
导读:本次分享主要介绍以下四方面:
- 时序业务全景
- TSDB介绍
- 核心技术
- 总结展望


01
时序业务全景
从底层的机器监控到直面用户的应用,都离不开时序性的业务场景,而时序性的数据一般都由专业的时序数据库来存储分析,下面主要介绍TSDB覆盖的业务场景以及面临的挑战。
1. 时序数据库覆盖场景
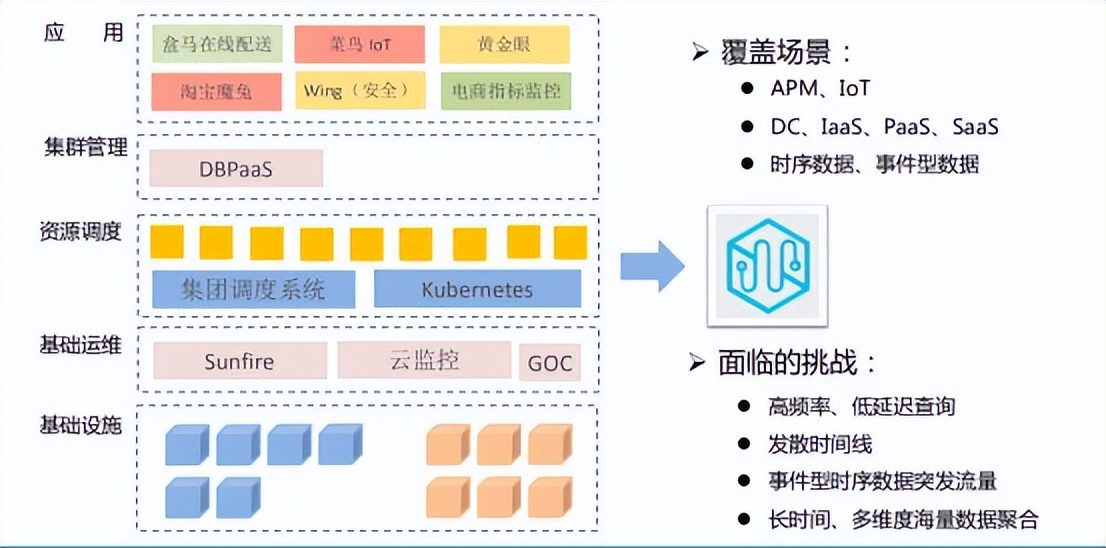
- 基础设施层:机柜、物理机、操作系统监控日志
- 基础运维:sunfire(集团统一监控、采集、报警系统)、阿里云监控、GOC(阿里全球应急调度指挥系统)
- 资源调度:集团内部调度系统、Kubernetes
- 集群管理:DBPaas(阿里所有数据库实例的监控和调度)
- 应用层:APM场景下的各种应用
2. 时序数据库面临的挑战
由于面临各个层级的不用场景,所以时序数据库也面临不同挑战:
- 应用层挑战:由于直面客户所以需要提供高频率、低延迟的查询
- olap数据库本身特性:海量数据的聚合
- 时序数据库特有的:发散时间线
- 双十一大促:突然流量十倍以上增长
—
02
TSDB介绍
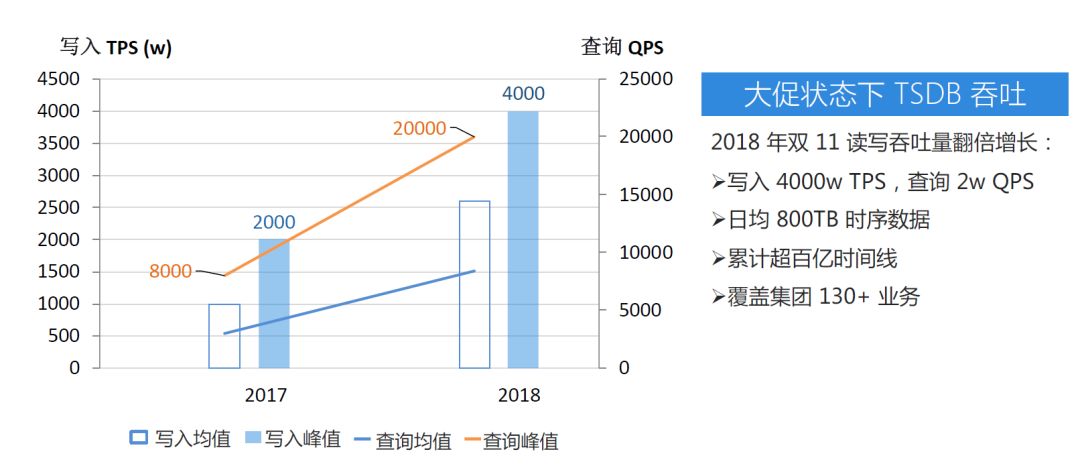
1.TSDB的发展及性能
