
导读:本次分享主要从四个方面来介绍:
- Angel Graph起源和发展
- Angel Graph框架
- 通信和计算优化
- Angel Graph应用

01
Angel Graph起源和发展
首先,简单介绍一下Angel Graph的起源和发展,方便大家理解我们的演进方向。

Angel在2017年开源了1.0版本,当时它还只是一个支持高维稀疏大模型的平台,只包含LR,LDA,GBDT这样一些机器学习算法。到18年发布了1.5版本,有两个非常重要的feature奠定了系统的高性能和易用性。一是支持了自定义的PS function,它使得PS可以承担部分计算功能;二是引入了spark生态,整个平台的应用性得到了很大的提升。
从18年下旬开始,业界和学术界图数据增多,挖掘价值很大,但当时业界的一些图平台难以做到高性能、高可用和应用性的统一。GraphX作为流行的图计算框架不能很好的支持百亿级规模,因此,很有必要基于自己的平台打造一个高性能、高可用的图平台。因为图算法本质是一个高维稀疏的模型,与Angel PS的能力完美契合,所以我们就基于Angel打造了一个图平台。v3.0,v3.1和v3.2这些版本侧重点集中在图算法的完善和优化上。3.2版本算是一个比较完备的大规模图计算平台。这就是我们的框架从机器学习到图学习的平台演进。
02
Angel Graph框架
接下来给大家详细介绍Angel Graph框架。
1. Spark on Angel
Angel Graph可以分为几个要素来理解:第一个就是Angel PS,从这个角度可以将Angel视作一个高性能的参数服务器。第二个要素就是Spark,Spark是大数据生态中一个很完善高效的ETL处理平台。
