
导读:今天和大家分享一下关于QQ音乐在召回算法中的一些探索和实践。将会从以下五个方面进行介绍:
- 业务介绍
- 融合知识图谱召回
- 序列与多兴趣召回
- 音频召回
- 联邦学习召回


01
业务介绍
1. 业务介绍
在QQ音乐首页有非常丰富的推荐产品,例如:个性电台、每日30首、单曲推荐、UGC歌单推荐和AI歌单等等。
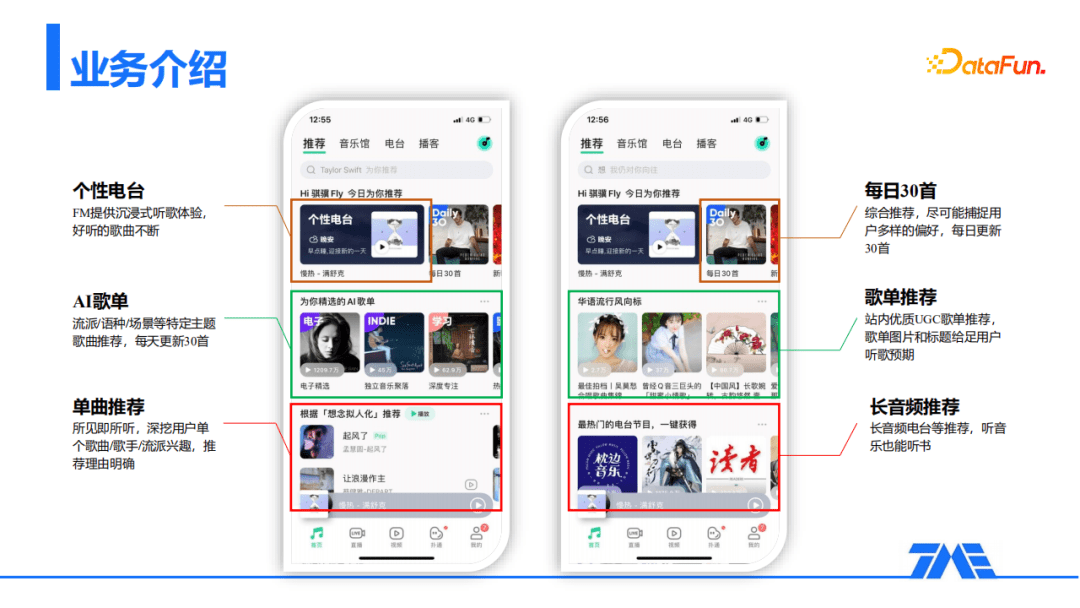
上图中可以看到每一个产品的特点及形态各异。例如:个性电台提供沉浸式听歌体验;AI算法歌单每天更新30首歌曲。这些多种多样的产品形态,对推荐算法和架构都提出了诸多的挑战。不同形态入口的优化目标和样本的构造都不尽相同。
2. QQ音乐推荐场景特点
接下来介绍QQ音乐推荐场景的一些特点。
首先,在用户层面上,平台覆盖群体非常广,消费者老少皆有。

其次,目标群体的固有属性比较稀缺,除去音乐本身的画像,其他属性仅有用户填写的少量人口统计学信息。在行为层面,即用户的互动层面,完播和切歌是主要的操作行为,也有收藏、拉黑、关注以及加入自建歌单等其他操作。
最后,与电商、视频流场景不同的是,音乐的重复消费是音乐推荐场景一大特征。另外,音乐推荐的产品多种多样,不同形态的特点非常鲜明;比如歌曲的音频、歌词、歌手等、UGC歌单的标题和图片等等。
以上这些推荐的场景给召回算法带来如下挑战:
- 用户听歌行为,噪声比较大。样本如果不做精细的处理和筛选,召回准确性不够好。
- 头部热门非常严重,相对来讲,如果不做特定的干预,推荐结果会缺少惊喜感。
- 用户属性稀缺,冷启动相对困难。
3. QQ音乐推荐解决方案
基于上面的三个问题,我们提出了以下解决方案:
- 采用融合音乐知识图谱召回;
- 引入序列与多兴趣召回;
- 挖掘音频召回的方式,为用户召回“听感相似”的歌曲;
- 探索联邦学习的方法,解决用户属性稀缺的困难问题。
接下来详细介绍这几个方案。
02
融合音乐知识图谱召回
首先介绍融合知识图谱的召回,这部分主要是为了提升召回的准确性。
