
在互联网红利逐渐消失的当下,粗狂式的运营已经难以为继,如何把有限的费用投入到我们最精准的用户上,也就是所谓的精细化运营,是每个公司应该关注的问题。这其中最重要的是用户分层,本文介绍了用户分层的一种最常见、也最常见的方法:RFM用户分层。
一、写在前面
随着互联网流量红利的逐渐消失,之前粗狂式的拓客和一刀切的用户运营已经难以为继,越来越多的公司开始意识到,只靠烧钱圈用户、养用户成本太高,因为不是所有的用户都需要你重点投入,金主爸爸一定要好好维护,潜力股一定要加大投入挖掘价值,而羊毛党永远都是你应该严防的对象,这就是所谓的精细化运营,钱要花在刀刃上,要花在业务和核心用户上。
精细化运营讲究的是千人千面,一千类用户一千种运营策略,所以第一步就是要把用户进行分类,然后才有针对性的运营策略,而用户分类中一种尤为重要和常用的方法就是RFM。
二、什么是RFM?
什么是RFM?RFM最早产生于电商领域,根据客户的交易频次和交易额衡量客户的价值,对客户进行细分。
RFM是衡量客户价值的三个维度,分别为R(Recency)交易间隔、F(Frequency)交易频度、M(Monetary)交易金额组成。
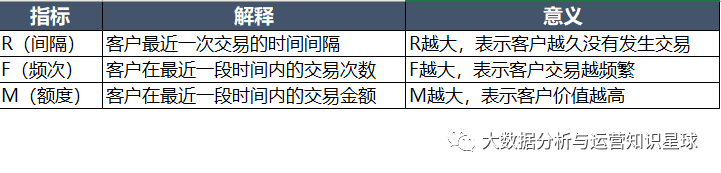

R表示间隔(Recency):也就是客户最近一次交易距今的间隔,需要注意的是,R是最近一次交易时间到现在的间隔,而不是最近一次的交易时间,R越大,表示客户越久未发生交易,反之R越小,表示客户越近有交易发生。
F表示频次(Frequency):也就是客户在最近一段时间内交易的次数,一般来说选取一个特定的时间段,F越大,表示客户交易越频繁,反之F越小,表示客户不够活跃。
M表示额度(Monetary):也在同样的时间段内,客户交易的金额,M越大,表示客户价值越高,M越小,表示客户价值越低。
有了以上3个维度的数据,就可以对每个用户按照每个维度进行衡量,一般来说我们会选取一个合理的分值对R、F、M进行划分,将3个维度分别分为高、低两类,组合下来就是8类,也就形成了8个用户群体。
当然你说我每个维度分成3类行不行,最终分成27个用户群体不是更精细,当然没问题,但是我们能不能给出27种不同的运营方案,如果给不出,如此细分不就是自嗨么?
毕竟,分为多少个群体不重要,每个群体都要有个性化的运营策略才重要。
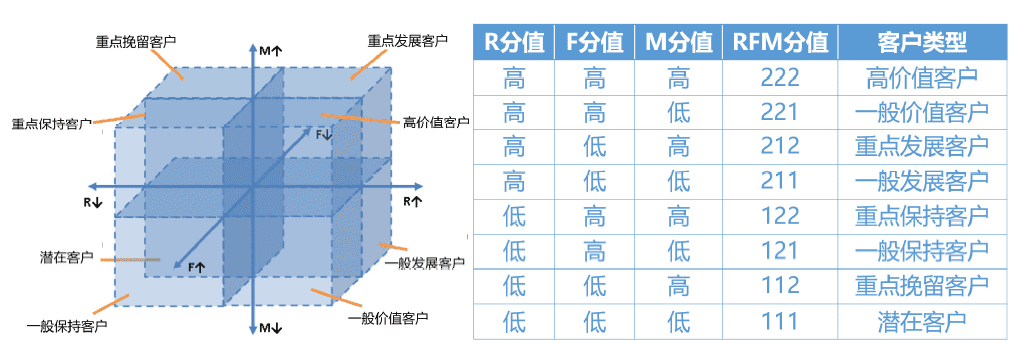