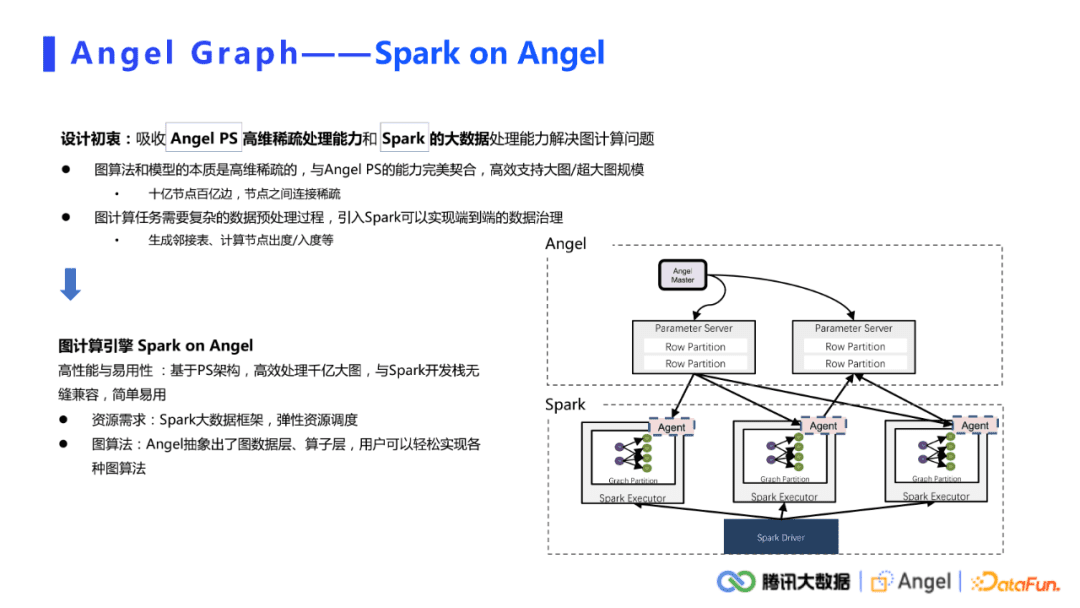
为什么要将angel和spark结合起来做图计算,主要基于两点考虑。
- 其一,算法和模型的本质是高维稀疏的。高维体现在工业界中的图数据轻而易举就达到十亿、百亿,甚至千亿级别。稀疏性主要体现在节点之间的连接本身就是非常稀疏的。类似PageRank,k-core等图算法,在迭代过程中会有一些节点慢慢变得不活跃。活跃的节点越来越少,所以计算过程也是偏稀疏化的。高维、稀疏这种特征与Angel PS完美契合,因此可以高效的地支持大图、超大图的规模。
- 其二,图计算任务本身需要一个复杂的数据预处理过程,比如数据切分,生成表示做采样,或者统计图上的一些节点信息如出度入度之类。引入Spark生态,可以很好的实现端到端的数据处理。数据从HDFS中读入,预处理后直接给图算子计算,最后将结果存储在HDFS中,实现端到端的过程。
Sparkon Angel是一个基于PS结构的高性能图计算引擎。其架构如上图所示,上面是angel,下面是spark。Spark负责分布式计算,Angel负责存储图模型,主要做内容的随机读取和访问。
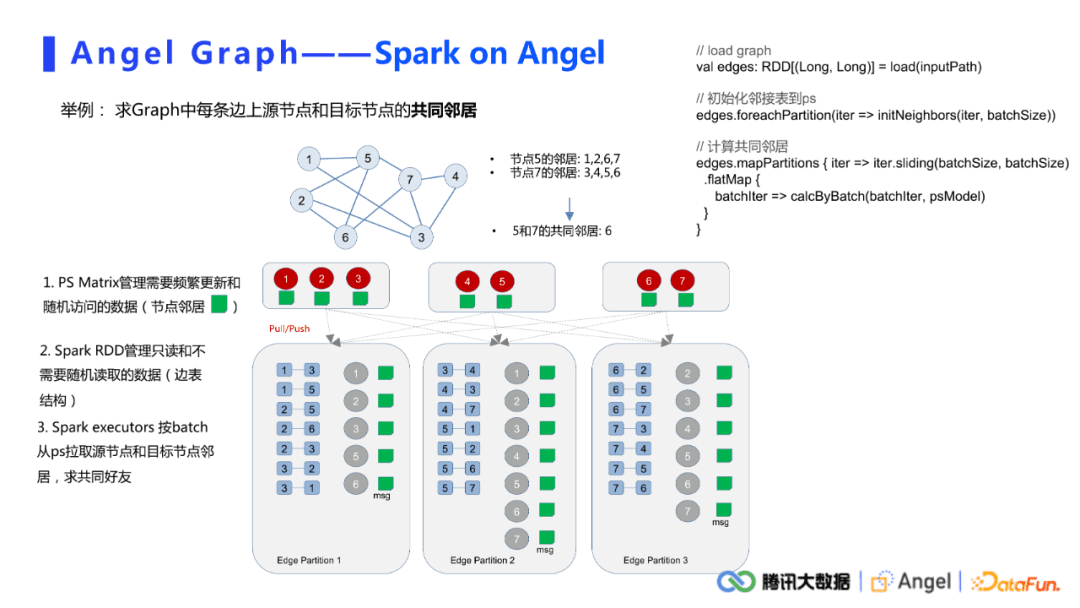
下面以一个求共同邻居的例子详细介绍图计算任务在Spark on Angel框架上的实现。假设在如上图所示的graph上,需要计算节点5和节点7的共同邻居。一个简单的计算逻辑是先拿到节点5的邻居{1,2,6,7}和节点7的邻居{3,4,5,6},把这两个序列做交集得到节点5和7的共同邻居6。