TSDB于2016年开始服役,到目前为止参与了三次双十一大促,相比于2017年读写吞吐翻倍增长,写入TPS4000w,查询2wQPS覆盖集团130+业务线及存储百亿的时间线。
2.TSDB架构介绍
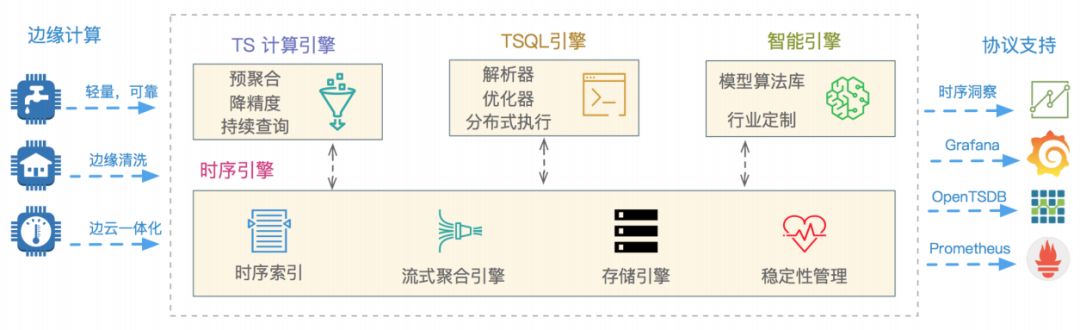
如上图,从左到右为数据的采集到展现的过程:
边缘计算:轻量可靠的计算方案,主要负责数据的采集,与云端的TSDB打通,在OLAP场景或者资源不稳定的场景下实现数据的稳定采集、清洗等。
时序引擎:
时序索引:时间线的查询;
储存引擎:时序数据、海量数据存储的解决方案;
流式数据聚合:在时序数据库的海量数据里做高效的的聚合分析;
稳定性管理:在云上稳定安全的运行;
计算引擎、sql引擎、智能引擎:主要与时序引擎交互实现数据计算、sql解析、模型算法等功能,可以扩展时序引擎的能力,降低使用的门槛;
协议支持:主要面向用户,为用户提供一些可视化的查询和分析支持。
—
03
核心技术
1.海量时序数据存储
(1)数据压缩
说起存储就离不开压缩,数据的压缩方法和压缩算法的选择很大程度上支持了海量数据的储存。
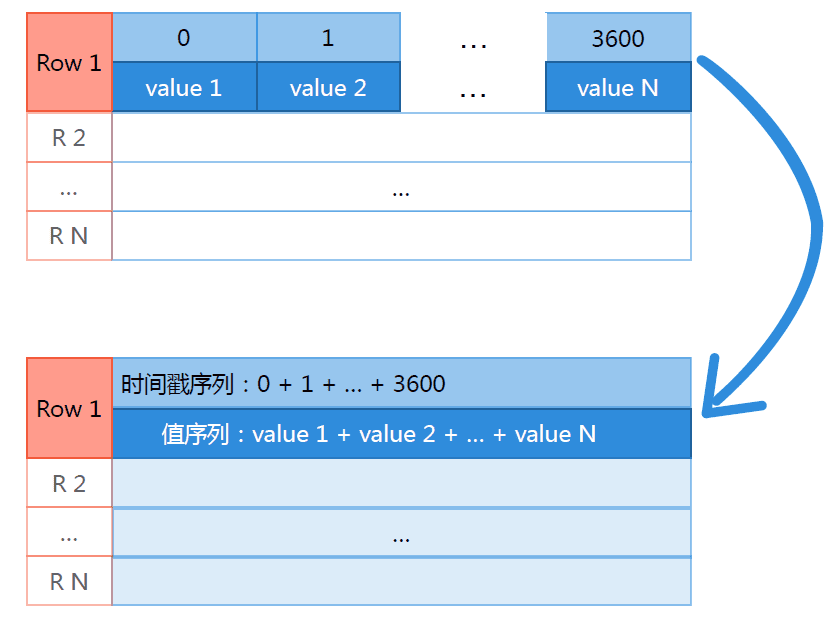
如上图代表时间窗口为一小时的数据,0-3600代表过去一个小时内的数据,采用key-value存储格式,以秒值作为key,每秒的数据作为value存储。
