
大家好,很荣幸有机会为大家分享AI技术在有道词典笔上的应用实践。有道词典笔是辅助学生查词、翻译、学习英语的一款智能硬件产品。今天的分享中将会介绍有道词典笔的功能,处理用户扫描和点查的功能图像技术,无网络下进行翻译的离线翻译技术,以及支持各类AI技术在智能硬件上应用的高性能端侧机器学习的计算库EMLL(Edge ML Library)。
今日分享主要包括以下几个部分:
- 有道词典笔介绍
- 扫描和点查
- 离线翻译
- EMLL(Edge ML Library)
01
有道词典笔介绍


有道词典笔从外观看是一个小巧的、类似笔状的、可以握在手里的智能硬件。笔头部分安有一块超大广角的摄像头,用来扫描图像和文字,从而接收用户的输入。笔身有一块高清显示屏,显示用户查询的单词或翻译。显示屏还可以用来交互,帮助孩子学习绘本以及其它的一些功能。先来通过下面的小视频看看有道词典笔是如何工作的。
,时长00:23
通过视频可以看到词典笔有扫描和点查功能。扫描功能是支持跨行整句扫描的。当用户需要的内容被分隔成很多行时,词典笔通过换行整句扫描将其拼接成一整句文本,扫描的准确率为98%。同时,扫描的文字支持整句翻译。我们也将离线翻译的服务部署到词典笔上,在没有wifi的情况下也可以翻译。此外,词典笔极大地提升了查词效率。过去查词需要翻阅纸质词典,这种方式的效率比较低。现在使用有道词典笔点击想要查询的单词即可查词,效率提升很明显。词典笔安装了屏幕,支持互动点读。在绘本上点击即可和词典笔进行交互学习。除了以上功能外,词典笔还有语音合成和辅助的发音训练等其它功能。

为了支持词典笔的这些功能,用到了很多技术。今天主要介绍:处理扫描和点查的图像技术,将翻译服务部署到词典笔的模型压缩技术,以及支撑这些技术在端侧智能硬件上快速运行的高性能端侧机器学习库EMLL。
02
扫描和点查
词典笔的扫描识别和常见的字符识别场景不同。通常字符识别场景的输入是一张完整图像。词典笔扫描的输入是用户手持词典笔在在图片或文字扫描时摄像头拍摄下来的图像。词典笔的摄像头每次只能看到一个小窗口的图像,在扫描的过程中需要不断进行拍摄。

在扫描时大概每秒会获得100张图像。扫描算法需要从图像中快速提取出用户想要使用词典笔处理的文字。

全景拼接是扫描识别中最重要的步骤。这一步骤要从拍摄的100多张图像中找到要识别的文本行。好的拼接算法对后续识别的影响很大。如果拼接的不好,如PPT下侧的示意内容,后续的识别算法也很难得到正确的输出。

全景拼接算法分为三个阶段:
- 像素级检测:对每个像素位置进行文字和背景的分类;
- 中心组行:基于分类结果和位置信息,将扫描的中心文字链接并组合成行;
- 纠正切行:将文本行从复杂的背景中切分出来,送到后续的识别模块。

除了全景拼接之外,还会遇到用户使用词典笔在不同的物体或者弯曲的表面进行识别的情况。此外,扫描识别到的文字可能是特殊字体、形近字,以及复杂物体表面的背景都会干扰识别结果。