在Spark on Angel架构上,Angel PS用于管理频繁更新和随机访问的数据,这里主要指节点的邻居,也就是我们常说的邻接表。Spark从HDFS中读原始的输入边,形成一个edge RDD。在具体计算时,每一个executor对每一条边从PS中拉取原节点和目标节点的邻居,之后做交集。对于某一些算法,可能需要迭代更新PS上的模型,此时需要用一个push接口将需要更新的数据push到PS上。整个计算过程逻辑上非常简单。在实现上,这里简单列举了比较粗略的代码。可以发现主要都是Spark的接口,中间会穿插一些对PS的push接口,具体主要取决于用户如何处理规划自己的数据。
2. PyTorch on Angel
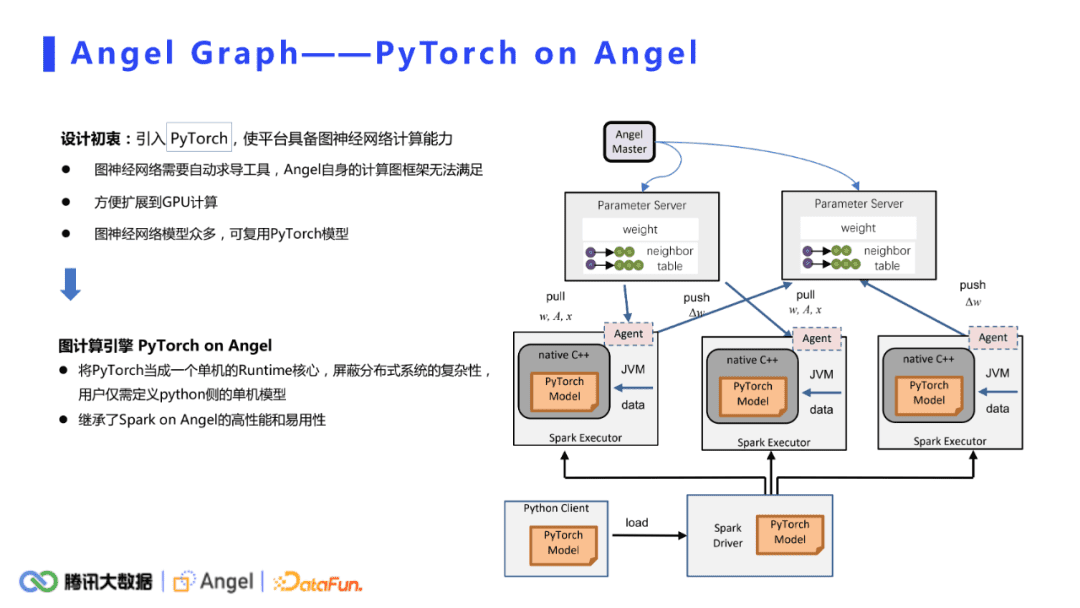
Sparkon angel主要是针对比较简单的图挖掘算法,但是对于图神经网络,它的能力是不够的。主要的原因是:
- 图神经网络需要自动求导工具,但是Scala的数据结构和运算是没办法实现的,angel自身的计算图框架也无法满足。
- 之前的模式是CPU共享集群,当引入PyTorch后可以方便的扩展到GPU的计算上。
- 引入PyTorch是为了拥抱深度学习的业界生态。由于学术界和业界基于PyTorch和TensorFlow的模型非常多,不需要重复造轮子。引入PyTorch就可以直接复用这些模型了。
基于以上三点,pytorch被引入进来。对计算逻辑相对简单的图挖掘算法,计算部分可以用一些简单的scala运算符实现,而在PyTorch on Angel框架下,Torch主要作为一个单机的runtime核心,原来的计算核心被替换成一个单机的PyTorch model,除此之外,外层的分布式框架几乎是一样的。PS负责存储模型的参数,单机的PyTorch model负责接收数据,然后做前向计算和反向的梯度计算,梯度被传递给PS做更新。对于用户来说,不需要关注外面分布式的壳子是怎么实现的,只需要去定义自己的PyTorch模型就可以了。