这里参考facebook grada思想引入了时序压缩算法,通过列合并的方式把所有的时间戳和对应的value聚合长两个的大数据块,然后对这个两个大块进行时序压缩算法,然后再用通用的块压缩算法进行压缩。
另外不同的数据类型采用不同的数据压缩格式,如:
- 时间戳:delta- delta
- 浮点型:XOR编码
- 整型:variable length encoding
- 字符串:LZ4,实现了存储层乱序数据压缩,保证压缩数据的准确性,整理的压缩率在15:1。
(2)数据压缩效果
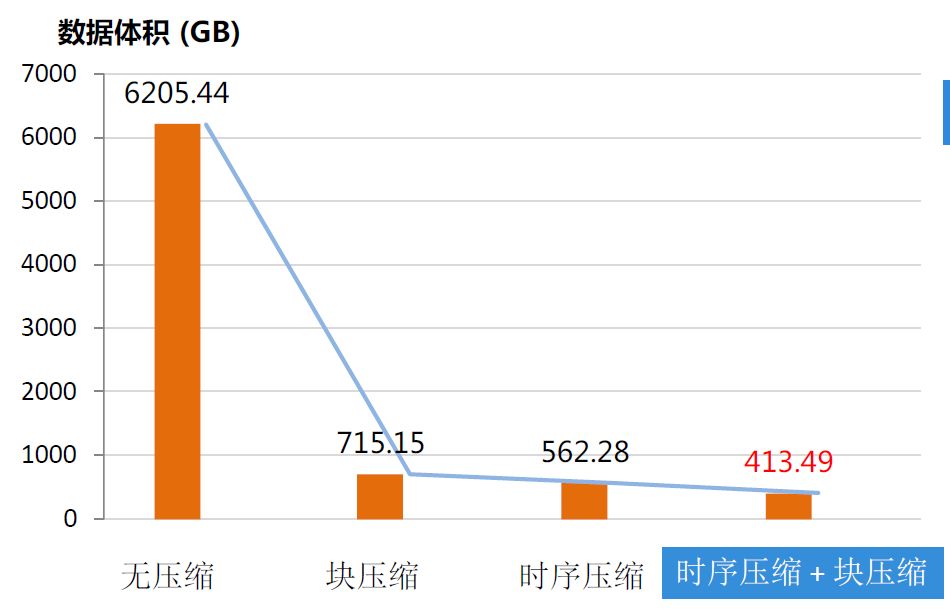
为什么要采用时序压缩+块压缩,我们可以看一下这个图。
首先时序压缩针对不同类型的数据采用了不同的压缩格式,所以整体的效果优于块压缩算法,而在时序压缩算法对数据压缩后在采用通用的块压缩,不会影响到块压缩的压缩效率,用时序压缩+块压缩相比单独的块压缩能有40%的压缩率提升,这为海量数据的存储提供了有力的帮助。
2.高频、低延迟查询
淘宝魔兔是阿里一款应用无线端数据分析和监控的产品,支持集团内部500+的应用,在双十一大促是查询峰值可达4000QPS,相较于平常查询量有10倍的提升,,99%读写rt都要求在20ms以内,那么TSDB是如何实现用户端高频、低延迟的查询呢?