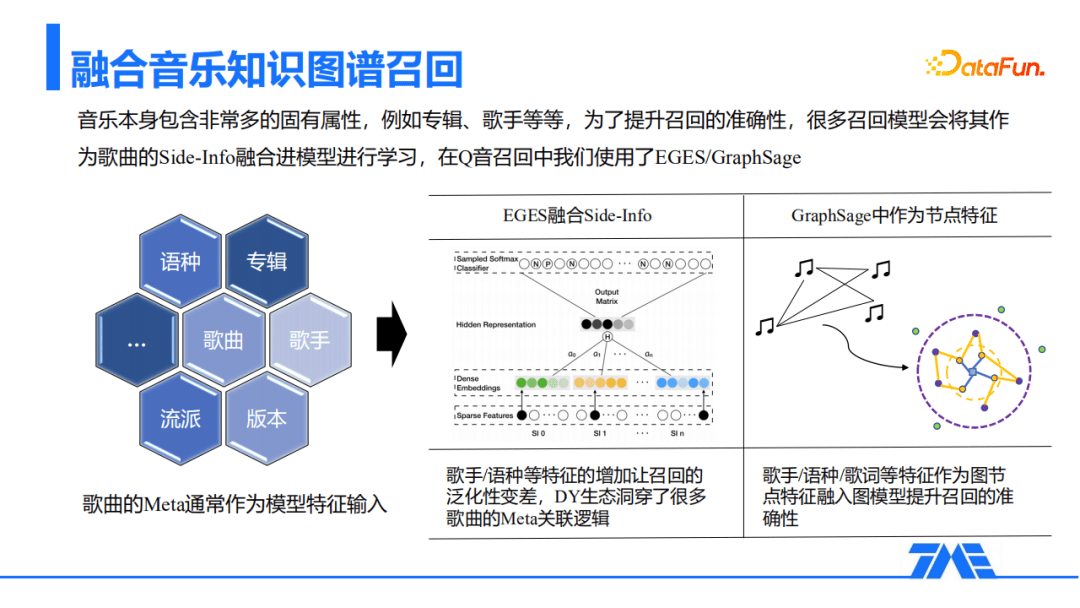
音乐本身包含非常多的基础属性,例如每一首歌几乎都有专辑、歌手、流派和语种等。为了提升召回的准确性,很多召回模型会将这些属性作为歌曲的Side-Info融入到模型进行学习,在QQ音乐的召回中也使用了EGES / GraphSage这类的模型。不过这两类模型也存在不足,例如,EGES模型能融合Meta信息,如前面提到的语种、专辑等,这种特征的增加会使得召回的泛化性有所不足;抖音的生态也会洞穿很多歌曲的Meta关联逻辑。另外,QQ音乐的曲库非常庞大和丰富,利用一些复杂图模型的训练周期相对较长,效率也强依赖与工程能力,所以接下来融合知识图谱的召回,在这两方面做了折中且有不错的效果。
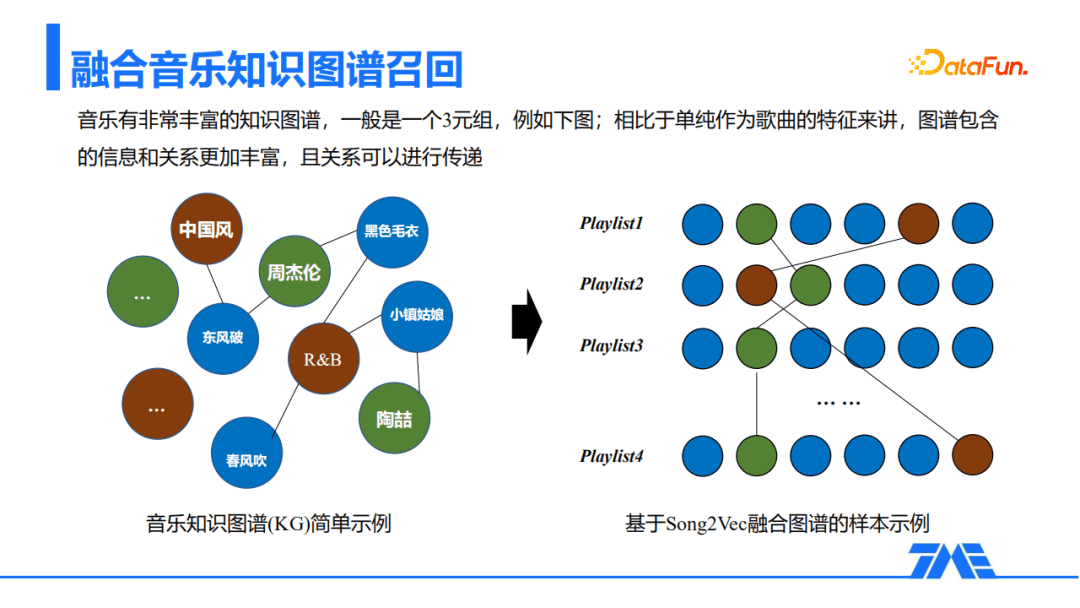
音乐有丰富的知识图谱,一般是三元组。比如周杰伦演唱了东风破,属于中国风的歌曲,相比于单纯作为歌曲的特征来讲,图谱包含的信息和关系更加丰富,且关系可以进行传递。以自建歌单作为训练样本为例,也就是右图中图谱的引入,相当于将在不同歌单共现的歌曲纵向进行了串联。
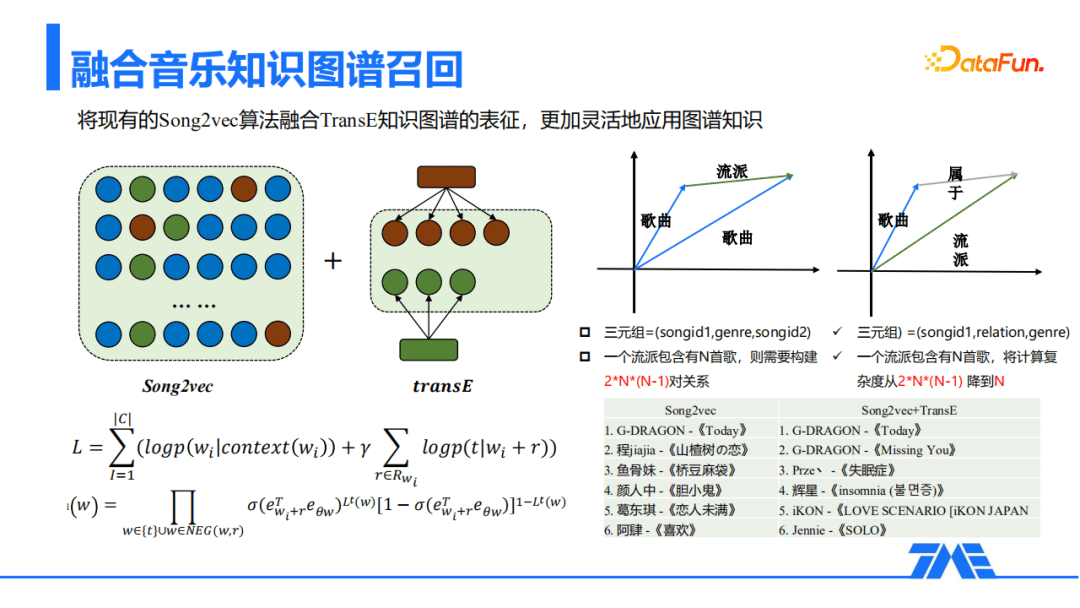
使用Song2vec的方法进行建模,上图中展示了目标函数。可以看到在Song2vec的基础上,添加了关系的学习,其中伽马因子表示当前关系能够融合到模型里面的程度。
三元组的构建有非常多的方法。利用流派的图谱举例,有(songid1,genre(流派),songid2)和(songid1,relation,genre(流派))两种构建方法。前一种是在NLP中常见的构建方式,但在音乐场景里面这种关系是相互的,会以笛卡尔积构建2*N*(N-1)对关系;而后面一种关系的构建更加直接,关系数直接降到了N这个级别。融合知识图谱在召回上准确率有较大提升,BadCase率的改善也非常显著。以权志龙的“Today”为例,左边是仅以Song2vec的方式做关联,会与抖音热门的歌曲有较强的绑定;而右边的Song2vec和TransE的融合,可以让歌曲的关联保证准确性和一定的泛化性。