因此,对识别算法进行了优化。在常规识别模块的基础上,算法新增了纠正模块。在扫描场景中,可能发现某个字符出错。比如,将“breakfast”中的“a”识别为“d”。在纠正模块中,加入了字符级别的语言模型,该模型可以对识别结果进行修正,将“bredkfast”字符“d”纠正为字符“a”。
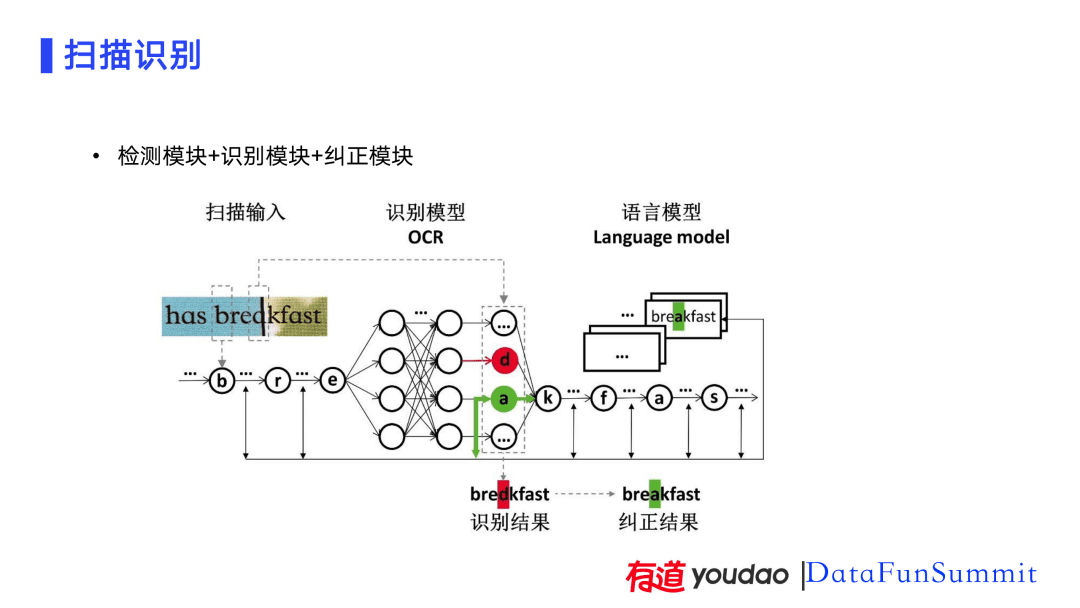
为了快速查词,词典笔增加了超快点查的功能,通过点击就可以得到完整的单词。为了增加这个功能,需要对硬件进行调整。词典笔新增了超大广角摄像头,一次就可以将完整、超长的单词拍下来。但由于广角镜头拍摄的范围比较大,会导致广角畸变;此外,不同位置的光照可能不完全相同,这也带来了光照不均的问题。为了解决这一问题,我们对算法进行了一些调整:用广角摄像头预先拍摄一些图像,基于拍摄的图像和正确的图像可以得到广角图像和真实图像之间的变换参数;之后将广角镜头采集到的图像进行逆变换得到无畸变的图像;对光照中的阴影部分进行补偿进而得到增强图像。最后将获得的增强图像送入OCR(文字检测识别)模块得到最终的识别结果。通过以上的方式,可以使识别结果达到98%的准确率。

03
离线翻译
接下来介绍一下自然语言处理离线翻译。
有道词典笔的定位是一个学习产品,客观上存在无网络使用的场景,比如:用户会将它带到学校,或者在境外购物时使用它来扫描商品的标签。此外,离线翻译不需要将请求发送至远程服务器处理再将结果反馈至用户的词典笔,它的时延低。同时,在扫描时会拍摄很多照片,离线翻译相较在线处理不需要上传照片到服务器,更节约带宽。很多用户对隐私数据安全性有要求,将服务部署到词典笔中不需要向服务器发送数据,用户数据的安全性也更高。