3. 图数据切分
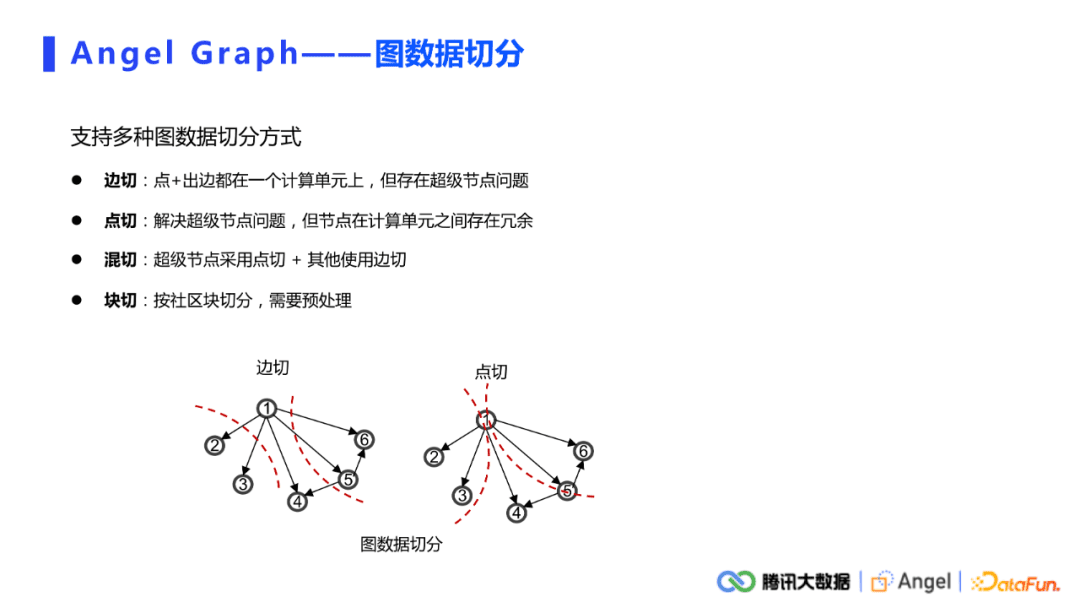
所有的分布式系统都会涉及到数据切分的问题。我们这里有两个分区,一个是Spark端的data分区,还有一个就是AngelPS端的模型分区。对于Spark端的图数据切分,本平台支持了多种切分方式,包括边切、点切、混切,还有块切。其它比较复杂的情况,需要去做预处理。其中点切、边切的方式都是非常简单的。比如,直接从HDFS读边,天然就是一个点切的方式。如果是对边的RDD做group by key操作,形成的就是一个边切的模式,操作起来非常简单。用户可以根据自己数据分布特点和计算逻辑,去选择需要的切分方式。
4. 模型切分
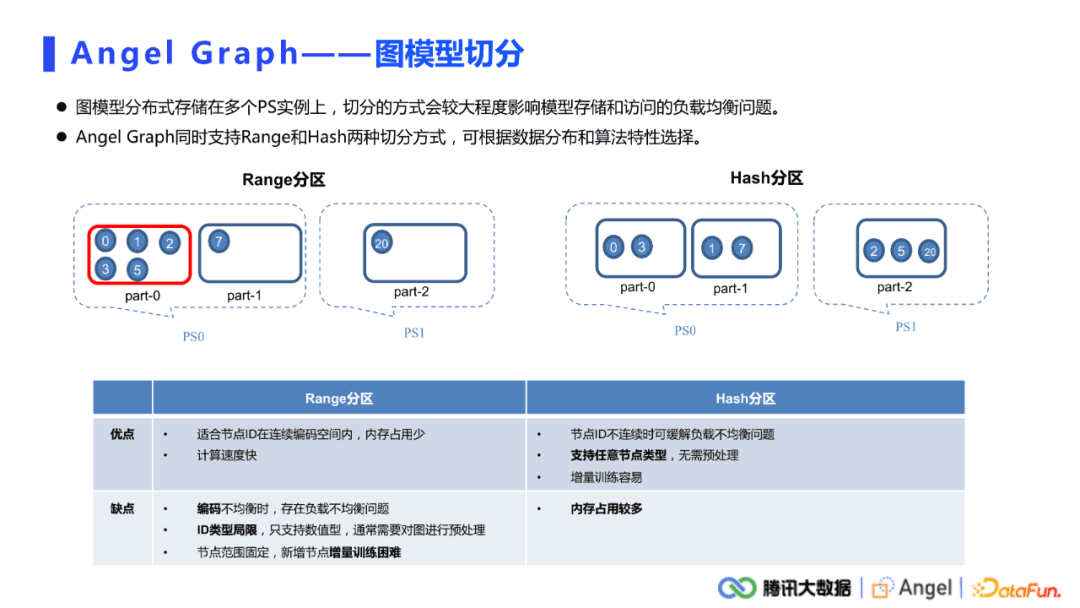
对于PS上面的模型切分,我们同时支持Range和Hash两种切分方式。
- Range切分。假设现有0到20这些节点,Range切分是按照它的最小ID和最大ID做一个均匀的切开,这样节点ID分布在连续的编码空间内,内存占用也比较少。但在节点ID不是连续分布的情况下,容易造成负载均衡的问题。
- Hash分区。Hash切分通过将ID打散,尽量的分布到不同的PS分区内,很好的缓解了负载不均衡的问题。而且Hash可以支持任意的节点类型,不需要提前将其他数据形式的节点ID编码成Long类型。其缺点是内存占用比较多,在实际使用的过程中,还是要根据具体的数据分布去选择合适的切分方式。
5. 稳定性
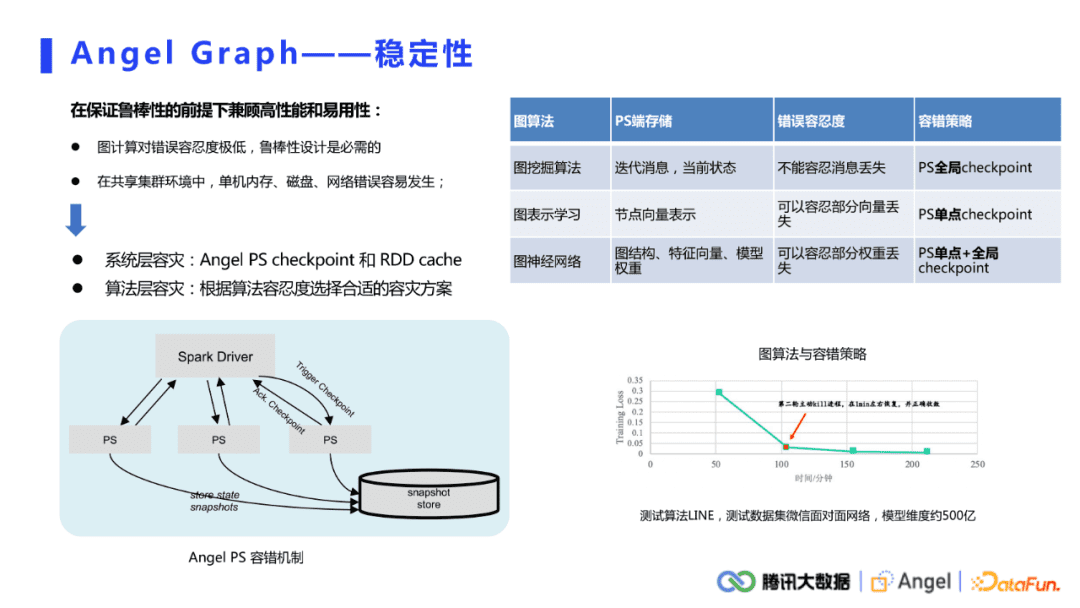
