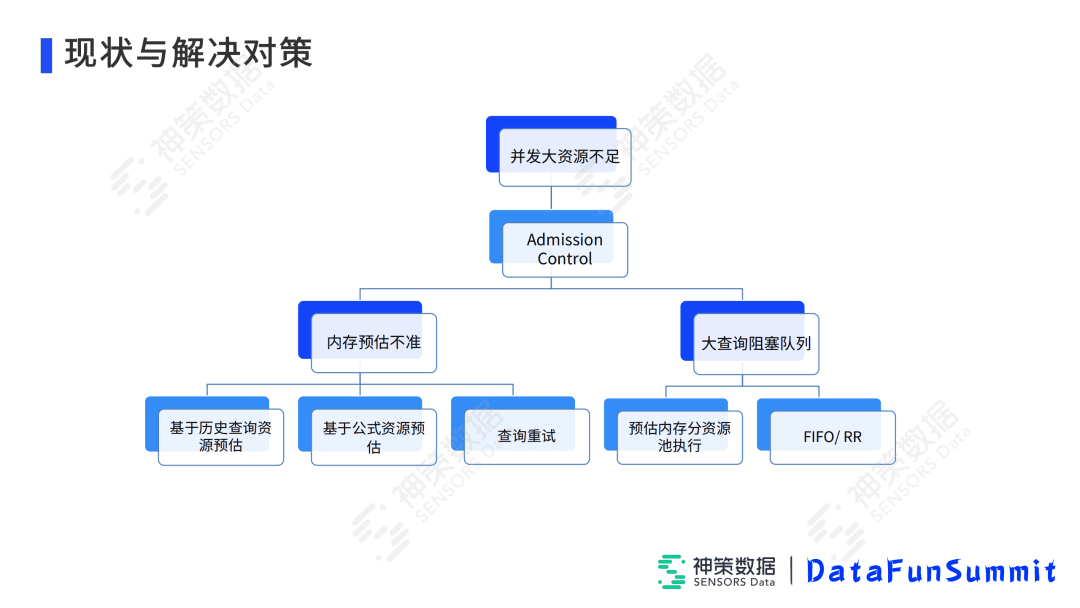
首先我们可以分析一下,平时我们在运维过程中遇到的查询问题。一类主要是查询资源不足,还有一类是查询慢。查询慢主要通过上面提到的性能优化来解决,针对查询资源不足这种错误率较高的情况,原因主要是两类。
一类是资源预估的内存不准。比如预估的内存太小了,而集群上没有那么多资源了,因此查询时会报内存不足;而如果预估的资源太大,并发度又不够。所以如何提高资源内存预估的准确性,是我们减少错误率的重中之重。针对内存预估不准,我们给出了三种解决方案。第一种是基于历史查询资源的预估,首先会将历史的资源根据各个算子生成签名,存到k-v存储系统中,后续有类似查询过来时,根据各个算子、时间条件、过滤条件等,进行一个等比例的放大缩小。另外一种是历史上没有类似的查询,就使用公式资源预估的方式。Impala自己带一个公式预估的方式,但是不是非常准确,偏差比较大。我们主要针对常用的Agg、Join、Sort这三个算子内存进行公式预估的优化,效果还是比较明显。第三种是Impala是没有容错机制的,如果这次查询失败,不会再次进行查询,我们这里是给它一次机会,让它查询失败后重新预估内存,再去试一次。
另外一类是大查询会阻塞小查询,这里主要是分为大小查询队列,保证小查询在一个队列,大查询在另外一个队列。其次我们有改进后的基于时间的调度算法,Impala自带的是先入先出的算法,能够按序去调度查询,我们会保障后继小查询会根据算法能够及时的进行查询。
2. 查询资源预估流程

首先是查询过来后,根据查询计划生成签名。比如针对漏斗有Scan、Union、Exchange、再到上层的UDTF,我们会结合这些算子,以及每个算子中的信息,比如天数、过滤条件、上层的Join条件等等信息,生成签名,然后判断历史否有这样的签名,如果有则根据历史进行等比例的放大缩小去计算内存,如果没有则根据Impala自带的公式预估,进入到查询调度里面。然后用自己实现的调度算法,让它执行,执行成功就会返回结果,并且更新历史上存到k-v库中的签名以及对应的耗时、内存。如果执行失败,会进行重试,再次进入查询调度器让它执行,如果还是失败,则最终失败。这是整个的预估流程。
3. 查询资源预估效果
因为预估的准确性,可以很大程度上决定了错误率降低的效果。这也是我们在刚才的测试集群上,分别对10种不同分析模型、查询时长算出的资源预估的效果。
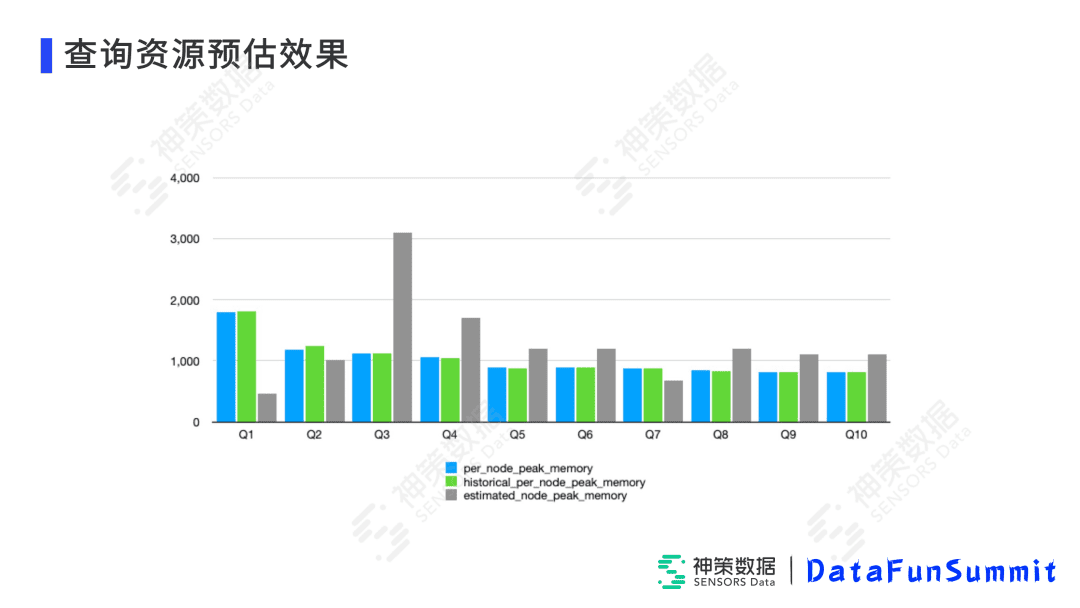