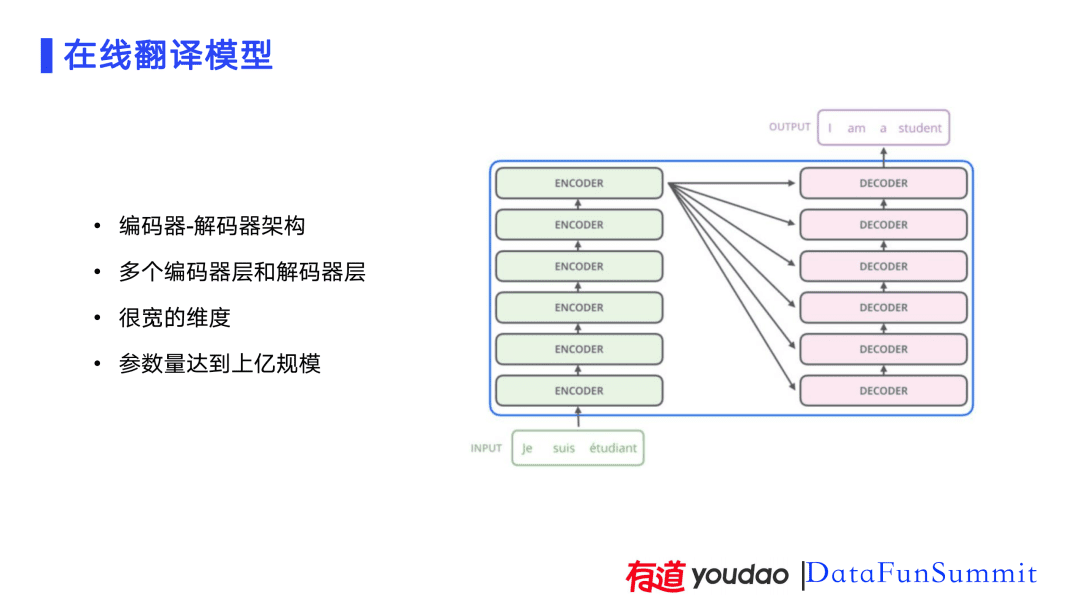
在介绍离线翻译模型压缩之前,先来看看目前的在线翻译模型。在线翻译模型使用了编码器-解码器架构,包含多个编码器层和解码器层。因为线上可以使用的资源较多,为了提升模型效果,模型的深度和宽度也大,这导致模型参数量达到了上亿的规模,计算量非常大。此外,线上服务端使用的GPU和很好的硬件,线上延时对用户来说是没有影响的。但将线上的服务部署到词典笔这类端侧设备中时,可用的资源就没有线上那么多,因此需要对线上的模型进行压缩。
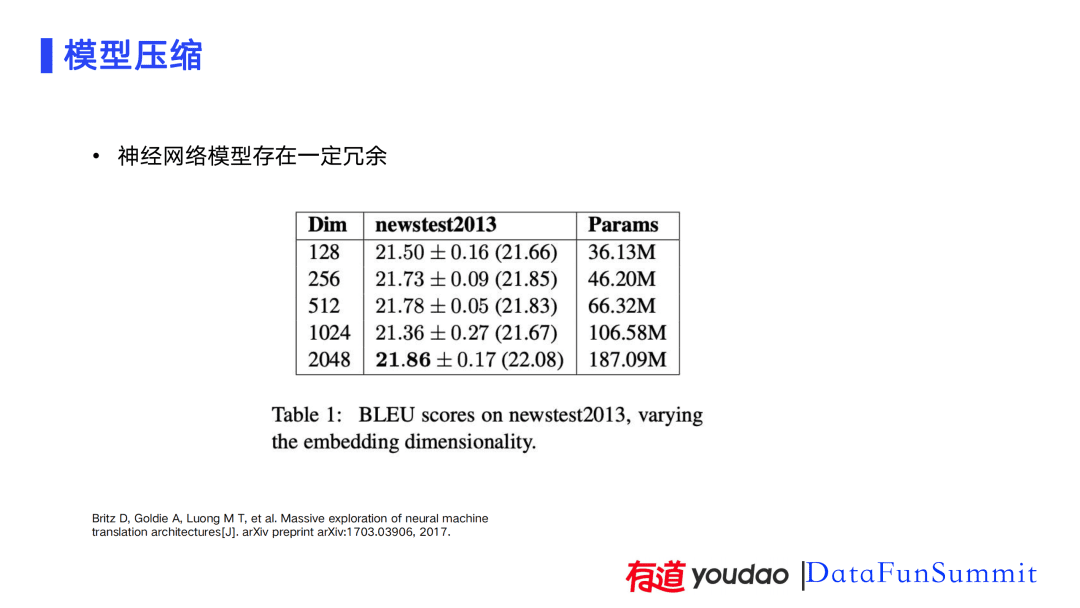
有研究表明:对神经网络的维度成倍增加时,模型结果没有达到成倍的效果。这说明神经网络模型存在冗余。因此,可以对模型的参数进行压缩。
我们使用了裁剪、参数共享、量化等多个模型压缩方法将翻译服务部署到智能词典笔之中。