在共享集群的环境中单机发生宕机的概率是非常高的,而且图计算对错误的容忍度非常低,对于图挖掘算法,如果PS宕机,那么所获取到的消息是空的,此时整个计算都会发生错误,所以必须要考虑整个平台的稳定性。要保证鲁棒性的前提下,再去兼顾高性能和应用性。
系统层容灾:类似RDDcache,Angel PS端提供了checkpoint功能。用户可以选择让每个PS每隔一段时间checkpoint一下数据。当PS发生宕机时,重启的PS可以去检查是否有之前PS的备份,若有则直接加载进来,继续运算。
算法层容灾:根据算法的错误容忍度选择合适的checkpoint策略。① 图挖掘算法不能容忍消息的丢失,所以ps的容错策略也非常严格,需要同步做全局的checkpoint,可以保证全局正确性,但耗时较长;② 图表示学习类似于机器学习,可以容忍部分模型权重的丢失,因此不需要全局同步checkpoint,可以设置每个PS隔一段时间自动单独去checkpoint;③ 图神经网络算法在ps上既存有图模型权重又存有图结构和属性,同时兼具前两种类型的特点,因此建议单点和全局checkpoint结合起来使用,对不同数据类型采取不同容灾策略。
6. 易用性
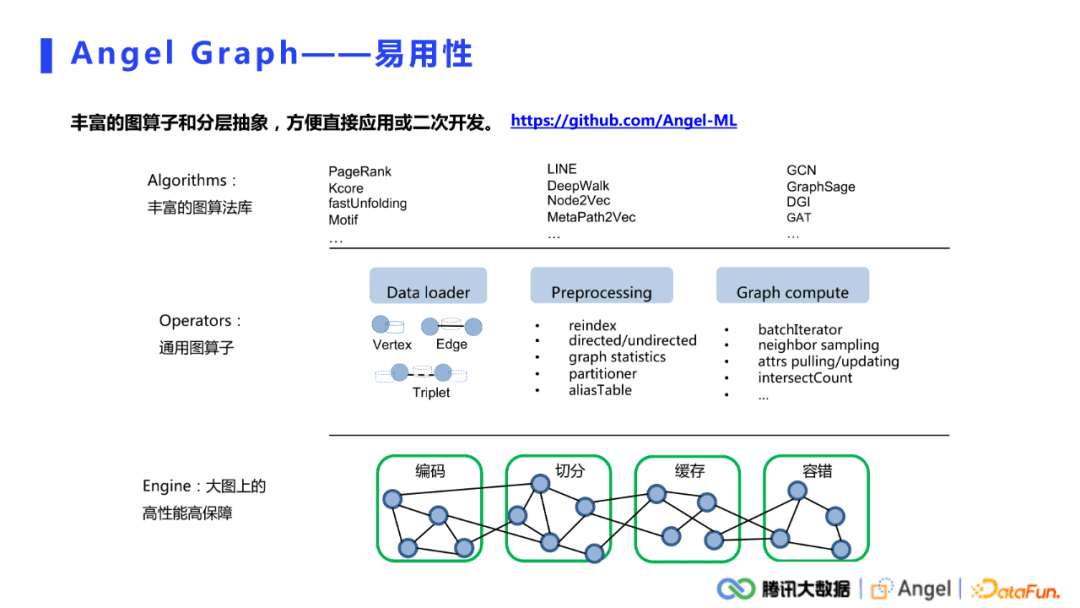
Angel graph的易用性体现在融合了大数据生态,是一个非常容易上手的平台。对于直接使用的情况,系统提供了非常丰富的图算法库,不仅支持了图挖掘、图表示还有图神经网络;对于需要二次开发的用户,系统抽象了许多通用的图算子,涵盖了从数据的加载,到预处理,再到一些常用的图计算算子的抽象。
03
通信和计算优化
因为在分布式系统上主要会涉及到通信和计算上面的开销,所以着重从这两个方面来介绍。
1. 通信优化
Angle是一个PS架构,计算和存储是分离的,因此在通信上会有两个问题。
