
有人问我一个很“实在”的问题,分析和优化用户运营,有哪些模型。
我把一些常用的模型一一简单介绍之后,忽然发现,这已经可以写一本书了。不过,写一本书的时间可能不够,但写一篇文章还是完全可行的。
因此,正好把这些年来做过的和所想的模型与方法,跟大家简要介绍。当然,文字表述终究有限,绝知此事要躬行,还是建议大家从真正的实践中验证模型,甚至找到自己的模型。
另外,在下面的这些模型中,我难免不带着“批判的”眼光去看待这些模型,因为没有完美的模型,任何模型均有适用范围和缺陷,真正可用的模型,永远来自于你自己的业务。
这13个模型分别是:
第一类:运营思维模型
- AARRR
- AIPLA
- MOT
第二类:客户认知模型
- RFM
- 自定义聚类
- 用户活跃度模型
- 用户偏好识别模型
第三类:运营增长模型
- 留存曲线
- Cohort模型
- 增长曲线
- K因子
- 流失预警模型
- 诱饵、触点与规则模型
第一类:运营思维模型
运营思维模型是那些“非常正确”但并不能让你立即采取行动的模型。不少人对这些模型存在“意见”,正是因为他们很正确却又“无法落地”。另有聪明的朋友可能会觉得,这些模型都是“马后炮”,这不就是我日常策略的总结嘛。话虽如此,这些模型仍然是对成功策略的简单精辟的总结。
1.AARRR模型
AARRR模型的适用范围往往在数字化产品和服务端,但对传统业务也有启发。但我过去几乎都是忽略这个模型不讲,因为这个模型最大的问题在于,它给出了一个“正确的废话”,却不能告诉叫你究竟应该怎么做。
AARRR的含义是:引流-激活-留存-变现-推荐。后面三个的顺序有争议,不同的人有不同的解释。总体来看,这个模型的实质仍然是:引流-互动-转化-留存-推荐,是对客户正常的忠诚周期中一步步转化进行描述的模型。
很多人认为这个模型是“新瓶装旧酒”,但事实上,这个模型强调了过去比较少强调的客户经营策略,例如,它强调“激活”,也强调“推荐”,这是在数字世界中更容易实现的用户策略,而在传统世界中则相对较难。
但事实上,近年来很多成功的数字经济下的客户增长,是否本质符合AARRR模型,也存在争议。例如,相当多的声音质疑“小蓝杯”和“小黄车”之类的增长模式并不符合真正的AARRR模型,只会对运营者有更大的误导。对于“小蓝杯”,最大的争议在于它的增长并非来源于“自推荐”,而是来自于“利诱推荐”,即以亏损作为代价进行补贴,换取用户数量后在资本市场实现变现的操作模型。“滴滴”某种程度上也是这样的模式——这造成了滴滴直到今天仍然严重亏损。“小黄车”的问题则在于它的用户增量虽然确实来自于运营,但这运营的核心在于提供更具有竞争力的产品(更好骑的车辆+更广阔的覆盖),而通过推荐(Refer)所带来的用户增长则非常有限。
Facebook和Linkedin常常被作为AARRR的典型例子传播,但容易被忽视的一点是,Facebook和Linkedin都是具有强烈的“网络效应”的产品,因此推荐(Refer)就不再仅仅是一种运营策略,而是由其产品的先天基因所决定的。这是大多数今天的数字产品想要拥有,却无法根本拥有的特性。那些天生拥有这样特性的产品,今天早已被开发殆尽。例如七八年前的微信,或是更早的淘宝。