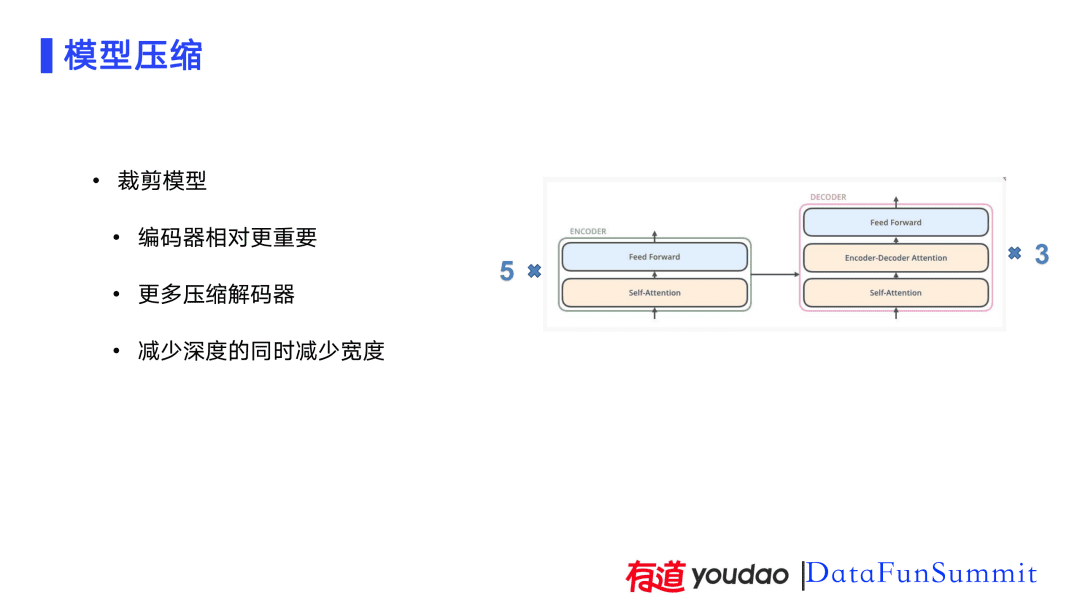
首先,对模型的宽度和深度进行裁剪。在此过程我们进行了大量实验,实验结果表明:编码器相较解码器更为重要。因此,在进行深度裁剪时采用了优先保留编码器层数、压缩解码器层数的方式。目前的模型是一个5层编码器3层解码器的结构。在减少深度的同时,也对模型的宽度进行压缩。
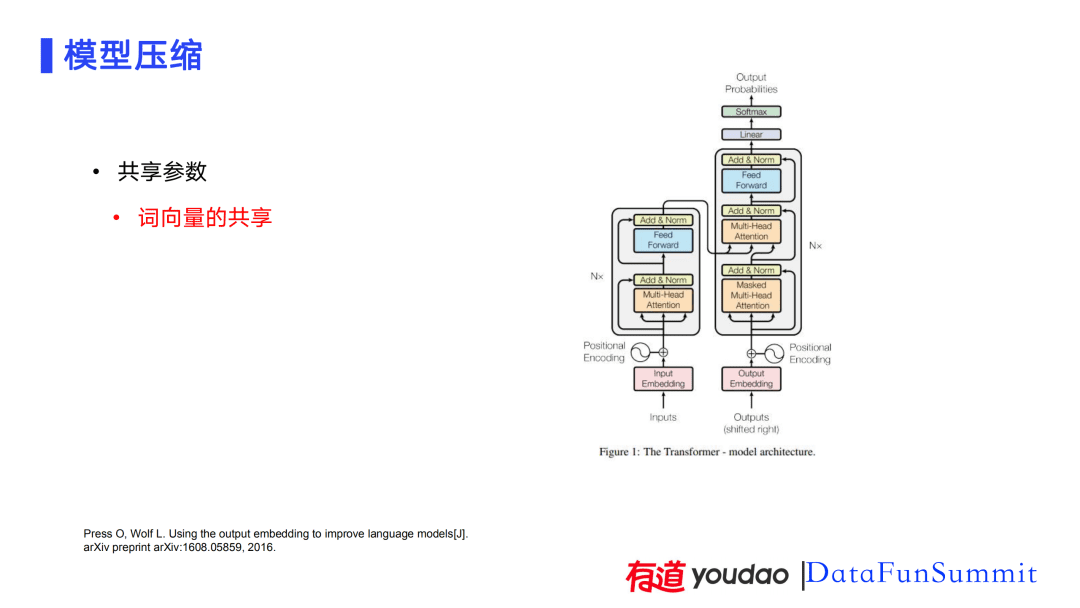
除了深度和宽度的裁剪之外,也进行了其它分析。数据表明模型比较大的参数集中在模型的Embedding矩阵中,比如:右图中有三个Embedding矩阵。源端的Input Embedding,目标端的Output Embedding,在Softmax的输出层将Linear input的函数投影到词表空间中,Linear层的参数也可以看成是一个Embedding。这三个比较大的Embedding的参数量加起来占到模型参数量的一半左右。以上分析表明,最主要的目标是减少词向量的参数量。分析发现以上三个Embedding的词向量是可以共享的。目标端Output Embedding和投影层的Softamax Embedding层的词向量在意思上和源端的词向量是一一对应的。