- 连接数过多。在极端的情况下,一个worker可能要与所有的PS去做通信。
- 单次通信的量级较大。每次push或者要pull很大的数据,会导致性能问题。
(1) 通信链路过多
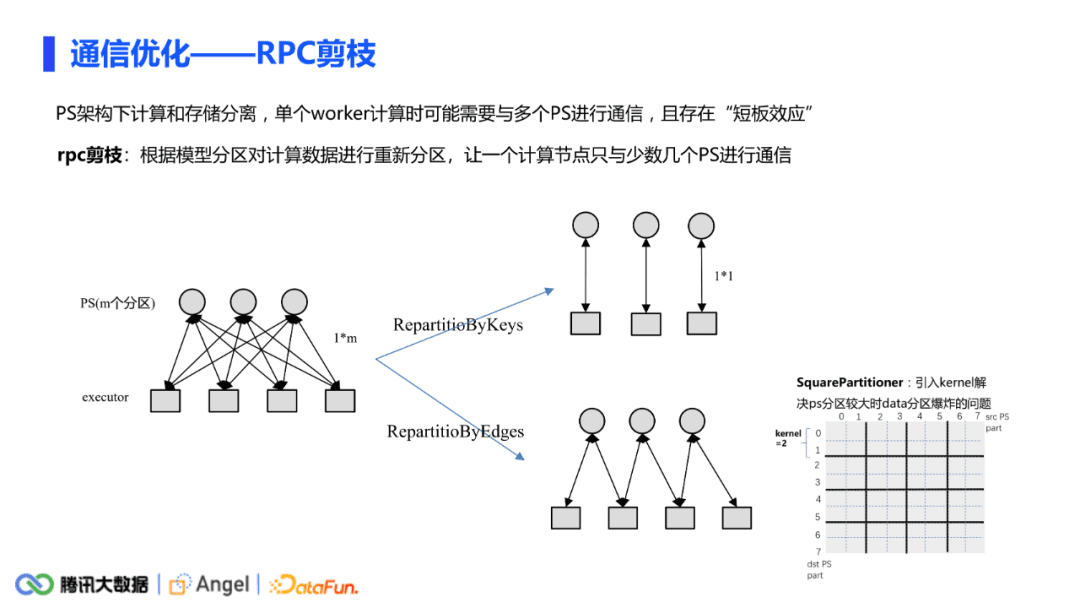
通信链路过多主要是会有一个短板效应。一次pull或push的时间是由最长的RPC决定的。因此可以进行RPC的剪枝,让一个计算节点只与少数几个PS去进行通信。
具体做法分为两种情况:
第一种情况,当只有源节点(或者key值)需要跟PS通信的时候,完全可以把data分区按照PS分区的方式进行分区,这样完全可以做到executor和PS一对一的关系;
另一种情况,当源节点和目标节点同时需要去跟PS进行通信时,我们基于这种情况针对性地提出了Square Partitioner分区方式,其原理如上图所示。假如PS有8个分区,data分区就有64个。每个data分区内获得的边都是根据PS分区来决定的,如图中第0个data分区中的所有边的源节点和目标节点都属于ps的第0个分区,而第1个data分区中的所有边的源节点和目标节点分别属于ps的第0个和第1个分区,依次类推,可以判定每个data分区最多只需要与两个ps分区进行交互。这种方法也会存在当PS分区值较大时导致造成data分区数暴增的问题。此时我们引入kernel的概念,如当kernel等于2时,可以让2*2=4个小分区合并为一个大的data分区,这样每个data分区最多只与kernel * kernel个PS分区进行通信,但data分区的量级迅速减少。这种分区方式在node2vec算法的测试可以让通信时间减少一半以上。
(2) 通信量较大