03
序列与多兴趣召回
序列与多兴趣召回,主要是为了挖掘序列中时间和空间的特性,以及用户的多兴趣表征。
在对样本特征和模型结构做了一些改进后, YouTube模型在召回上有非常不错的推荐效果,该召回通路的歌曲完播率很高,但也存在不少问题。例如:
- 问题一:用户的听歌行为存在一个序列关系,特别是在推荐的场景里面,除了包含位置信息,还包含了行为发生的时间影响,即同时存在时间和空间关系;
- 问题二:对序列进行avg/sum pooling的方式过于粗暴,特别是在用户兴趣较多的情况下,会导致用户的兴趣被中和甚至被抹平。
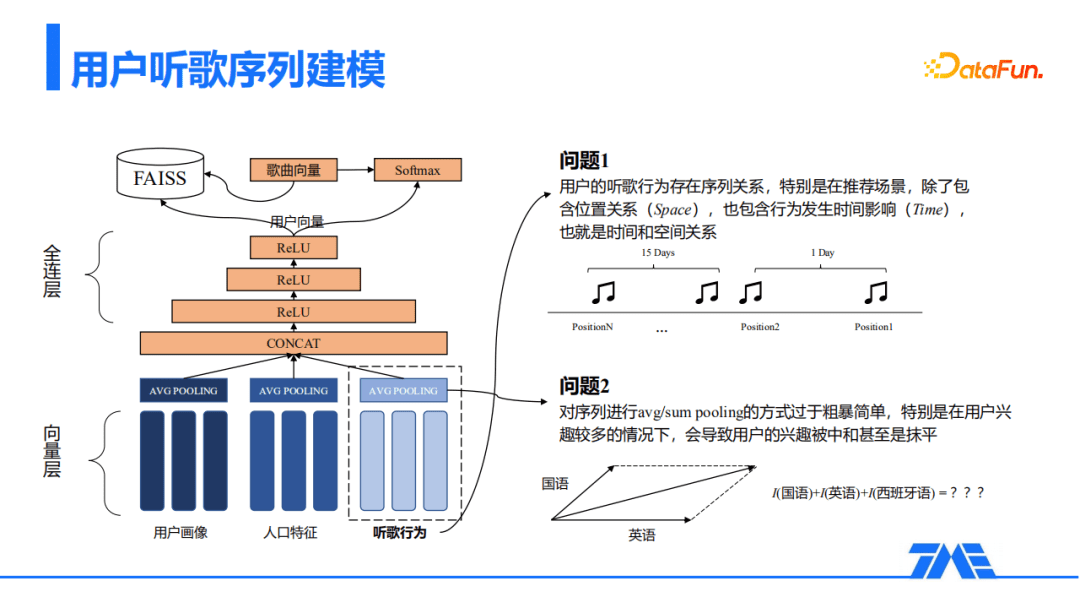
接下来将从序列建模和多兴趣建模分别介绍对上述问题的改进和实践。
1. 空间和时间建模方案
QQ音乐采用SASRec序列建模, 对用户的历史完播行为进行建模,提取更为有价值的信息,且叠加多个自助力机制,能够学习更复杂的特征转换。主要思路是利用户的序列L预测它的目标Target P,self-attention层中V基于QK计算Attention权重加权计算后输入到后续网络,最后使用sampled_softmax_loss做多分类进行预测。除了融合绝对位置和相对时间, 将Item Input和Output sharing Embedding,相对于Youtube模型, HR@100指标有大幅度提升。基于SASRec + Share Embedding,同时融合了时间和位置建模,结果能达到23.72%的准确率,而原始Youtube是21.25%,准确率提升2.5%。

2. 多兴趣提取方案
在QQ音乐场景,80%以上用户听两个以上流派,47%以上用户听两个以上语言歌曲。如何更加精准的挖掘用户听歌序列的多兴趣,甚至小众的听歌兴趣,非常重要。
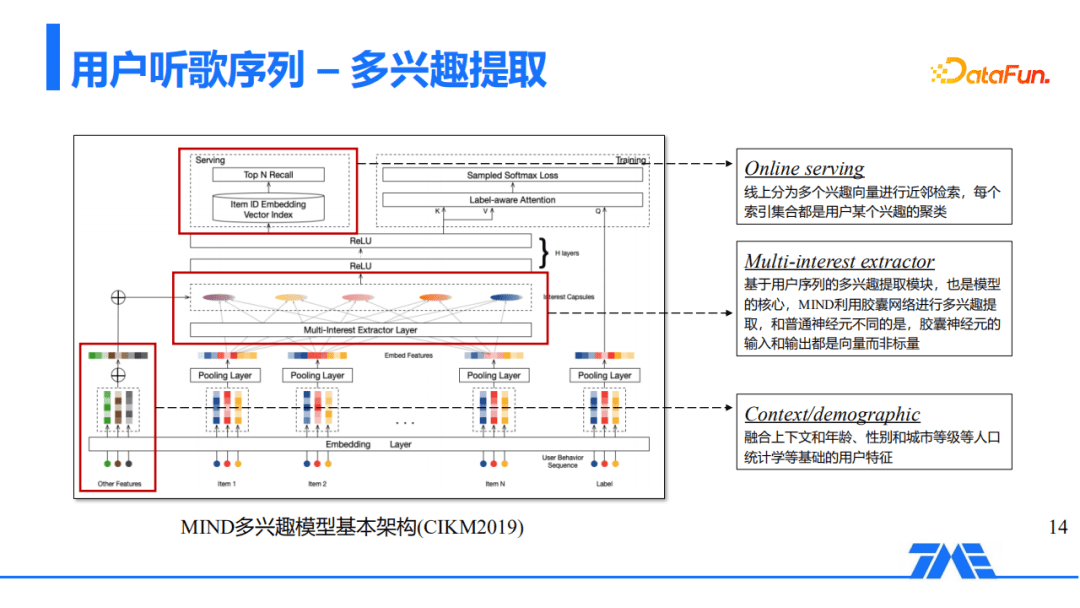
以MIND模型为例,多兴趣模型有几个非常重要的模块,例如:
- 第一部分是Context / demographic是融合上下文信息以及年龄、性别和城市等统计学信息的模块;
- 第二部分是多兴趣提取模块(Multi-interest extractor),基于用户序列的多兴趣提取模块,也是模型的核心,MIND利用胶囊网络进行多兴趣提取,和普通神经元不同的是,胶囊神经元的输入和输出都是向量而非标量;
- 最后一部分是Online Serving模块,线上分为多个兴趣向量进行近邻检索,每个索引集合都是用户某个兴趣的聚类,也就是用不同的User Embedding去线上索引出用户不同的兴趣簇类。
在最开始尝试模型的时候遇到了一些问题,比如:
- 歌曲Embedding的聚簇效果不是很好;
- 用户的兴趣向量聚簇的区分度不够。
对于这两个问题我们也做了一些优化:
- 优化1:对于问题一,在Songid的基础上,加入完播歌曲的语种、流派等数据进行拼接,尽量减少模型学习的成本,显式地告诉模型,某些歌曲的聚类是相近关系。
- 优化2:对于问题二,在第二层也就是动态路由层的参数,Routing logits采用每个新样本重新初始化的方式进行更新,以这种方式进行优化,歌曲Embedding的聚类有非常明显的改善,而MIND结合sideinfo以及Modified DR路由方式,在Hitrate@200的指标上可以达到25.2%的结果,这个结果相对于前两个多兴趣baseline有一个非常明显的提升。

3. 基于Self-Attention的多兴趣表征方法
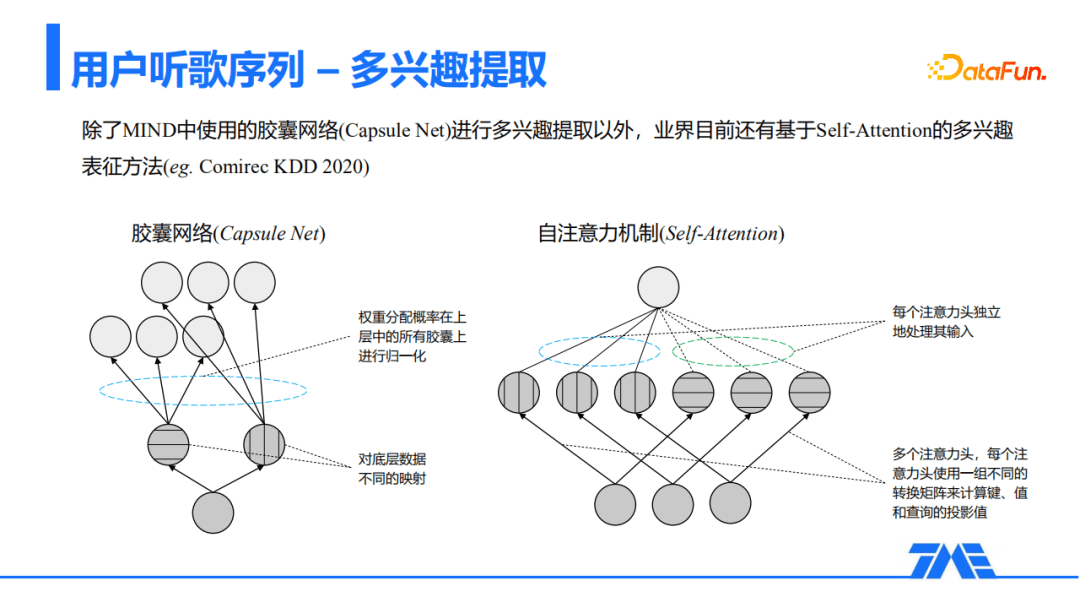
除了MIND使用胶囊网络的方式进行多兴趣提取以外,目前业界还有基于Self-Attention的多兴趣表征方法。区别主要在于神经元类型、权重分配方式以及权重的更新方式。下图中可以看到,左图胶囊网络权重的分配概率,是在上一层的所有胶囊中进行归一化;而在右图里面,每个注意力头独立的处理其输入。