那么,我们要从AARRR模型中学到什么?它是否并不能真正有效指导我们?并非如此,这个模型是一个类似于“check list”的思想,告诉了我们应该将运营工作分为五个需要深入思考的部分,以及这五个部分之间可以通过运营构建起相互的关联。当然,在这个模型中肯定并未告诉你应该怎么做到,因此,需要更具有操作性的模型才能实现AARRR的思想所倡导的结果。在本文后面,我们会介绍具体的几类更具操作性的模型。
2.AIPLA模型
如果数字世界中强调AARRR,那么传统世界的用户运营模型则是AIPLA,即Awareness – Interest – Purchase – Loyalty – Advocation(认知-兴趣-购买-忠诚-拥护)。仅从字面上看,你就会发现这个模型简直跟AARRR模型没有什么本质差异。AIPLA描述了传统世界中客户的转化过程,即从对产品有所认知,一直到成为“死忠粉”的全过程,并强调在此过程中各个阶段应用不同的运营策略。
的确,AIPLA模型被广泛提及,例如,阿里的品牌数据银行的主逻辑,就是AIPL(没有A),腾讯数据智库(TDC)也是如此,只是换了同义词表述而已,本质没有变化。



尽管看起来几乎一样,但AIPLA与AARRR还是有所不同,在于AIPLA强调客户从一端(Awareness)到另一端(Advocate)的有序的线性过程,而AARRR中的RRR则完全可能是无序的。例如,你的用户完全可以不购买你的数字产品,但仍然可以非常忠诚地使用你的产品或跟人推荐你的产品,这在传统世界中这几乎是不可能的。因此,传统世界中的AIPLA模型更强调首尾衔接的过程化的运营,而数字世界中的AARRR则更多单点的激活策略。
也正是因为上面的现象,导致传统世界的客户深度运营相对于数字世界而言总体更困难。这也是为什么传统领域纷纷需要“数字化转型”的一个重要的原因,大家需要把线下的运营线上化,从而更能够深入运营客户。
AIPLA模型应该怎么落地?这个模型同样属于“思维方式”模型,落地则需要其他工具的帮助。我们后文介绍。
3.MOT模型
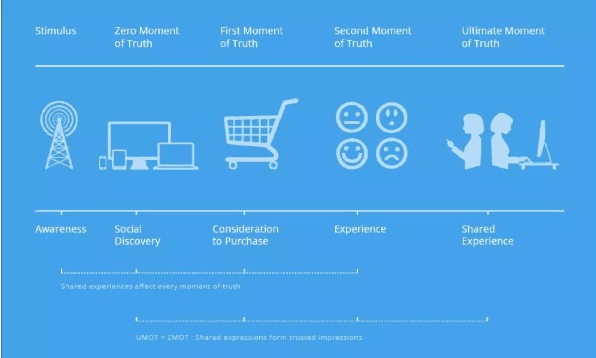
消费者旅程的核心思想——无论它的表现形式是AARRR,还是AIPLA——都将消费者的购物行为描述为从认知到兴趣,再从兴趣转化为购买,以及从购买转化为忠诚的一连串先后发生的过程。这一过程被称为消费者旅程。
消费者时刻(Moment of Truth,简称MOT)是消费者旅程中的一些关键“里程碑”似的节点。例如,搜索某个产品,又或者把这个产品的信息分享给其他人。这个概念最初来源于宝洁。
你可以发挥想象——一个客户在其消费旅程的全过程中,就像或明或暗若隐若现的一条弯弯曲曲的道路,而MOT就像这个道路中间燃烧的火把,指引着这条路的方向。
我们无法直接控制消费者旅程,但能透过MOT来对消费者旅程施加影响。甚至很多时候,我们也无需参透消费者旅程到底是什么,我们只是在设计MOT,对这个消费者施加影响,从而让他快速切变到下一个更接近于转化的MOT或者甚至是转化本身。
MOT中又有一类是非常重要的,即ZMOT(Zero Moment of Truth,原初MOT),意思是在某种情况的刺激下,一个人最初的一个心理上的活动,让他意识到他需要购买某个东西或者服务。对于Google而言,这个心理上的活动体现为在搜索引擎上进行搜索。对于阿里而言,这个心理活动起始于一个人开始了一个一段时间内从未有过的某类商品的搜索。