下面是一张经典RFM客户细分模型图,R分值、F分值和M分值三个指标构成了一个三维立方图,在各自维度上,根据得分值又可以分为高、低两个分类,分别用2、1表示,最终3个指标两两组合,就构成了8大客户群体。
对每个用户群体进行定性,例如R、F、M分值高的客户为重要价值客户,R、F、M三个分值都低的客户为潜在客户,其他类型客户可以此类推解读。
三、RFM实际案例
RFM的原理到这里就讲完了,是不是很简单?确实很简单,但是也确实很实用,在实际的工作中是如何实施这个用户分层模型的呢?下面我们就用一个实际的案例手把手教你如何进行RFM用户分层。
整体来说,RFM模型实施需要以下几个关键的步骤。

1. 数据准备
下面通过一个实际的案例学习RFM分析的使用,案例是用python做的,当然了Excel也能做,不必纠结于工具哈,首先将数据导入到data变量,代码如下:
import pandas data=pandas.read_csv(‘./RFM分析.csv’,engine=’python’)
可以大致看一眼data数据的样式,如下图所示。
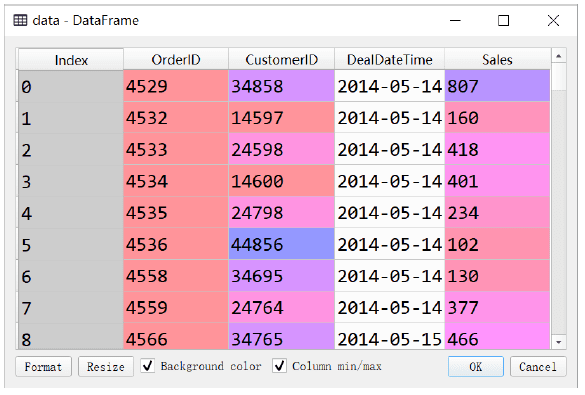
可以看到,这里记录的是客户的每一个订单的信息,第一列为订单ID,第二列为客户ID,第三列为交易日期,第四列为交易金额。
对数据进行一下加工,根据交易日期,计算出每次交易距今的间隔天数,代码如下:
#将交易日期处理为日期数据类型
data[‘DealDateTime’]=pandas.to_datetime(data.DealDateTime,format=’%Y/%m/%d’)
#假设2015-10-1是计算当天,求交易日期至计算当天的距离天数
data[‘Days’]=pandas.to_datetime(‘2015-10-1’)-data[‘DealDateTime’]
#从时间距离中获取天数 data[‘Days’]=data[‘Days’].dt.days
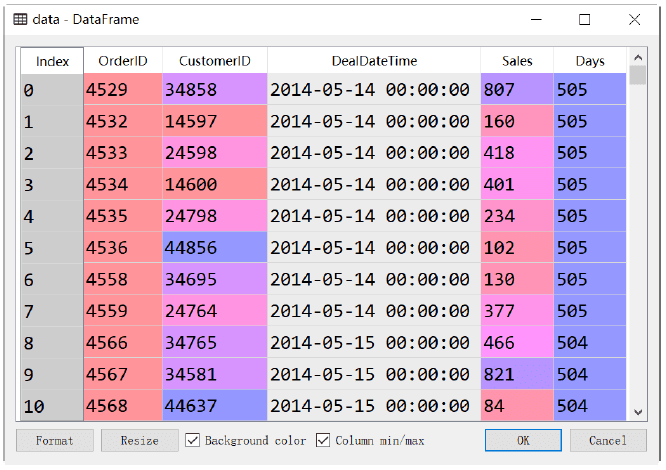
执行以上代码,即可得到用户每一次交易日期距离指定日期的天数,如下图所示。
2. 计算R、F、M
用户的明细数据准备好后,接下来就可以计算每个客户的最近交易间隔R、交易频率F以及交易总额M,计算方法如下:
最近交易间隔R:使用CustomerID作为分组列,距离指定日期间隔天数Days作为聚合列,统计函数使用最小值函数min,即可得到每个客户的最近交易间隔R。
交易频率F:使用CustomerID作为分组列,OrderID作为聚合列,统计函数使用计数函数count。
交易总额M:使用CustomerID作为分组列,订单金额Sales作为聚合列,统计函数使用求和函数sum。
对应的代码如下:
#统计每个客户距离指定日期有多久没有消费了,即找出最小的最近消费距离
R=data.groupby(by=[‘CustomerID’],as_index=False)[‘Days’].agg(‘min’)
#统计每个客户交易的总次数,即对订单ID计数
F=data.groupby(by=[‘CustomerID’],as_index=False)[‘OrderID’].agg(‘count’)
#统计每个客户交易的总额,即对每次的交易金额求和
M=data.groupby(by=[‘CustomerID’],as_index=False)[‘Sales’].agg(‘sum’)
执行以上代码,得到的结果如下图所示。
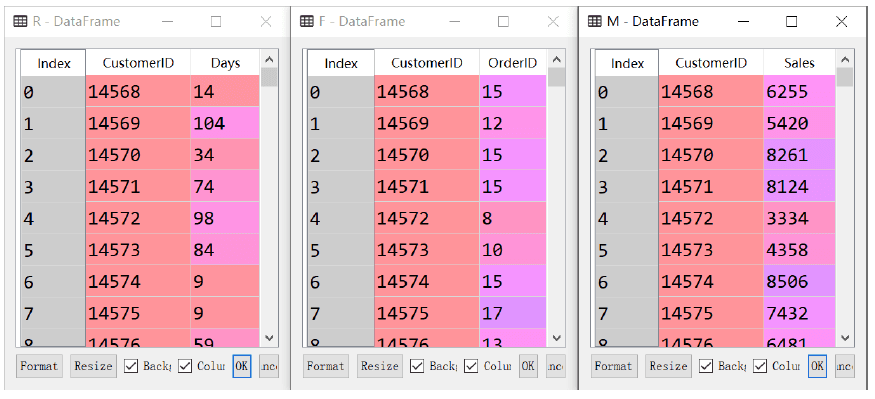
接下来使用merge方法,将R、F、M三个数据在客户CustomerID维度上关联起来,因为它们拥有共同的列名,在这种情况下,on参数可以省略不写,代码如下:
#将R、F、M三个数据框关联,merge默认内连接,可省略,两表on条件的关联列名均为CustomerID
Data=R.merge(F).merge(M)
#修改列名 RFMData.columns=[‘CustomerID’,’R’,’F’,’M’]
执行以上代码,得到的结果如下图所示。
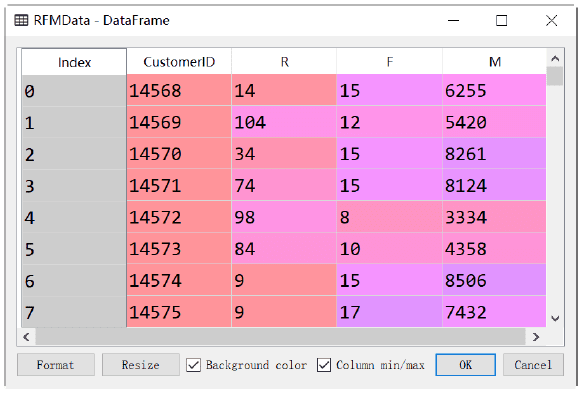
3. 计算R、F、M综合分值
每个客户的R、F、M数据计算好后,接下来就可以对R、F、M这三个维度进行分组打分赋值,得到对应的R分值、F分值、M分值。
打分标准可以按照业务经验、平均值等标准进行划分。最好是按照业务经验划分,因为这里分类的的用户是要到后面进行精细化运营的,可以通过已有的运营策略反推这里的划分阈值。
当然,如果还没有特别清晰的运营策略,也可以采用平均值进行划分。本例将R、F、M三列分别按照各自的平均值划分为高、低2个组,并分别赋值1分、2分。