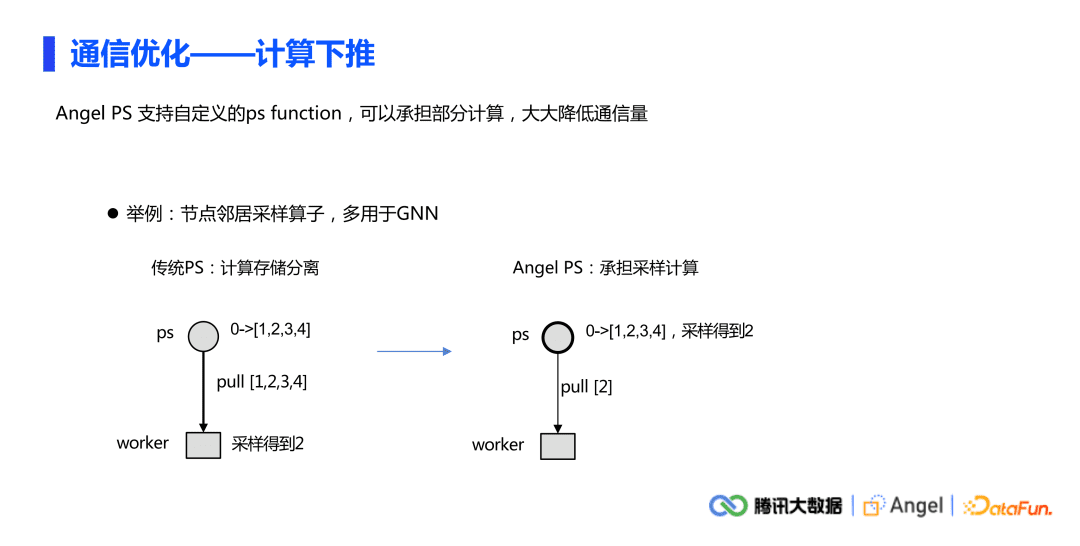
另外一个问题是通信的量比较大,通讯的数据比较多。Angel PS支持自定义PS function功能。Angel PS与传统PS的区别在于它可以做计算,计算的逻辑是由用户自定义的。对于经常要做邻居节点采样的情况,传统PS计算与存储完全分离,在对一个节点做采样时,例如上图左边的情况,worker端从PS把全部邻居拉下来(拉的是1234所有的邻居),然后在下边做采样(得到2)。但是如果PS可以承担部分计算,把采样的功能放在PS上面去做,这样拉的数据就只有2了。整体来看,把通讯的数据大小从边的量级降到了点的量级。
2. 计算优化
(1) 超级顶点打散计算
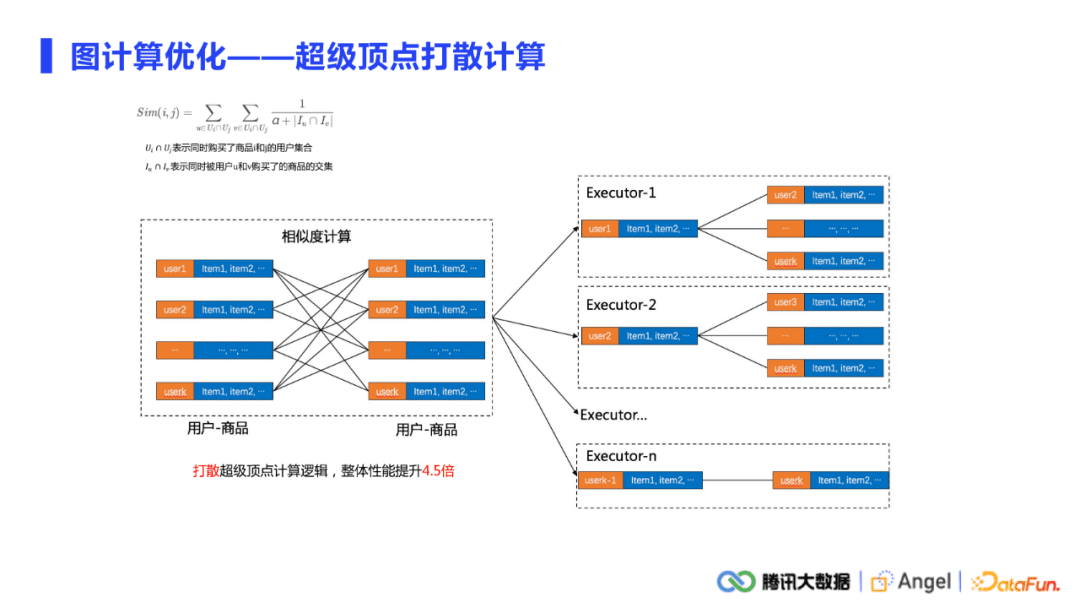
前面的是通信上的优化,计算也是较为关注的一个点。做图计算,超级节点是不可避免的。超级节点会引起负载不均衡的问题,通信会有,计算也会有。在通讯中,负载均衡和一些通讯的策略都可以去缓解。而在计算上有很多常用的trick。
举例来说,要计算任意两个商品的相似度,需要找到同时购买了这两个商品的所有用户。比如说100万个用户同时购买了A,B两种商品。这100万个用户各自有一条购买序列,计算A、B两种商品的相似度时有个操作是要去计算这100万个序列的两两交叉项,就形成了一个类似笛卡尔积的运算。100万×100万就达到了一万亿的维度,如果把这种计算放在一个worker上面是完全不可接受的。打散计算的策略是将把这些超级商品对单独提出来,将单个笛卡尔积的多次交叉项计算打散到各个worker上去。
总而言之,原来计算的力度是单个的商品对计算,现在是把计算力度打散,降低到单个交叉项上计算,这样就可以将已经空闲的资源全部利用起来,时间上也得到了非常显著的提升。