另外一个MOT是UMOT(Ultimate Moment of Truth),即最终的MOT,人们在整个购物历程中的最后一个关键时刻,往往就是把自己的商品体验分享出去的时刻。ZMOT和UMOT的思想来自于谷歌。
第二类:客户认知模型
与第一类模型不同,第二类模型是可以让我们实际操作的模型,并且基于这些操作,我们可以更深入的了解客户的情况,从而为我们的运营策略提供依据。
1.RFM
RFM模型的核心用途是对所有的客户进行价值衡量,然后对这些客户进行分类。因此,本质上这个模型是一个非常简单的分类模型。

你可以想象你是一个农场主,苹果丰收了,你想把苹果分为不同的类别定价售卖。于是你制定了分类方式:苹果的“肤色”、苹果的大小,以及苹果的口味。红色的大苹果且脆甜的属于一类,绿色的大苹果且粉甜的也属于一类,这样大概可以分出8类苹果。然后按照各种类别的苹果进行标价。
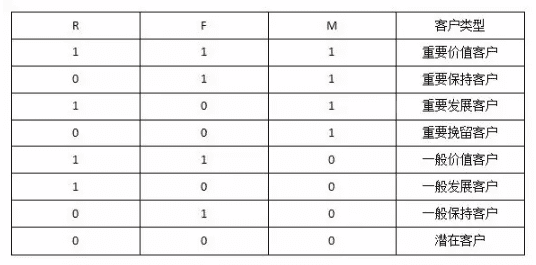
RFM就是这样的道理,三个字母就代表了三个分类标准:R和F和M。R即发生购买的日期的临近度,R的值越大,表示交易是越靠近现在发生的,否则则是更久以前发生的。F是购买频次,F越大,说明交易的次数越多。M则是交易金额,M越大,金额越高。
RFM三个标准,往往用数据代笔的程度表示,比如R用1、2、3表示,3表示最近购买,1表示很久以前购买,2则表示在中间阶段。如果用最简单的0和1表示,则同样可以把自己的客户分为8类,如下表所示:
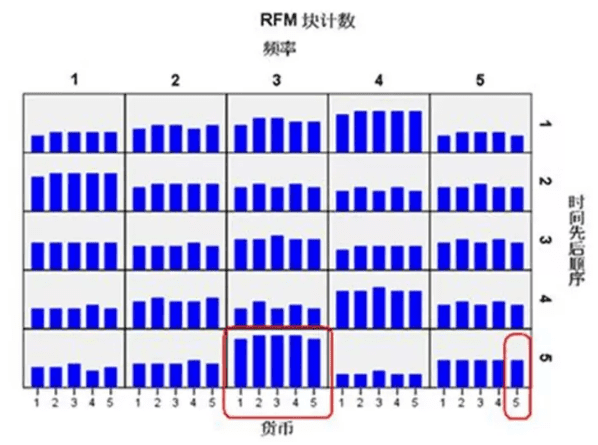
当然,你也可以把每个标准都设定5个档次,那么就会有5的3次方供125个类别的客户,如下图所示:
对于不同类型的客户,立即可以有不同的运营策略。比如,对于重要挽留客户,需要做的事情,就是AARRR模型中的第二个A,即激活。至于如何激活,则需要用到另外的模型,也就是我们后面要介绍的“诱饵、触点、规则”模型。
RFM主要是用在零售行业中,它并不是对所有行业都有用,原因很简单,因为RFM的R和F对很多行业而言并不存在。比如,学历教育,F可能永远都只有1次。
但对于存在高频用户互动的行业,RFM的思想却很有用,即使这个行业并不追求立即的转化,也就是不太在乎短期内的M,RFM仍然可以使用。例如,对于信息流媒体,它并不需要用户在信息流上买东西,同样可以用RFM衡量用户的价值,无非是把M换成另外一个度量,比如阅读新闻的时间即可。
RFM价值很大,一方面是它几乎是最容易操作的模型(用excel做一个条件即可),另一方面是它具有很强的适应性。但它的弱点也很明显,对于客户的分类不够精细,它提供了一个衡量客户“重要度”的线索,但除此之外,缺乏更深入的用于帮助运营的信息。
2.自定义的聚类
自定义的聚类与RFM的思想本质上是一致的,区别在于,自定义的聚类是自己选择标准去给现有的客户做分类。
自定义的客户聚类的目的是为了弥补RFM的短板,毕竟不是所有的业态都是零售业,而且也并不是所有的业态都适合于用简单的层次划分来区隔客户。
自定义的聚类可以自己选择任意合理的标准(也就是变量)来聚类客户,并且可以不止三个标准,你甚至可以扩展到十个以上的标准。不过,这个方法显然不能简单利用excel就能做到,而是需要利用数据建模(聚类本身就是一个数据处理的模型)才能完成,例如使用SPSS或SAS工具。
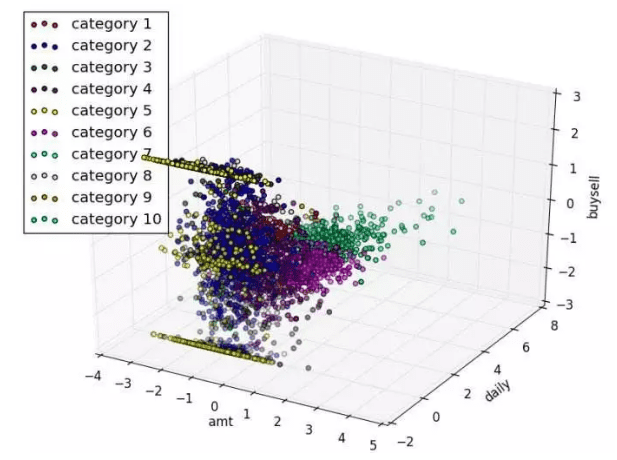