R分值(R_S):距离指定日期越近,R_S越大,R>=平均值,R_S为1,R<平均值,R_S为2。
F分值(F_S):定义为交易频率越高,F_S越大,F<=平均值,F_S为1,F>平均值,F_S为2。
M分值(M_S):定义为交易金额越高,M_S越大,M<=平均值,M_S为1,M>平均值,M_S为2。对各个用户的RFM的数据行进行打分赋值,代码如下:
#判断R列是否大于等于R列的平均值,使用loc将符合条件R_S列的值赋值为1
RFMData.loc[RFMData[‘R’]>=RFMData.R.mean,’R_S’]=1
#判断R列是否小于R列的平均值,使用loc将符合条件R_S列的值赋值为2
RFMData.loc[RFMData[‘R’]<RFMData.R.mean,’R_S’]=2
#同R_S赋值方法,对F_S、M_S进行赋值,但与R相反,F、M均为越大越好
RFMData.loc[RFMData[‘F’]<=RFMData.F.mean,’F_S’]=1
RFMData.loc[RFMData[‘F’]>RFMData.F.mean,’F_S’]=2
RFMData.loc[RFMData[‘M’]<=RFMData.M.mean,’M_S’]=1RFMData.loc[RFMData[‘M’]>RFMData.M.mean,’M_S’]=2
执行代码,R_S、F_S、M_S的分组分值就计算出来了,如下图所示。
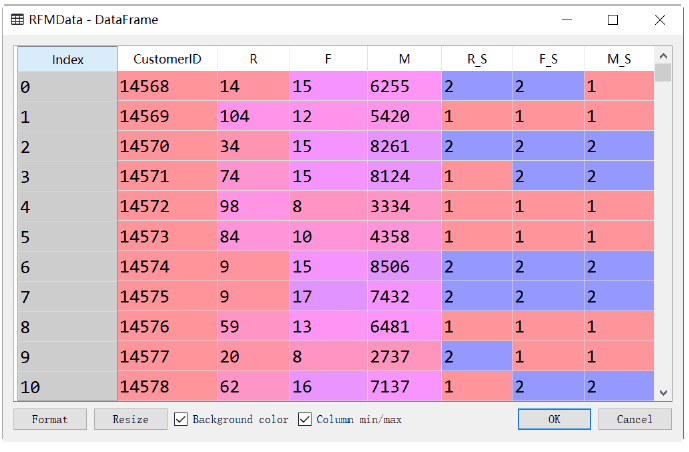
基于以上得出用户最终的RFM分层,如下图所示。
#计算RFM综合分值
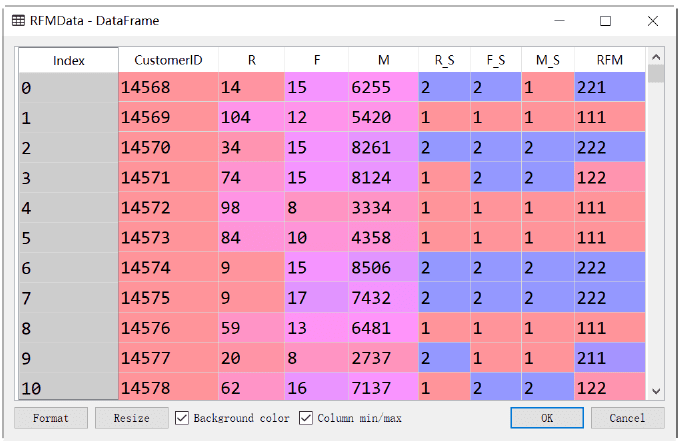
RFMData[‘RFM’]=100*RFMData.R_S+10*RFMData.F_S+1*RFMData.M_S
执行代码,得到的RFM综合分值如下图所示。CustomerID:14568的分层为221,对应的就是一般价值用户。
4. 用户分层
接下来结合文章开头提到的用户分层定义,将用户细分为8种不同的类型。本例采用与RFM综合分值与用户类型的对应关系表映射的方式实现用户分层。
首先将各个RFM综合分值与用户类型的对应关系定义为一个映射匹配表。
然后再使用merge中的内连接inner方法,将RFMData与刚定义的RFM综合分值用户类型的映射匹配表,根据关联列名RFM匹配合并为一个dataframe,这样就完成了用户分层的操作,代码如下:
#定义RFM综合分值与客户类型的对应关系表
CustomerType=pandas.DataFrame(data={‘RFM’:[111,112,121,122,211,212,221,222]’Type’:[‘潜在客户’,’重点挽留客户’,’一般保持客户’,’重点保持客户’,’一般发展客户’,’重点发展客户’,’一般价值客户’,’高价值客户’]})
#将RFMData与RFM综合分值客户类型的对应关系表合并为一个数据框#merge默认内连接,可省略,两表on条件的关联列名均为RFM,同样可省略 RFMData=RFMData.merge(CustomerType)
执行代码,得到的数据如下图所示。
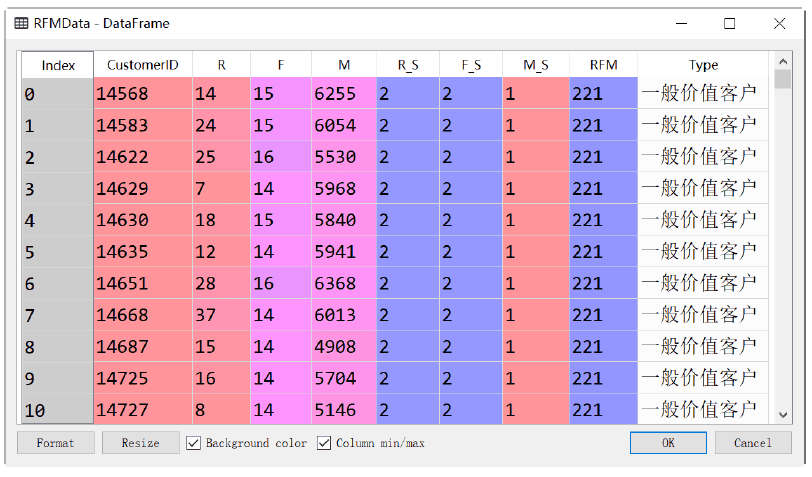
可以看到,最后一列数据,就是对每个用户细分的用户分层。最后,我们来看看,每个类别的用户数是多少,代码如下:
#按RFM、Type进行分组统计客户数
RFMData.groupby(by=[‘RFM’,’Type’])[‘CustomerID’].agg(‘count’)
执行代码,就可以得到各个客户类型的客户数了。
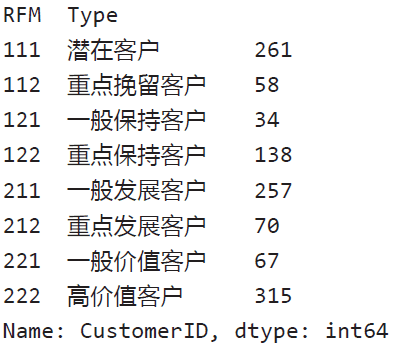
后续就可以对不同的客户群体,有针对性地采取相应运营策略进行推广、管理,进而提升客户价值和营收水平,限于篇幅,这里就不再展开,我们会在后续的用户运营专题上和大家继续讨论。
—— 如果觉得文章还OK,请转发 ——
特别提示:关注本专栏,别错过行业干货!
PS:本司承接 小红书 / 淘宝逛逛 / 抖音 / 百度系 / 知乎 / 微博/大众点评 等 全网各平台推广;
咨询微信:139 1053 2512 (同电话)
首席增长官CGO荐读:
更多精彩,关注:增长黑客(GrowthHK.cn)
增长黑客(Growth Hacker)是依靠技术和数据来达成各种营销目标的新型团队角色。从单线思维者时常忽略的角度和高度,梳理整合产品发展的因素,实现低成本甚至零成本带来的有效增长…
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/user/44461.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