(1)分布式缓存存储适配
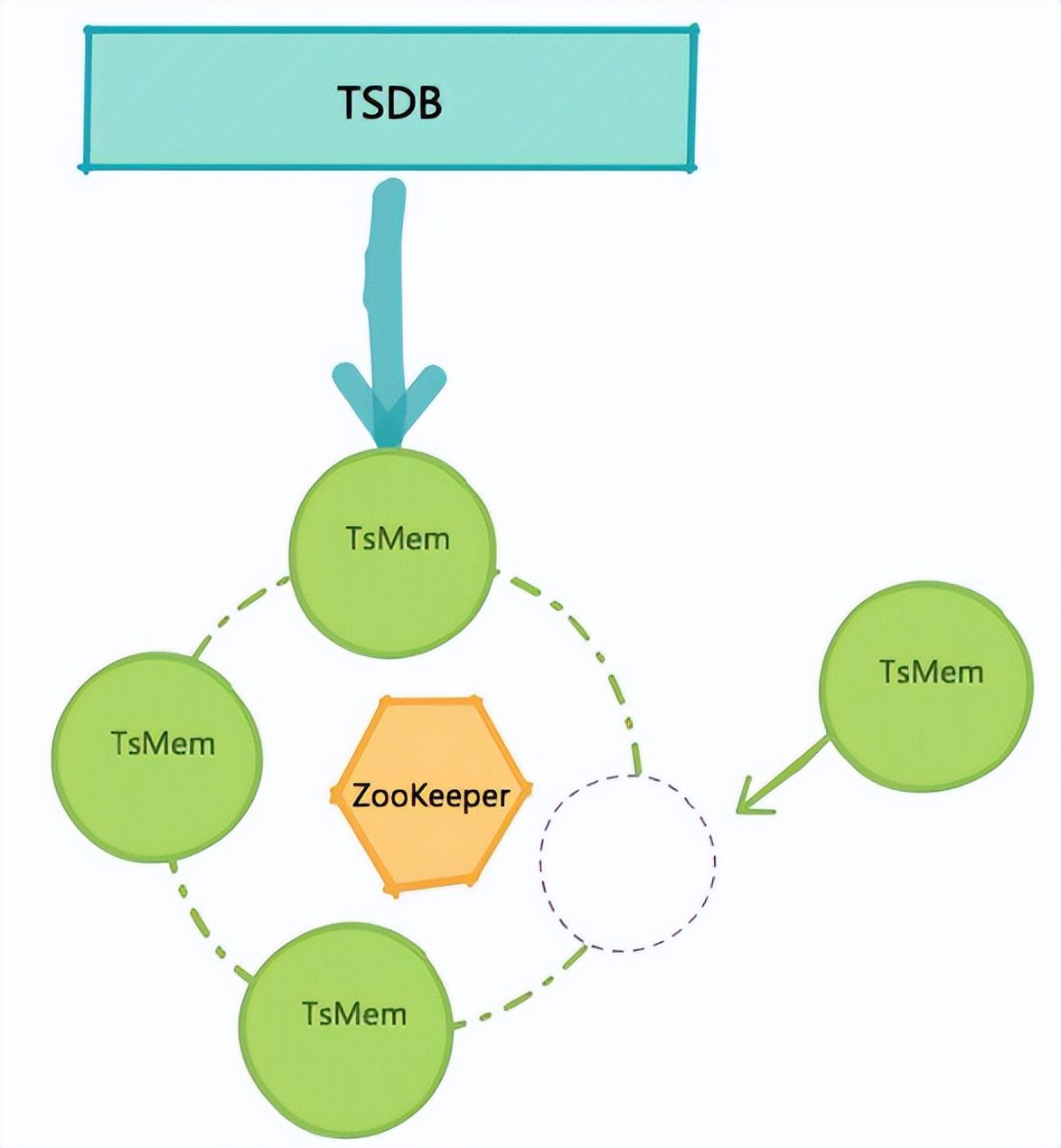
参考Facebook Gorilla论文,基于java做了一套分布式的内存缓存存储,基于zookeeper实现分片及容量的调整,可以实现动态的扩容和缩容,在整个双11过程中支持1000wTPS的写入和4000的QPS的查询。
(2)TsMem设计
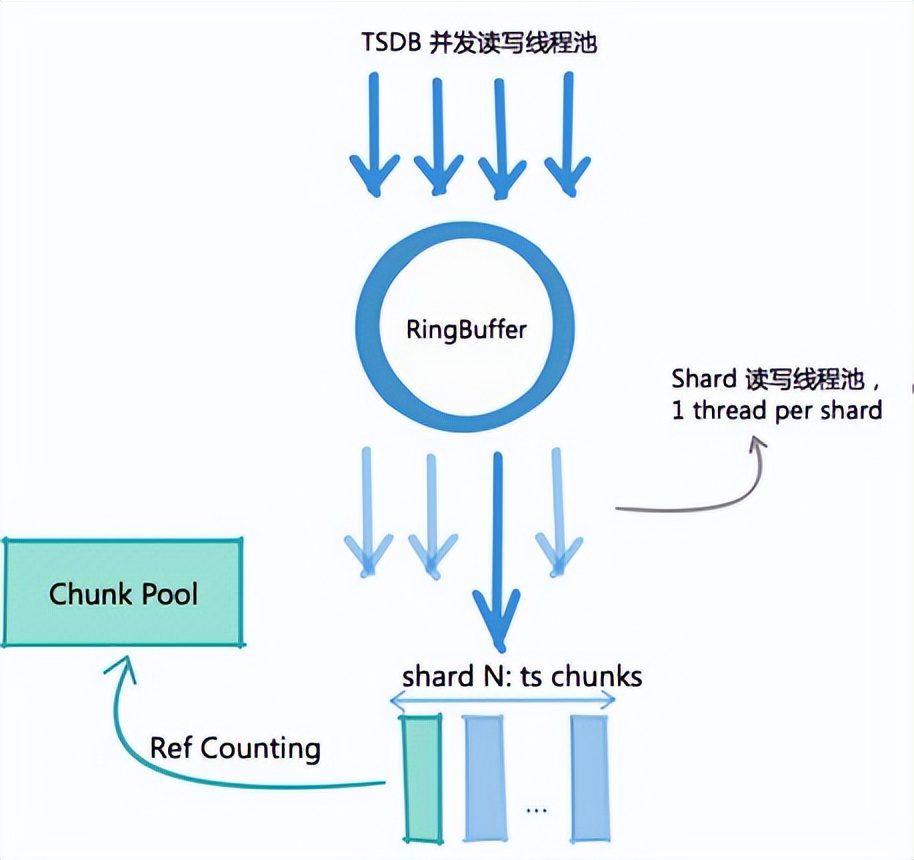
如图所示,TsMem基于Disruptor做一个RingBuffer,把用户读写的请求都暂存在RingBuffer中,采用多个生产者和一个消费者模式,一个消费者的请求会打到多个worker线程中,每一个worker线程又是一个分片,所以其实就是基于RingBuffer做了一个内存的分片,这样一来就是一个线程对应一个分片,这样就不会产生共享资源,也就无需考虑锁的实现。
把写和读都分配到一个链路上,一个worker同时处理读和写,提高读写性能
同时还利用了RingBuffer的batching特性,将用户的读写请求都暂存在一个butching中,然后当达到一定阈值或时间worker将直接提交一个batching,这样虽然会是请求有一定的延迟,但是大大提高了worker的吞吐量。
那么如何保证高效的内存管理和极低毛刺的延迟呢?