自定义聚类的优点在于灵活,但也有缺点。聚类模型的算法,如果不加约束,往往会聚类出远超出你的想象的数量的客户群,如果你真的用十个以上的标准,可能会聚类出上千个客户群,这样你就无法对这些群体进行解读。
最佳实践方式是,选择3-4个与客户的行为或运营的成败最相关的标准即可,然后约束生成聚类的群体的数量,最好10个以内,是容易被处理和理解的。
3.用户活跃度模型
与自定义的聚类一样,用户活跃度模型也是一个完完全全的自定义的模型。这个模型有另外一个名字,即engagement index。
Engagement index的价值在于衡量不同客户(用户)的活跃度,这个模型与前面的聚类或者RFM的最大区别在于,它完全不care用户最终是否发生了购买行为,而仅仅只看用户使用你的产品或者与你互动的强度。
建立用户活跃度模型并不困难,因此它也是一个极有使用价值的模型。具体方法分为几步:
- 对所有的消费者触点平台加监测代码,对所有消费者交互的位置进行埋点,以确保消费者的行为能够全部被记录;
- 对不同的消费者交互根据其价值构建权重;
- 对每个消费者的总互动行为根据权重计算分值。
权重的设置有一定的技巧,一种方法非常主观,但实际上却很有作用,即,直接根据对于消费者行为价值的经验性判断,来给不同类型的消费者互动打分。另外一种,则是根据各行为与最终转化之间的比例关系进行权重设置。
比如,一个最理想最极端的例子(但这样的例子有助于大家理解),如果你认为最终的一个转化价值1000分的话,那么转化之前的用户的行为可以按照与转化发生的比例“打分”。例如,每发生1次转化,就需要看商品介绍页面100次,那么查看商品介绍页的行为每发生一次,就值10分。
用户活跃度模型的缺点在于,必须利用用户行为分析工具进行埋点,并且有些工具不支持自动化的用户活跃度打分,此时你就必须导出数据自行计算。nEqual的及策(Jice)工具支持这一功能,这也是为什么我认为这个工具具有亮点的原因。
几乎所有的高频次客户(用户)互动的业态,都可以使用用户活跃度模型。用户活跃度不仅用来衡量用户的价值,也用来衡量流量的质量,所以是非常重要的模型。在我的大课堂中有大量的内容和案例介绍它及它的应用。
4.用户偏好识别模型
用户偏好识别模型是一个历史悠久且极有价值的模型。这个模型实现较为复杂,需要利用算法实现。
实现对用户的偏好进行分析和识别的算法与用户活跃度模型实际上有关联,即都是利用用户具体的行为进行判断,区别在于后者只是判断活跃度,而前者还要判断人们因为什么(偏好)而活跃。
用户偏好识别模型取决于算法,可以很简单,也可以非常复杂(但可能具有更高的精度)。例如,仅仅只是用一个维度,即“点击”行为即可以作为用户兴趣的特征,然后建立商品(或内容)与行为之间的二元矩阵,即可以求解用户偏好,但这种方式非常粗糙。
如果考虑除了点击之外的更多的行为,例如收藏、点赞、评论、购买等,那么就需要对用户的不同行为加权,此外,如同RFM模型一样,再将行为发生的次数和新近度也考虑在内,那么整个算法就会变得更加复杂,却更加准确。
当然,有没有不需要算法的用户偏好识别模型?也有,问卷调查就是。只不过,范围太小,效率也太低下了。
用户偏好识别模型的意义非常巨大,即,通过用户的行为判断用户的兴趣,从而给予实际的运营工作以巨大的支持。用户偏好识别模型也是推荐引擎的基础之一。当然,它也是DMP和CDP这样的消费者数据平台给消费者打标签的基础。在我的大课堂中,会详细介绍。