输入端的Input Embedding和目标端的Output Embedding也是可以共享的。分析发现很多同样语系的词共享了很多单词。包括在中文和英文互译时,我们发现中文中夹杂了很多英语,比如:在介绍专有名词时会使用英文。因此,可以将源端的词和目标端的词的Embedding进行共享。
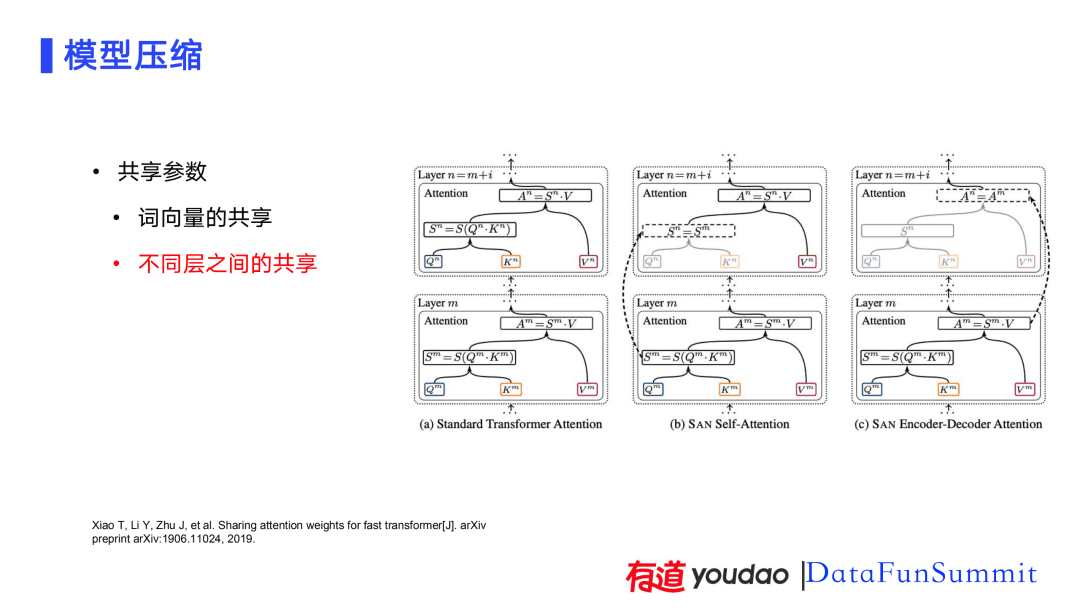
除了词向量之间的共享,我们还做了不同层之间的共享。这部分是参考了Shared Attention。标准Transformer模型的Attention的输入包含三部分:Query、Key、Value。Standard Attention Transformer这三部分都是不同的。在Shared Attention中,Query和Key在不同层之间进行了共享,这包含Attention权重和输出的共享,这对模型压缩很有用。
此外,还进行了一些模型量化的工作。在训练中,大部分使用浮点数进行训练。浮点数Float有4个字节,但高精度的浮点类型不是很有必要,可将其转化为低精度的整型计算。我们采用了线性映射的方式进行转换,比如:将浮点类型-10到30的区间映射到为0到255之间,0代表-10,255代表30。将浮点数转化为低精度整型计算后,整个浮点数的计算也是使用量化运算的,这块参考了谷歌的计算方式。