我们对基于Self-Attention方式提取多兴趣也做了不少尝试,实验发现,基于Self-Attention多兴趣模型可以很好地刻画用户在不同的流派和语种上的偏好,推荐的平均热度也相对于Youtube召回有所缓解。左图是某用户每日30首的截图,基于多兴趣挖掘出了用户的三个兴趣:国语流行、英语流行及日语流行。AB实验中完播和收藏提升都是比较明显。以每日30首为例, DAU提升了2%;总播放和收藏渗透率都会有2个点以上的提升;语种和流派多样性也提升了3个点。
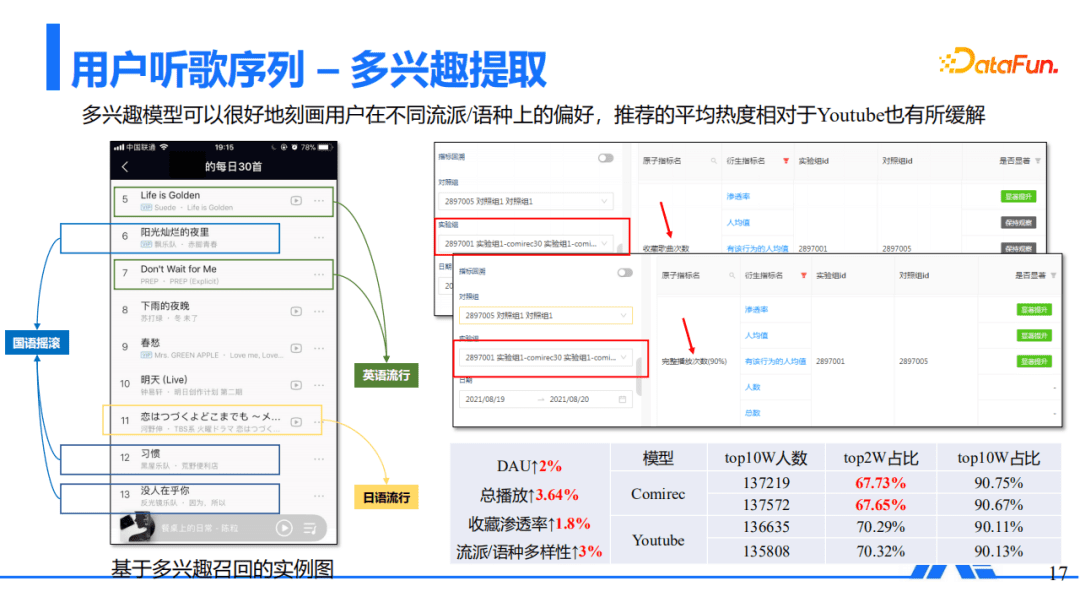
这种方式的引入,也解决了歌曲Top份额上的一些问题,大概有2%的热门下降,热门的推荐问题也有所改善。
04
音频召回
音频召回是音乐场景比较有特点的召回方式,将分两个部分展开讲解。
1. 音频特征挖掘方法
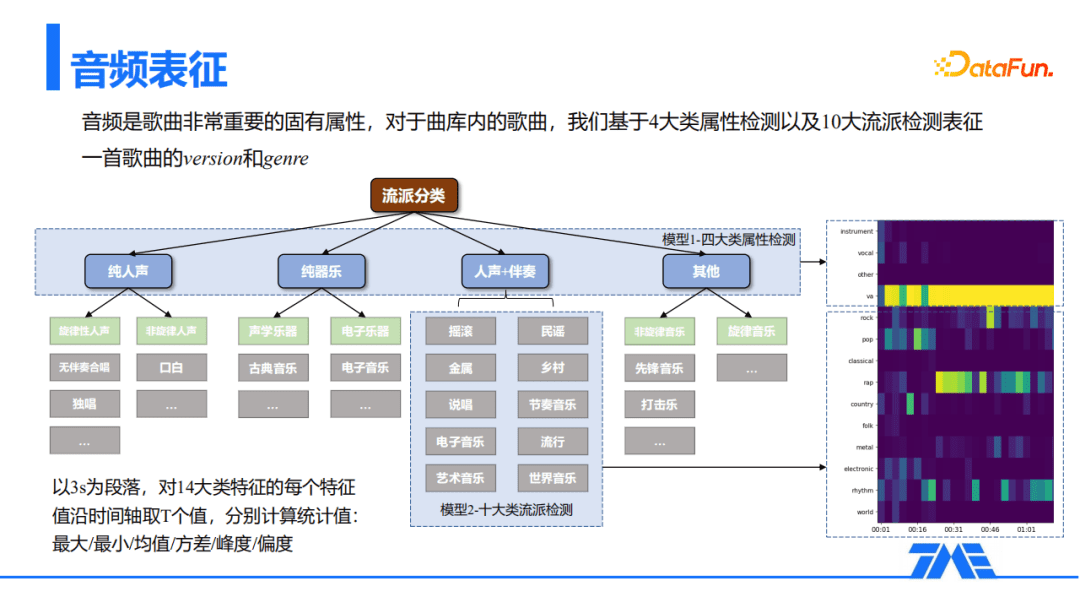
对于曲库内的歌曲,基于四大类属性检测,比如纯人声、纯器乐、人声加伴奏和其他,以及十大流派检测,比如摇滚、民谣、乡村等,来表征一首歌曲的version和genre,也就是版本和流派。具体是以3秒为一个段落,对14大类的每个特征值,沿时间轴取T个分值,分别计算统计值,包括最大、最小、均值、方差、峰度和偏度。基于这14大类,提取出右边这样的音频特征,而音频特征就是对应的音频表征(音频向量)。
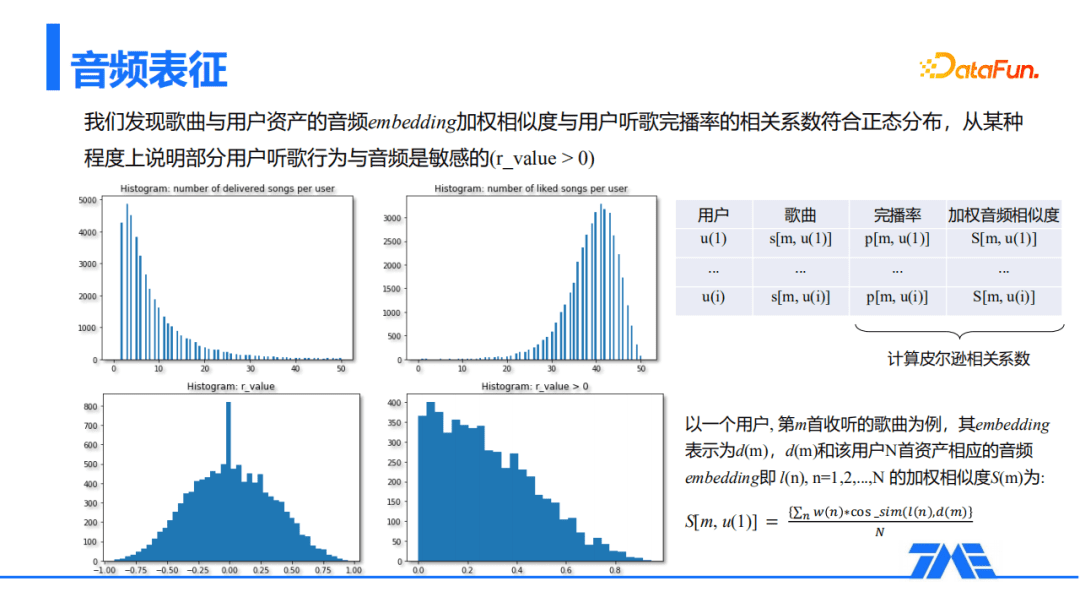
我们做了一些实验分析,并得到了一些结论:左上图是推荐给用户的冷启动新歌分布,右上图是对应用户人群的收藏歌曲分布,计算冷启动新歌的完播率与用户收藏歌曲的音频相似度之间的皮尔逊相关系数(具体计算方式列在下面),可以看到左下图是符合正态分布的,我们发现歌曲与用户资产的音频embedding加权相似度与用户听歌完播率的相关系数符合正态分布,从某种程度上说明部分用户听歌行为与音频是敏感的(r_value > 0)。