对于数据块基于引用计数的chunk池化管理,把所有的时序数据块在内存中做了池化,这样就能减少读取数据时临时对象的创建,而且还能避免大块时产生的抖动和延迟。
3.高纬聚合分析
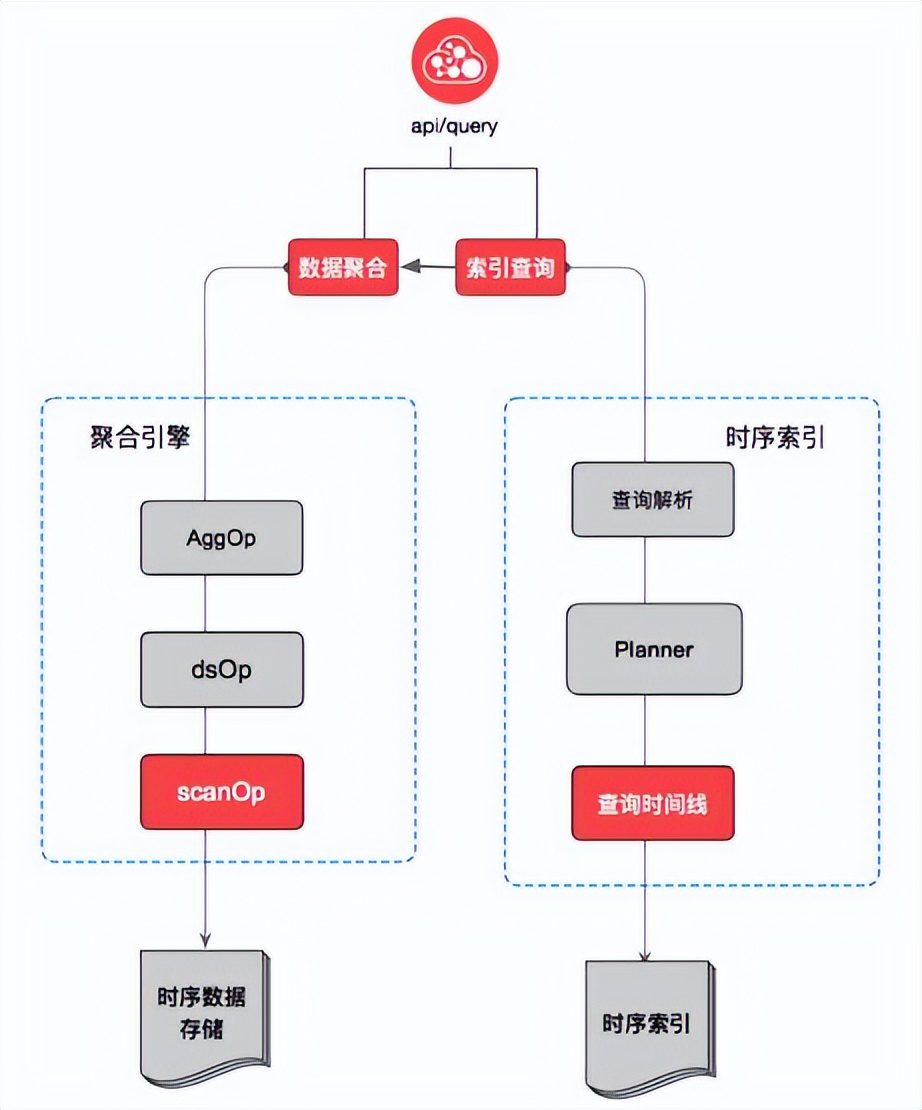
(1)TSDB引擎核心模块
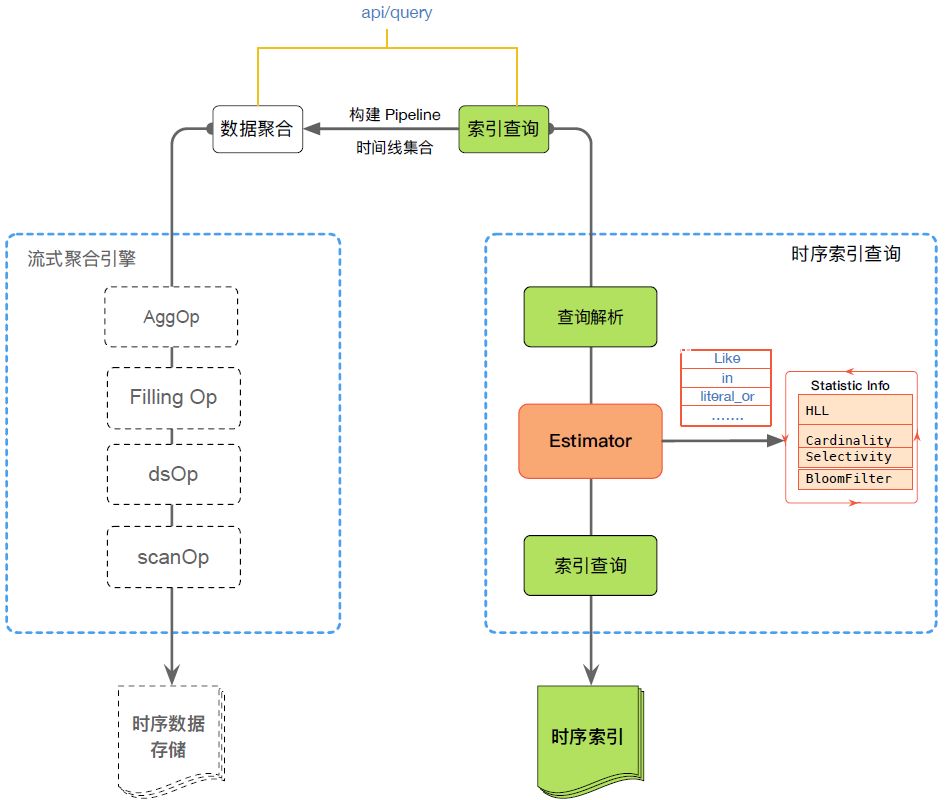
TSDB和核心模块主要包含两部分,分别是时序索引和流式聚合引擎,当用户的一个查询请求过来时将