量化带来了很多好处。首先,相较浮点型运算,整型计算量变少,对NPU、DSP芯片友好。此外,整型比浮点数存储规模减少。量化可能会影响模型质量,但实验发现如果只对模型部分参数进行量化的情况下对模型质量影响也比较小。
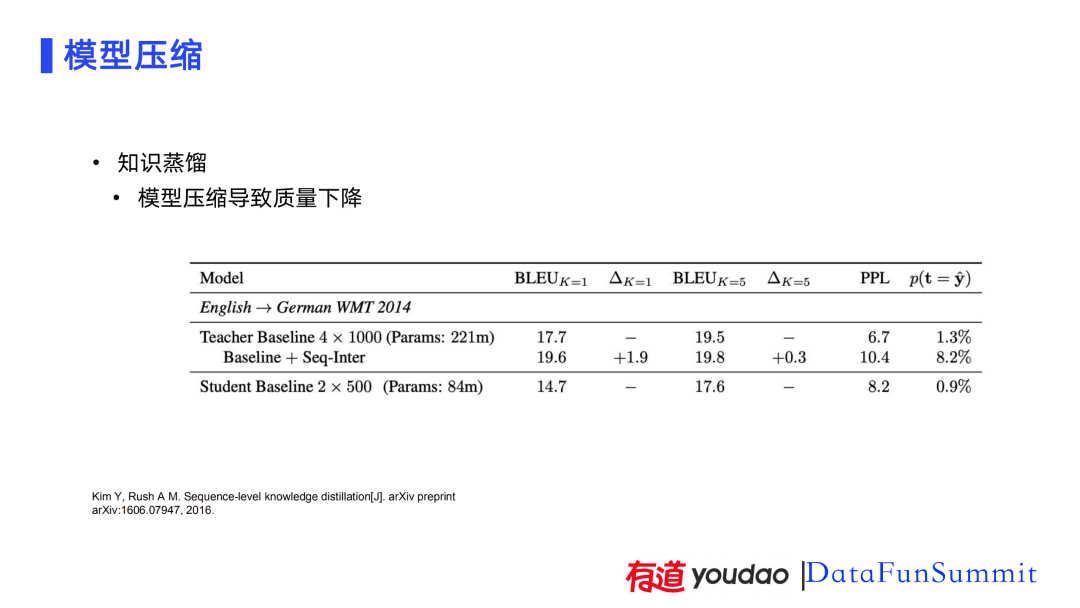
除了前面提到的共享、量化的方法,我们还使用知识蒸馏对模型进行压缩。通过减深度、共享、量化会导致模型质量下降比较多。从PPT的表格可以看出,如果只是减深度,模型的质量从19.6降低到14.7,质量的下降幅度还是比较大的。
因此,可以将大的教师模型的效果通过知识蒸馏的方式转移到学生模型中去。教师模型是一个比较大的模型,我们不关注模型的速度,只关心模型的质量。学生模型是一个比较小的模型,我们希望它计算的比较快,可以部署到端侧设备中。通过知识蒸馏将教师模型的性能转移到学生模型上,进而获得了一个小而快且质量接近教师模型的模型。