(2) 动态压缩邻接表
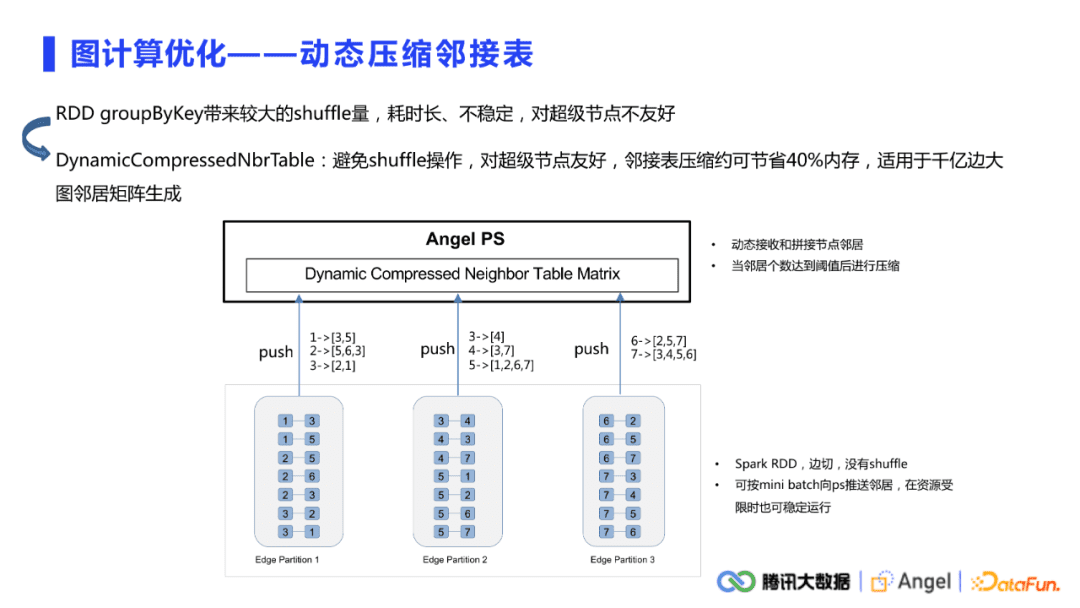
另一个计算优化是动态压缩邻接表,多适用于千亿边的大图。因为很多图算法都是需要先生成节点的邻接表,然后推送到PS上面去做一些采样或聚合操作。一般我们从HDFS读进来的直接是一个边表,要得到邻接表,就可以简单做一个RDD的groupByKey操作。对于这种千亿边的大图,这种操作会产生非常大的shuffle量。如果集群条件不是特别稳定的话,很容易在这一步直接宕机。
动态压缩邻接表读进来的也是边表的结构,但与之前不同的是不需要用groupByKey事先生成邻接表。当向PS push邻居的时候,只是push当前分区里能拿到的所有邻居。在Angel PS端会自动去做动态接收和拼接邻居的操作,并且当邻居个数达到一定的阈值之后会做压缩,整个过程是没有RDD shuffle的,对于超级节点也非常友好,push过程中可以按照mini-batch向PS做邻居推送,在资源受限的时候也可以稳定运行。
04
Angel Graph应用
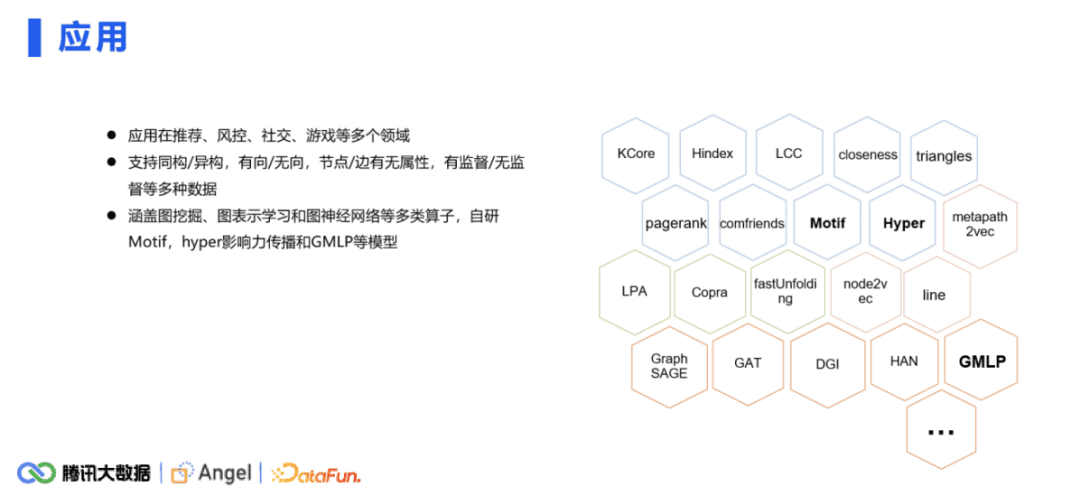
在公司内部,本平台在推荐、风控、社交、游戏等多个领域都有比较多的应用。数据和场景支持同构、异构、有向、无向。节点和边有无属性,有监督还是无监督都是支持的,涵盖了图挖掘、图表示学习、图神经网络等多种算子。
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/product/64500.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