第三类:运营增长模型
运营增长模型对于运营工作具有直接的指导意义,也是我个人认为每一个运营人都应该熟练掌握的模型。
1.留存曲线
留存曲线是最简单的用户运营增长模型。即,它将留存率(或者留存数)按照线性的时间进行排列。
一个最简单的excel就能表示留存曲线的情况。比如,下图:
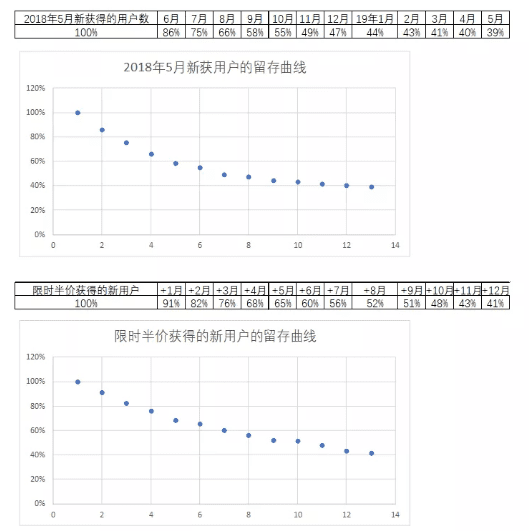
留存曲线一般是由留存率组合而成,这样不同基数的群体也可以相互比较。留存率的反面(用1减去留存率)是流失率(churn rate)。

流失率 = 1 – 留存率
留存曲线的斜率是另一个值得关注的指标,而且是一个很有意思的指标。显然,斜率越高,用户或者客户的留存情况越不理想。对于不同的生意类型,留存曲线的斜率极限是多少呢?
游戏、社交等高频app很关注次日留存率、十日留存率和月度留存率,一般而言,次日留存率应该在30%以上,或者说低于30%就很危险。它们的十日留存率的极限是不能低于15%,月留存率的极限不能低于10%。
快消品的电商则更多看月度留存率,其留存曲线的斜率与品类有很大的关系。如果是什么商品都卖的卖场类电商平台,次月留存率(指当月发生购买,次月也发生购买的人占当月总购买人群的比例)保持在10%已经相当不错。
总体看,业态和商品,以及营销策略只要有一点区别,留存率就会很不相同,因此,很难有一个行业标准值,比如符合某一个数值就能“生”,达不到某一个数值就会“死”。但你仍然可以从留存曲线中看到自己生意是否成功,因为,你很容易在你的当前留存曲线情况下计算未来这群人的收入,并且计算出真正的ROI,例如下面这个例子。
假设你为了获取当月新增的用户,付出了500元的成本,而这些新增用户当月已经给你带来了1000美元的收入。假设每个月这些用户的购买倾向都没有发生明显变化,那么未来若干个月,这些用户中留存的人肯定还会继续购买,并且购买的金额随着流失的比例而同等下降。
如下图:

500元的投入,换得未来7430元以上的收益,感觉是相当不错的运营成绩。
2.Cohort模型
我在多处都强调过Cohort模型的价值。Cohort模型最重要的作用就是分析不同客户群体的留存情况,从而帮助分析更好的留存是如何产生的,并指导运营提升留存。
Cohort本质上就是不同类人群的留存曲线的堆栈。

Cohort模型的优点在于,你可以只用excel就完成全部的建模,而且加上excel的“条件格式”的“色带”功能,简直好用极了。如下图所示:
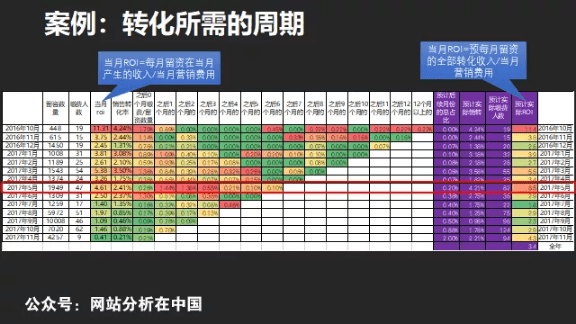
Cohort分析还没有一个所有人都统一使用的翻译。有的说是同期群分析,有的说是同类群分析,有的说是队列分析,有的说是世代分析,有的还说是队列时间序列分析。
无论哪种叫法,cohort分析在有数据运营领域都变得十分重要。原因在于,随着流量经济的退却,精耕细作的互联网运营特别需要仔细洞察留存情况。Cohort分析最大的价值也正在于此。Cohort分析通过对性质完全一样的可对比群体的留存情况的比较,来发现哪些因素影响短、中、长期的留存。