知识蒸馏在机器翻译中有不用的层次。词级别蒸馏指的是教师模型每次预测出一个词的分布,通过该分布监督学生模型每一步的输出。通常学生模型如果从真实语料中学习的话只能学到语料标注的一个标签的信息,但教师模型在预测每一步的时候时会给出完整词表中词的分布,包含的知识更多。此外,还有句子级别的蒸馏模型。教师模型根据每个句子推理出模型结果,使用该结果作为标签监督学生模型。在PPT中,左边是词级别的知识蒸馏方式,教师模型中每一步预测出一个向量用来监督学生模型。中间是一个句子级别的知识蒸馏的方式,教师模型通过推理的方式推理出当前最好的翻译结果,将翻译的结果作为句子标签去训练学生模型。通常情况下,句子级别的知识蒸馏会和真实的Ground Truth标签进行差值结合。在我们的方法上实验发现,进行句子级别蒸馏的方式和教师模型相差的不多。

04
EMLL(Edge ML Library)
前面我们对词典笔、词典笔中扫描点查和翻译技术进行了介绍,为了让这些技术在词典笔更好的运行,我们开发了高性能端侧机器学习计算库EMLL(Edge ML Library)。
先来看看端侧AI面临的挑战:
- 首先,算力、内存有限。相较云端计算而言,端侧计算的算力、内存都小了很多量级,这就为算法的部署带来很大挑战。
- 其次,词典笔和手机这样的硬件相比电池容量有限,功耗也有很大限制。
- 此外,AI算法一直在更新,模型也越来越复杂。算法更新后,在小的智能硬件部署也会更加复杂。
- 最后,在智能硬件部署时不是单AI应用的部署而是需要将AI算法和多个应用一起部署,难度也更大。
后面主要介绍计算相关的工作,先来看看目前端侧AI芯片。传统的是ARM CPU架构,这也是当前端侧AI落地主流的平台。最近几年也有NPU、DSP、GPU的端侧异步计算平台。受生态环境影响,当前可落地的AI应用比较有限。之前提到端侧设备的功耗比较有限,考虑到NPU、DSP有很好的降低功耗效果,这种异步架构也是未来发展的趋势。
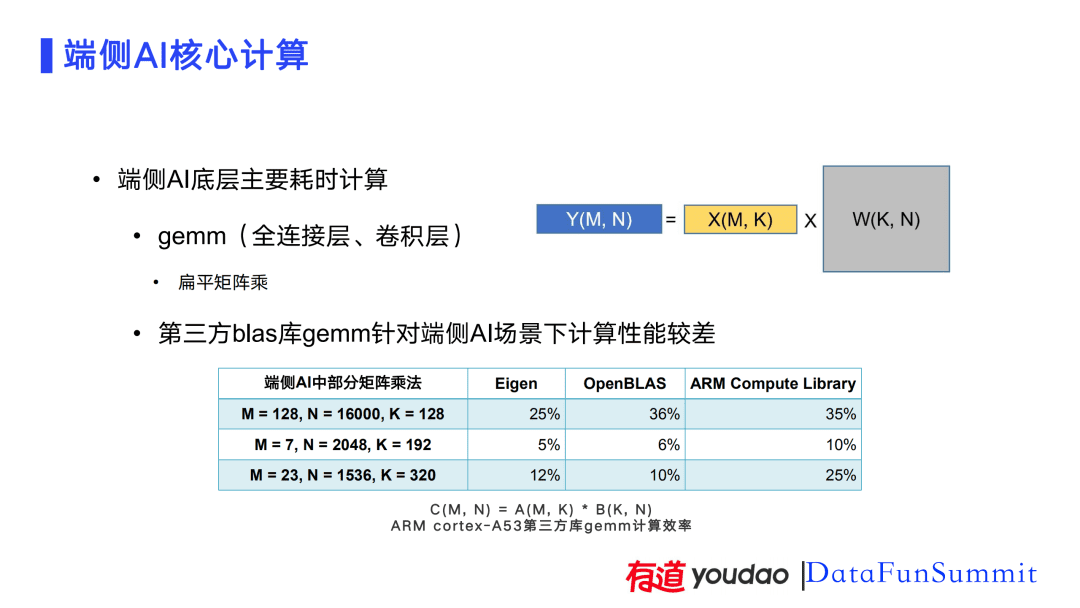
从计算角度来看,端侧AI计算主要耗时集中在底层的矩阵层计算中。从神经网络角度来说,卷积层很多情况下可以转换成矩阵层计算的形式。云端计算时可以通过Batch将矩阵层变为一个比较大的矩阵。但在端侧一般都是单用户的请求,往往是一个扁平矩阵的乘法。如PPT中右图所示,端侧AI计算时的输入矩阵或中间矩阵是一个行很小(几到几十)列很大(可能几千到几万)的矩阵,称其为X。X与一个与正方形矩阵或长方形的权重矩阵相乘得到一个扁平矩阵。在矩阵层有很多第三方Blas库,但作为一个通用库,Blas在优化的时候对常规的矩阵优化性能比较好,但对端侧AI场景下的矩阵计算性能表现一般。我们选择了三种矩阵尺寸,在Eigen、OpenBLAS和ARM Compute Library库中做了性能测试,数据显示在ARM cortex-A53芯片中计算效率都比较低,有的甚至不到10%。考虑到端侧芯片的性能本身相对比较差,而计算又不能充分发挥芯片的性能,这给部署带来了更大的挑战。
基于此,我们自己开发了端侧机器学习计算库EMLL(Edge ML Library),这个库主要是为了加速端侧AI推理而设计。这个库针对端侧AI常见的扁平矩阵计算做了专门的性能优化。目前支持fp32、fp16、int8等数据类型。此外,还针对端侧ARM cortex-A7/A35/A53/A55等低端芯片及ARM cortex-A76/A77等高端芯片进行汇编优化。数据测试结果显示:ARM cortex-A76/A77的优化性能比ARM cortex-A35的性能高一个量级。受成本限制,在手机等移动端的芯片性能比较高,但在很多智能硬件中芯片(如ARM cortex-A35)的性能相对较差。这种情况下就需要对芯片的性能进行优化。端侧运行的操作系统支持Linux和Android。目前我们的学习库已开源,欢迎大家使用并提出宝贵意见。git地址为
https://github.com/netease-youdao/EMLL。