其中蓝色表示每个查询实际需要的内存、绿色是基于历史相似查询预估的内存、灰色是我们根据Impala自带的公式预估进行优化后算出的内存。可以看出,除了极个别灰色差别比较大主要是带Join情况下优化有一定误差,其它情况下我们的历史预估、基于公式预估与实际内存相比较都是非常接近的。这个我们给四五十家客户上线,可以将错误率降低80%以上,效果是非常明显的。
05
未来计划
最后,介绍下我们的未来计划。
首先,上面的一些功能,比如内存优化,以及资源预估,有一部分已经推回社区了,但是还有很大一部分没有推回社区。后面会将这些功能进行拆分推回社区,来提升Impala性能。
另一点,是我们最近也在做的弹性计算和查询可观测性。其中弹性计算是我们集群的动态的缩容扩容,节约客户成本,提升查询体验。查询可观测性是我们最近在做的客户管理自己查询资源的一个系统,希望能够做到客户自己在发现查询慢的时候,可以根据查询可观测性系统,去动态发现一些大查询是否有用动态管理自己的查询资源,以及管理自己的导入资源。
最后,我们会持续做性能优化,保证业界先进水平。
06
精彩问答
Q: 有序漏斗分析如何做?
A: 如果问漏斗怎么做,可是用UDTF做,主要是一些实现逻辑。如果问优化怎么做,主要还是要对底层的数据进行优化,保证scan出来的数据已经是按用户、按时间有序的了,这样各个节点在上层再去做归并,保证一个用户在同1个节点上是完全有序的了,省去一个Sort算子,达到一个优化效果。应该是在各个系统里都比较相似。
Q: /*materialize_expr*/是你们自研的吗?
A: 对,是我们自研的一个hint,后续会把它做成自动识别,而不需要业务端加hint,会把它推回社区。
Q: 具体推回社区的特性有哪些呢?
A: 第一个推回社区的特性是外链接消除,已经分批次推回社区了。第二部分是复杂表达式下推,这个我们也会尽快推回社区。因为社区也会有一些任务,我们也会跟社区合作去做。其次就是有一些优化的,也会拆分出好多点。比如公式预估的准确性优化,已经优化自带的FIFO的调度算法优化,都可以拆出很多点推回社区。
Q: Kudu到HDFS的数据排序,是在Impala里实现的吗?
A: 在导入逻辑里实现的,Impala主要是用这个数据。导入的逻辑是我们自研的Dataloader系统实现的,主要是先把数据写入到Kudu中,其次会定期对Kudu数据进行转Parquet的实现。
今天的分享就到这里,谢谢大家。
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/product/63370.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