Cohort分析受到欢迎的另一个原因是它用起来十分简单,但却十分直观。相较于比较繁琐的流失(churn)分析,RFM或者用户聚类等,cohort只用简单的一个excel表,甚至连四则运算都不用,就直接描述了用户在一段时间周期(甚至是整个LTV)的留存(或流失)变化情况。甚至,cohort还能帮你做预测。
除了用Excel的纯粹数字化的表示,cohort一样可以用图形化的方式来表达。例如,下图中展现了每个月在随后若干月的留存用户数量(面积图),以及每个月的总用户数量(红色的粗线)。这个图比较直观的反映了,在2018年3月份的新用户,留存情况要显著优于其他月份。

Cohort模型非常重要,因此在我的大课堂会做详细的介绍,以及具体的应用案例。
3.增长曲线
增长曲线有J和S型两种。以及影响增长曲线构型的外部因素K。
增长曲线模型来自于生物界研究,即研究一个物种的扩张能力究竟有多强。如果没有外部环境的压力(食物竞争、天敌、生存环境不变且不会因为数量增加而恶化等),那么显然物种会成几何级数量增长,就跟细菌分裂一样。这会产生一个J型曲线。否则,则是S型曲线。
今天我们能够看到的增长,基本上都是S型曲线。而,为了让S型曲线能够向J型方向移动(这是所有运营人的梦想),必须改变外部的环境K。简单讲,运营工作的核心,就是改变K。
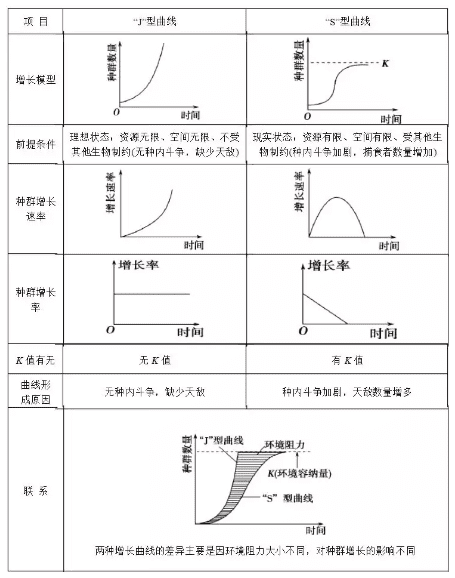
实战中增长曲线应该如何使用?坦率讲,增长曲线并不是一个非常能落地的模型,或者说,它属于一个“相对比较理论化”的模型。这个模型更像是一个衡量好坏的指标,CEO可能会非常喜欢,尤其是看到用户的增长曲线走出一个类似“J型”的时候。但这个曲线能够多大程度指导深度运营?确实非常有限。
下面这个曲线,是某微信公众号用户增长的曲线,看起来进入2019年之后,增长情况好于过往。
4.K因子
K因子是一个很容易理解的模型,或者说它是一个很简单的指标,用来衡量“裂变”和“病毒传播”(这两个名词本质上没有区别),即一个发起推荐的用户可以带来多少新用户。
K因子以1为分界线,如果大于1,那么传播会越来越扩张,像细胞分裂一般。例如,癌细胞,因为癌细胞短时间内只会分裂不会死亡,因此它的K因子值是2。K是2的情况已经非常吓人。但如果你的产品,一个人能传给百个人,并且能按照这个比例一直传下去,那么K可能等于100。
最需要把K因子作为KPI考核的生意是“传销”,因为它一旦K大于1,就能聚敛巨大的财富。不过它是违法的。
我们大部分看到的内容传播,或者裂变玩法的K值都会很快小于1。唯有用金钱刺激并无限层级返佣的传播活动才容易让K大于1,但这等同于传销。
计算K因子值很简单,例如下图
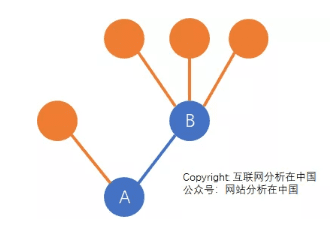
A发起了一次推荐,结果带来了B和另外一个用户。然后B也发生了一次推荐,又带来了三个用户。不过橙色标记的用户都没有发生推荐行为,也就没有产生新的用户。
这个简单的传播过程,K因子值是2次推荐,产生了5个新用户(因为B也是新用户),K因子=2.5。
下图则是另外一种情况,有ABCD四个原生用户,他们都发起了推荐,可是只有A人缘好,带来了两个新用户,但这两个新用户都没有发起推荐。C人缘也凑合,带来了一个新用户。C带来的新用户E也发起了推荐,可惜并没有产生更多用户。因此,K因子值是5次推荐,只产生了3个新用户,K因子=0.6。

djust统计了大量的app的K因子,他们最终发现K因子的确在app中存在,但并不适用于当前市场上的大多数app。