EMLL库在访存和计算方面也进行了优化。在进行计算时,EMLL对不同尺寸矩阵的分配策略不同。考虑到不同芯片的汇编指令有别,EMLL针对不同的芯片采用了不同的优化方法。

EMLL目前支持矩阵乘法中支持常规的float32、float16和量化后的int8,以及常见的量化函数。在架构层支持ARMv7a和ARMv8a的架构。

针对单个矩阵层,在A35和A53芯片进行了优化。如PPT所示,左边是A35右边是A53,数字代表每秒计算的GFLOPS值。相较Eigen3和ARM Compute Lib v20,EMLL在性能上都有了很大的提升。
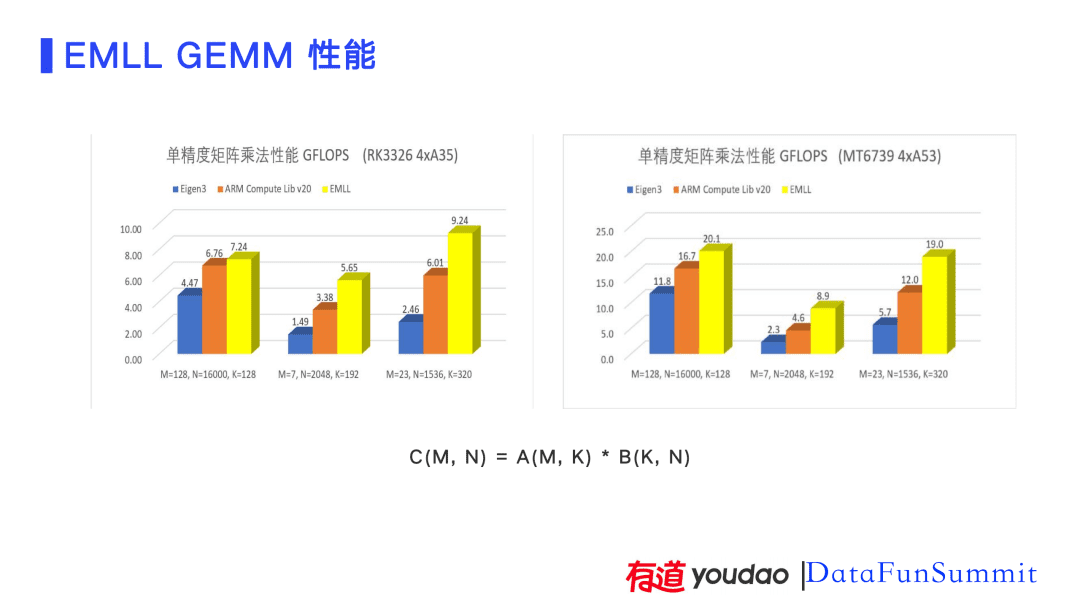
接下来看看EMLL在有道智能硬件中的性能。有道词典笔使用的是A35的CPU,有道超级词典和有道翻译王使用的是A53的CPU。我们测试了手机上高端芯片A76的表现和更低端的A7芯片的表现。下图中右侧展示了性能测试的结果,测试了NMT、ASR和OCR使用EMLL和Eigen端到端的性能加速比。
- 用户体验好:EMLL相较Eigen有30%到一倍多的性能加速比,更高的性能可以降低延迟带来更好的用户体验。
- 模型准确率提升:运算速度提升后延迟降低,在有效的时间保证更快的计算,因此可以通过增大模型提升模型质量。比如:可以将翻译模型增大30%,这可以将模型的准确率提升好几个点。
- 提升市场竞争力:之前词典笔使用A35是可以满足实时性而A7是完全不满足的,使用EMLL后虽然A7的性能相较A35差一些,但是已经可以满足使用需求。考虑到目前芯片荒的情况,这也增加了我们芯片的选型的空间和市场竞争力。
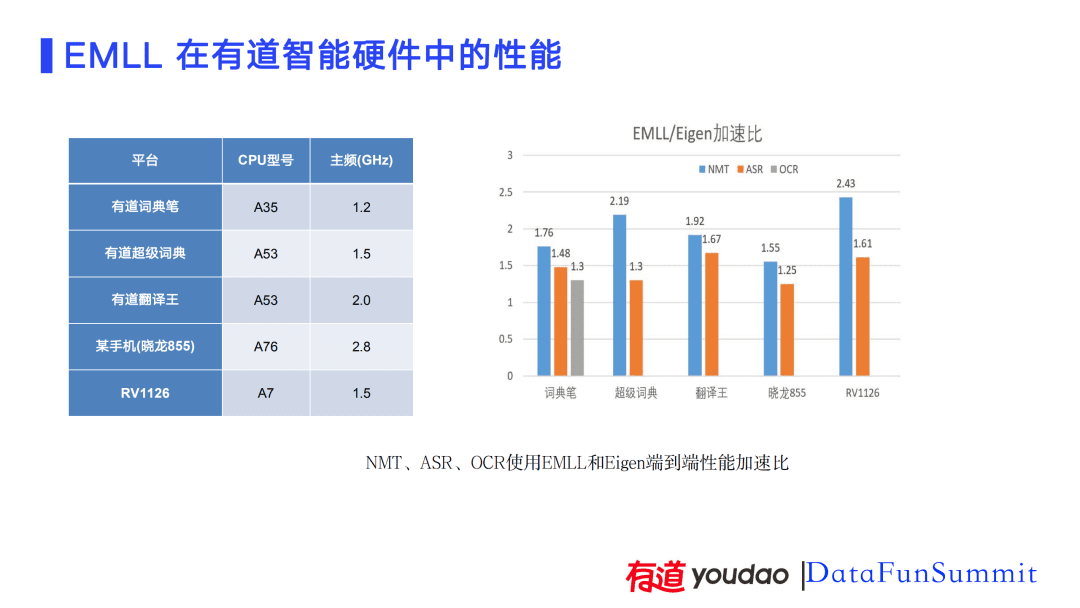
我们也评估了EMLL离线NMT的量化效果,在同模型对比int8和int32,在BLEU降低0.1的情况下,速度提升45%~67%,内存减少50%~60%。使用大模型int8和小模型的int32进行对比,其中大模型比小模型大50%,速度提升10%(也可以认为在没有下降)的情况下,将BLEU提升0.1,将内存降低32%。
最后借DataFun平台进行一个招聘,网易有道团队招聘算法、功能和产品同事,感兴趣的小伙伴可以加我微信或将简历发送至zhanggy@youdao.com。

05
精彩问答
Q:中英模型的目标矩阵共享会导致目标端词表增加,这是否会导致解码速度变慢?
A:中文和英文的字符集差异比较大,共享矩阵会导致共享词存储增加。在真实使用中,在中文夹杂阿拉伯数字、拼音、英文时实际上和英文端是有很多重叠,因此合并的收益是增加的。目标端词表可以通过词表裁剪方式将其控制在一个相对合理的范围。结合EMLL库的使用,整体速度是不会受太大影响的。
Q:参数共享、量化和蒸馏这三种模型压缩的方法在机器翻译中可以同时使用吗?如果可以同时使用,对翻译质量会有多大的影响?对推理速度会有怎样的影响?
A:可以同时使用。
(1)翻译质量
参数共享对速度影响不大,质量无损失。量化对质量的影响也比较低,合理选择量化对质量影响很小。此外,量化使模型计算速度变快,进而增大模型从而提升模型质量。蒸馏将大模型质量应用到小模型,使得小模型质量接近大模型,这是提升模型质量的。
(2)推理速度影响
参数共享会导致词表变大,有一些影响。量化是提升推理速度的,EMLL库对模型量化进行了优化,速度提升很明显。蒸馏只改变训练过程会提升模型质量,不会影响模型速度。
今天的分享就到这里,谢谢大家。
分享嘉宾:


本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/product/63410.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