会由时序查询引擎返回对应的时序索引构建Pipeline时间线集合,然后再由流式聚合引擎计算出相应的聚合结果。
(2)时序索引
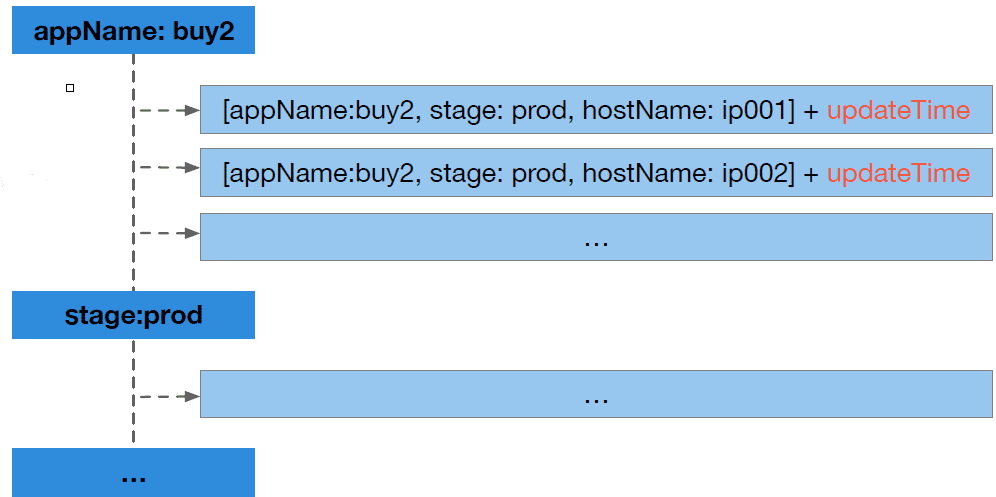
时序索引是什么?
本质是一个带时间戳的倒排索引,对数据进行倒排索引,然后在加上时间戳,这样当用户的请求过来时就可以根据用户的筛选条件获取数据的位置,然后再用时间线和时间戳进行二次过滤,这样提高了索引的命中率,同时也支持对时间线的TTL。
如何存储?