Adjst在30%的样本中发现了K因子。在这些样本中,数据团队得出K因子的中值为0.45。这意味着(按照样本中值的应用运行情况)每100个付费安装将带来45个额外的自然安装。而这仅仅是中值,样本中有些应用收获了数百,甚至是数千次额外安装,但也有很多app完全没有任何用户推荐产生的安装。
K因子本身在实践中更多帮助我们衡量传播,尤其是裂变传播的效果。而关于营销传播以及裂变传播的数据化策略与方法,在我的大课堂中将会详细为大家介绍。
5.流失预警模型
严格来讲,流失预警模型不能算是一个模型,而更像是一个数据挖掘方法。流失预警常用决策树来进行数据挖掘,基于历史上的流失人群,根据附着在他们身上的各种变量计算他们的特征,然后将这些特征放在不同时间段的其他流失数据中进行验证,从而得到一个预测模型。
流失预警大量应用于游戏、零售、订阅服务、SaaS类型的软件产品等行业。由于涉及到数据挖掘,太过于技术和操作性,具体的内容本文就不再多介绍了。我在大课堂上同样将会对它进行介绍和解释。
6.诱饵、触点与规则模型
这个模型并不是直接的数据化模型,但却是用户深度运营的极为重要的方法模型,同时需要全程利用数据才能落地,因此也将它放入数据模型之列。该模型最早由纷析咨询(Fenxi Data)提出并使用。
这个模型强调在所有细节的运营工作都由“诱饵、触点和规则”三个要素构成。运营策略的核心,就是在这三个元素上进行设计。
例如,2017年某KOL代言宝马Mini的活动,就是诱饵、触点和规则的统一。诱饵,当然是限量版特殊颜色的Mini,以及更便宜的价格;触点,是这个网红,以及微信公众号平台;规则,则是先到先得。所以在短时间内销售了100台。
但这个案例只是一个简单的例子,今天的运营远比网红带货要复杂。例如,下面展示了一个2B业务的“全客户生命周期”的“诱饵、触点和规则”的策略,因为保密的关系,我们无法展示所有内容,但大家已经可以意会。
为什么这个模型会将“触点”也作为一个重要的元素,原因在于,唯有触点能够作为追踪用户的数据载体,从而为我们建立用户偏好识别模型。而这些标签,又进一步帮助我们选择“诱饵”以及建立更合理的“规则”。
这个模型十分具有操作性,限于篇幅关系,不再赘述。
上面所列举的一共13个模型,欢迎大家参考。
文:宋星@网站分析在中国(chinawebanalytics)
宋星,系国内领先的互联网数据咨询机构“纷析咨询”创始人。
宋星是数据化互联网营销与运营最资深的从业者和行业意见领袖,阳狮媒体集团特聘顾问,百度集团顾问与钻石讲师,腾讯星河计划顾问,Google mLab顾问,北京航空航天大学特聘教授,前阳狮媒体集团数据、技术与创新事业部总经理,前Adobe Omniture Business Unit亚太区首席商业咨询顾问。
首席增长官CGO荐读市场营销:
更多精彩,关注:增长黑客(GrowthHK.cn)
增长黑客(Growth Hacker)是依靠技术和数据来达成各种营销目标的新型团队角色。从单线思维者时常忽略的角度和高度,梳理整合产品发展的因素,实现低成本甚至零成本带来的有效增长…
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/user/22570.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