基于上面的分析结论,音频embedding也用在了QQ音乐单曲推荐的多个场景召回中。例如:使用音频相似做单点召回,提升了用户的惊喜感,用户的收藏行为有明显增加。前段时间大热的火星哥的Leave The Door Open,通过以音频相似来召回Peaches或者Walk on Water这一类歌曲。在没有其他协同信息的情况下,挖掘歌曲的音频表征也有助于冷启动分发。
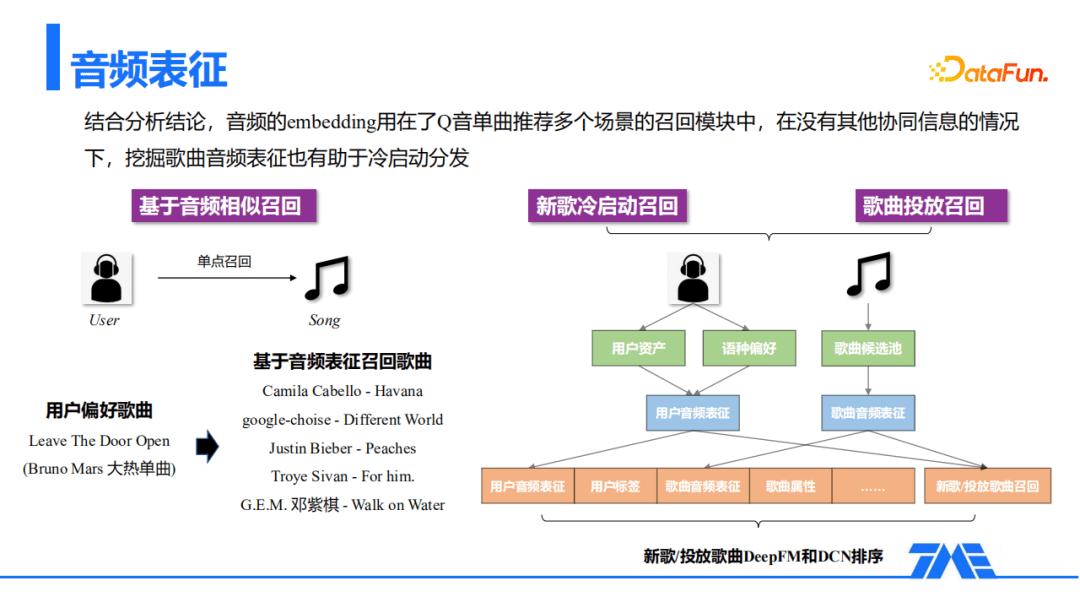
在新歌冷启动和歌曲投放召回里面,QQ音乐利用音频向量对用户的音频偏好以及歌曲音频表征进行处理,利用歌曲的音频表征进行候选歌曲的召回,再利用用户的音频偏好作为特征进行排序,也取得了非常不错的效果。
2. 多模态音频召回方法
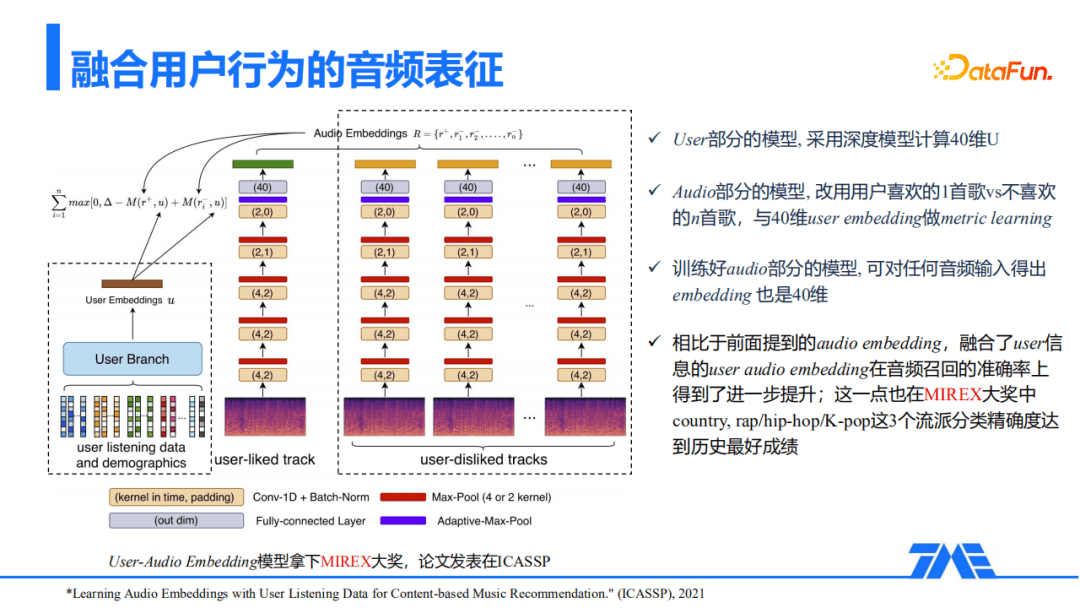
上面介绍的方式都是基于纯音频的表征,那是否可以联合用户的行为进行metric learning呢?通过实践,我们提出了User-Audio Embedding建模方法。user部分是利用深度模型计算的40维user embedding。audio部分的模型改用用户喜欢的一首歌和用户不喜欢的n首歌,与40维的user embedding做metric learning。训练好的audio部分模型,可对任何音频输入得到40维的embedding。相对于之前提到的单纯audio embedding,融合了user信息的user audio embedding在音频的召回准确率上得到了进一步的提升,这一点也在MIREX大奖中country,rap/hip-hop/K-pop这三个流派分类的精准度,达到了历史的最好成绩。User-Audio Embedding模型也拿下了MIREX大奖,论文发表在ICASSP上面,有兴趣的同学可以去搜这篇文章看一看。
05
联邦学习召回
1. 联邦学习召回方法
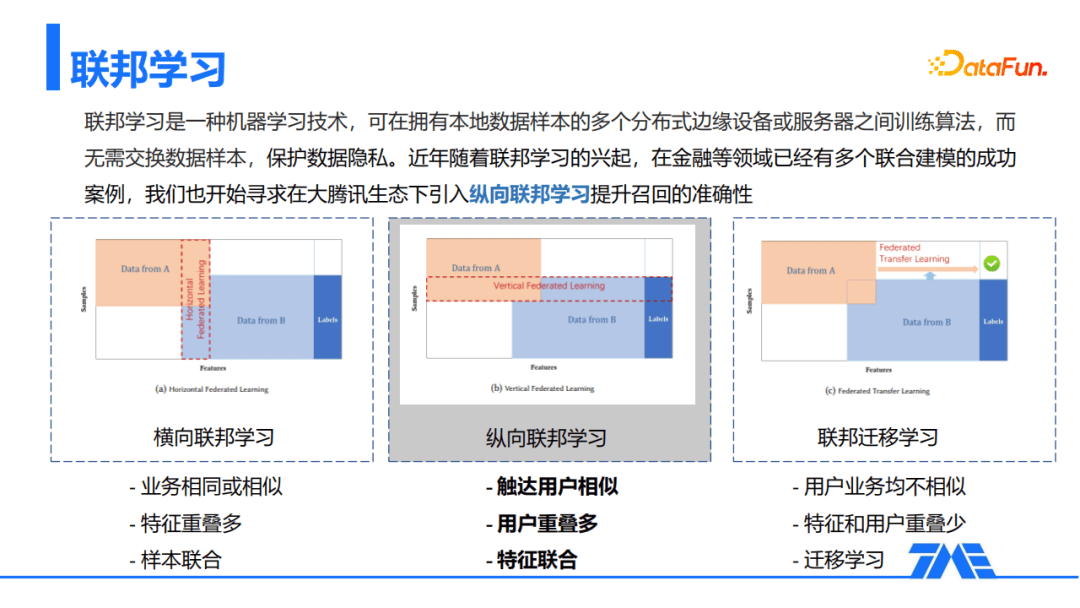
联邦学习是一种机器学习技术,可在拥有本地数据样本的多个分布式边缘设备或服务器之间训练算法,而无需交换数据样本,保护数据隐私。近年随着联邦学习的兴起,在金融等领域已经有多个联合建模的成功案例,我们也开始寻求在大腾讯生态下引入纵向联邦学习提升召回的准确性。