时序索引是基于kv进行存储,是一个无状态的节点,可以支持水平扩展。
(3)时序索引优化器

时序索引优化器主要是为了帮助用户在查询倒排索引的时候提高效率,这里优化器会对于用户的请求有三个处理:
- HLL计数器:根据用户的查询规则匹配历史的时间线数量,或者某个tag下的时间线数量;
- BloomFilter:根据布隆过滤器判断某个时间线是否存在;
- 时序索引缓存:直接查询缓存中是否已有相同的时间线内容。
优化器对于用户查询如何评估优化?
首先会根据用户的查询条件选取最小的集合进行计算,然后会判断查询的时间线是否存在,如果不存在直接返回,一些明确限定的条件优先于模糊的条件,例如等于肯定优先于包含。
(4)流式聚合引擎
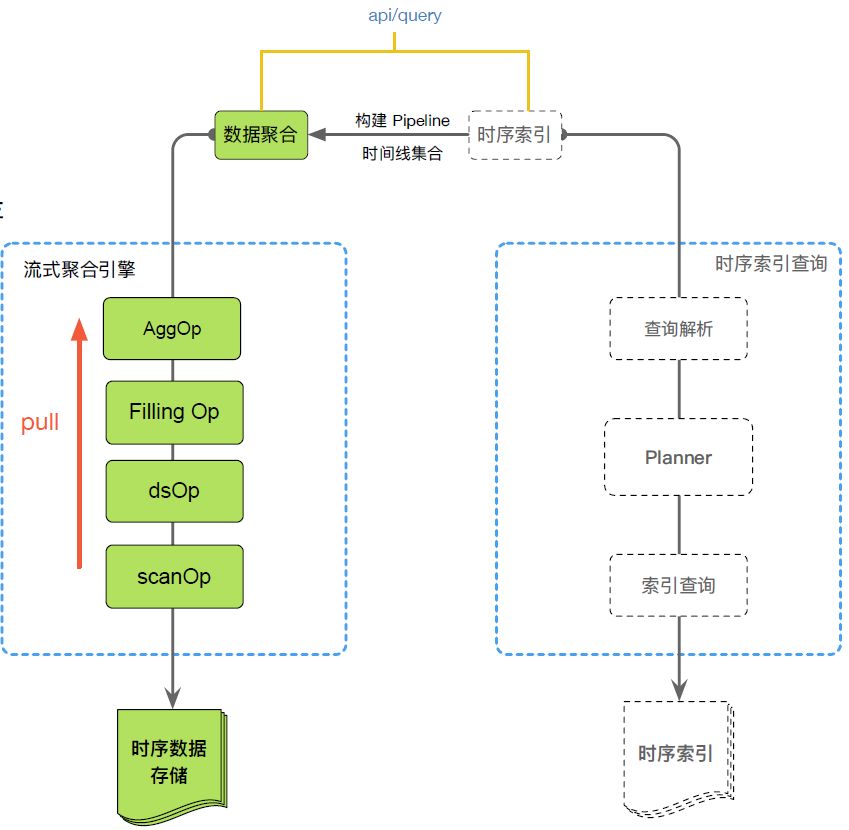
流式聚合引擎采用轻量单进程实现,在用户查询的时候将用户的复杂查询转换为聚合算子组合,流式聚合引擎包含了10+核心的聚合算子、20+填充策略、10+插值算法。
由于是将复杂的查询转换为算子组合运算,所以在实现上是一个松耦合的结构,扩展性很强而且每个算子的执行都非常高效,快速,减少了对内存的开销以及底层存储的压力,另外聚合出和数据还可以与外部预聚合、降精度聚合的数据实现无缝衔接,提高了查询结果的复用率。
4.稳定性保障
(1)TSBD稳定保障机制
TSDB不仅服务于专有云,更服务于公有云上的客户,因此稳定性是一个可以和内核提到同等层次的问题,TSDB从三个方面实现了稳定性的保障。
- 资源隔离
读写线程分离:保障了查询有故障时不会影响写入,写入有故障时不会影响查询;
慢查询、大查询的隔离:根据用户的查询条件生成一个指纹,在根据历史记录判断这个指纹是不是一个慢查询或者大查询,如果是的话会将这个查询放到一个单独的队列,这个队列的资源是受限的,而正常的查询会进入到正常的队列,这样一定程度上加速了整体查询的速度;
查询状态管理和调度:查询任务的状态管理和监控与任务的调度分离,这样降低了任务管理和调度的耦合性,提高了任务运行的稳定性。
- 基于时间线、时序数据的细粒度流控
每一份数据都通过倒排索引+时间戳的索引方式定位,保证用户的查询条件能更粒度的命中数据,减少不必须的资源消耗。
- 全面的监控指标
TSDB对整体的吞吐量、查询响应时间、IO层关键指标、以及各个核心模块都有详细而全面的监控,保证能实时的了解到TSDB内部发生了什么问题,继而快速的定位解决问题。
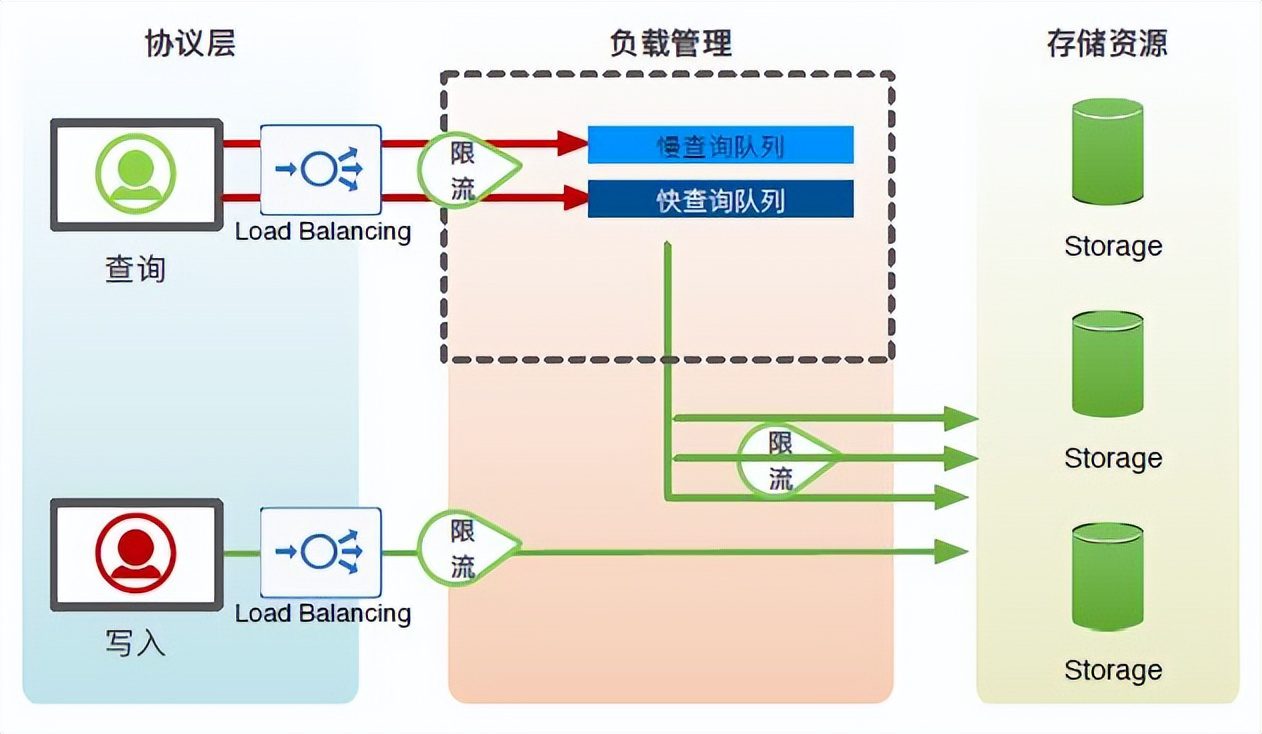
(2)TSDB工作负载管理
端到端的流控:在用户的写入接口会做资源的IO控制,两个核心模块时序索引、聚合引擎的入口层也会做一个IO流控,保证党用户的写入量或多或者查询量过大时,两个核心模块不收影响;
多维度的控制:从不同维度对TSDB的读写进行一些限制,例如查询的时间线过长、访问的数据点过多,读取的字节数过大、整个查询消耗的时间过长等等。
—
04
总结展望
前面已经介绍了TSDB的发展历程和解决的问题,下面将要介绍TSDB未来的发展方向及特性:
1. 冷热数据异构存储
随着时间的推移数据量会越来越庞大,为了降低用户成本一些不必要或者低热度的数据不需要按照现有的数据存储方式来保存,可以换成一种更低成本的存储方式。
2. 提高Serverless读写能力
- 提供能高频率、低延迟的查询
- OLAP系统长时间高纬度的分析
- 对于历史数据分析或者冷数据的分析
- 降低计算和查询的成本
3. 拥抱时序生态
将已有的时序引擎和计算引擎与业界很多成熟的时序生态,比如prometheus、kubernetes、openTSDB等结合,为用户体用更好的解决方案。
4. 时序智能分析
为用户提供更多稳定、可靠的智能分析模型,深入行业内部了解一些用户的痛点,解决一些亟待解决的问题。
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/product/66820.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