联邦学习有三个分类:
- 横向联邦学习,主要是业务相似或相同,它的特点是特征重合,多做的主要是样本的联合;
- 纵向联邦学习,主要是触达用户的相似,它特点是用户重叠多;
- 联邦迁移学习,主要是做特征的联合,用户和业务均不相似,特征和用户的重叠都比较少。
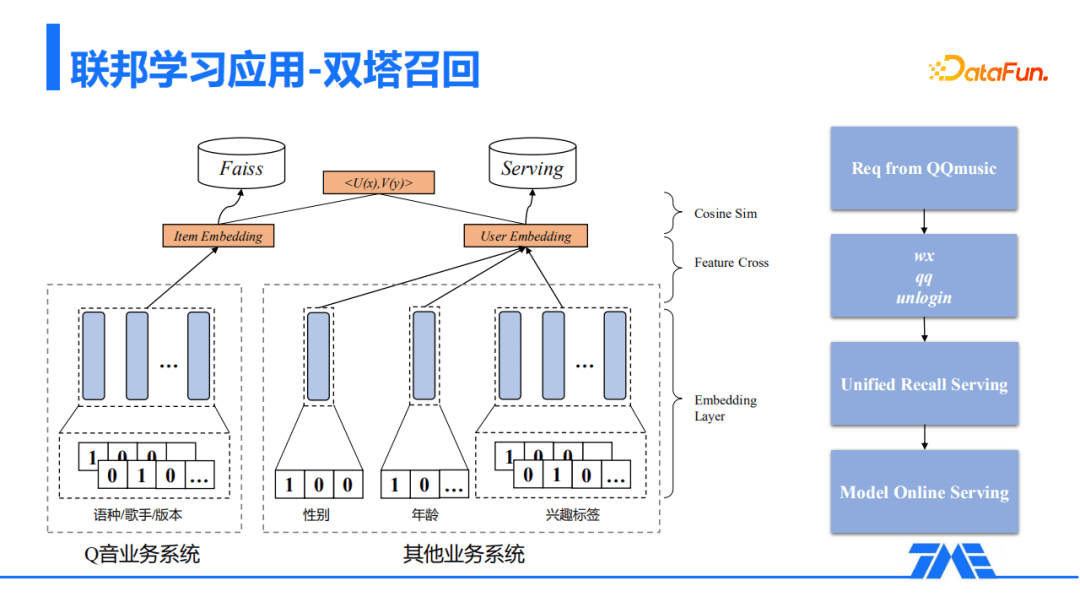
在QQ音乐场景里,我们寻求纵向联邦学习去进一步刻画用户特征。QQ音乐结合其他业务场景的系统数据,联合训练了双塔DSSM模型;其中QQ音乐塔,包含了歌曲相关的属性,包括语种、歌手、版本等;而其他业务系统塔,主要包含用户属性、用户的兴趣偏好,兴趣标签等。
在线服务中,Q音塔产出Item Embedding,其他业务系统塔产出User Embedding;使用Item Embedding建立索引,而User Embedding通过线上实时Serving预测得到后去做近邻查询。
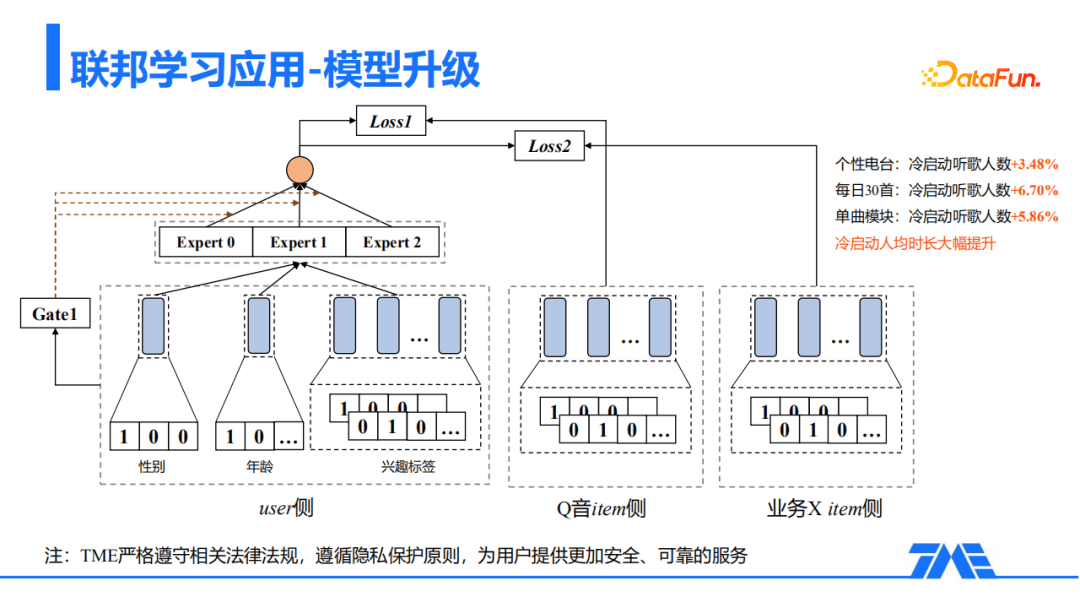
2. 联邦学习升级方案
下图是一个双塔的多目标模型,QQ音乐在双塔召回模型的基础上,对模型进行了简单升级,可以结合多业务场景建模。采用MMoE模型对多目标进行学习,左边是user侧,引入了不同的Expert进行学习;右侧是不同业务场景的业务数据,包括QQ音乐的Item侧以及业务X的Item侧。这种联合学习能够把不同域的属性和特点都融合在模型里面,进而更精准地学习用户表征。联邦学习的引入大幅提升用户冷启动的数据,例如:个性电台、每日30首和单曲模块等等,这些入口的冷启动数据都有显著的提升,冷启动的人均时长均有10%左右的显著提升。这里还是要强调:联邦学习完全保护用户隐私,TME严格遵循相关的法律法规,遵循隐私保护的原则,为用户提供更加安全和可靠的服务。
06
精彩问答
Q1:音乐的召回样本是怎样实现的?和排序测的样品选择有哪些差异,原因是什么?
A:在音乐场景里,有非常多的入口。每个入口的样本分布差异很大,或者说特征分布是不同的。比如:每日30首的用户分布、特点,跟电台场景相比,差异很大。在最开始的时候也提到过这个问题,所以对于排序来讲,排序侧的样本是针对每个单独的点位做优化。所以这里的样本都选择点位本身的样本。而召回是所有入口都共用的召回模型,所以对召回模型来讲,用的是大盘数据,也就是用QQ音乐的整体数据做统一训练。
这样的好处是数据会相对丰富,且能够学习到不同圈层信息。对于深度召回样本来讲,更多使用的是完播序列样本,另外还包含了人口统计的特征,以及一些收藏信息等。对于排序侧的样本就不是这样了。
刚才讲的是深度模型召回样本的选择。对于普通的单点召回,这部分主要是怎么去建图模型。图模型的建立目前主要是利用用户自建歌单,这部分数据可能有上十亿的数据,基于歌曲在歌单的共现情况,以及歌曲和用户的互动情况,可以构建非常大的图模型。基于上述方式构建图模型后,就可以使用各种图模型对节点进行表征了。
Q2:在音乐场景下怎么去平衡一个用户的长短及兴趣?
A:首先深度召回模型的输入本身是一个相对长期的序列,这部分兴趣序列对用户是比较长的一段时间、整体听歌行为的一个刻画。这部分刻画相对是偏长期;单点召回又是I对I的召回,是拿用户最近的播放行为进行关联,可能是一个短期相关的行为。举个例子,某用户最近在这一天或两天内收藏的歌手,会认为是该用户最近的强短期兴趣,且会以这个兴趣为接下来发送更多可能喜欢的、音频相似的歌曲,或者是说协同相似的歌曲等。
所以如果以长短期兴趣为维度,一个做法就是深度序列模型,更加偏长期兴趣刻画,单点召回模型会相对偏短期。另外,我们也会构建用户的长短期画像,基于长短期的画像,会给定一些对应的召回路径,去满足用户长期和短期的兴趣探索。当然不只是在召回会这样做,在排序模型里面也会加入用户长期和短期的特征,来捕捉用户的兴趣。这部分在召回的同时需要做融合,最后达到最好的结果。
Q3:多兴趣的召回,每个兴趣数的召回数量怎么选?
A:我们做了线上的实验,首先是每个兴趣的个数怎么选,这部分在离线实验的时候,对比不同超参,确定不同设置对Hitrate的影响。一般来说,K选的多一点,多样性就会好一点;K值过大,准确性会下降。在线上的时候有多种选法,比如:现在有三个簇,每个簇都召回50首歌,即150首歌,对每个簇的Quota分配都是公平的;另一种做法是每个簇多召回一些歌曲,然后做个排序,截断150首。这里面权重大的簇,露出就会多一点,弱势一点的簇露出个数就会少一点。
这部分线上也做了实验,把三个簇的结果融合在一起去做排序,而不是每个Quota都分配50,数据结果会相对好一点。但是热门分发的份额会更多,内容的利用率其实没有那么高。所以现在采取的方式是:每个簇都给了一定的Quota,让不同的兴趣,即使权重小,也有机会进入到排序层面进行公平的竞争。
在多兴趣召回部分展示的结果,也是基于这样的方式;这样的整体效果也非常不错,多个指标都达到了共赢。
Q4:音频特征相关的内容
A:音频特征是有加到排序模型里面的,在QQ音乐排序模型里面大量运用了音频特征。前面也提到了,在音乐场景里面,音频是比较关键的特征,能在一定程度上表现出用户的兴趣。
结合在PPT里面的分析,可以看到部分用户或者是大部分用户,其听歌行为还是跟音频信息相关。最近我们对音频的尝试,不管是基于歌手的音频相似召回,还是歌曲的音频相似召回,在数据上都有非常不错的表现,表现在收藏率的提升。因为用户不太熟悉这些歌曲,或是说它洞穿了目前的一些协同逻辑,所以给用户带来的惊喜性会更大。
Q5:QQ音乐技术栈是什么样的?
A:首先QQ音乐数据是基于ClickHouse +Superset的OLAP分析计算可视化平台架构,然后结合一些大腾讯组件,QQ音乐也做了一些开源的组件。后面会有介绍自己的机器学习平台,在模型训练层面,以TensorFlow为主要的开发方向。在数据处理上,主要还是Hive这类的大数据处理语言和组件。在整体的服务层面或Serving层面需要C++和Go等技能。这也是腾讯绝大部分业务的方向。
今天的分享就到这里,谢谢大家。
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/product/63389.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