
小红书 小程序爬虫 小红书爬虫
小红书是有 APP 和 小程序两个入口。今天介绍小红书小程序的爬虫。
主要流程是以下几步
- 1.搭建抓包环境
- 2.抓包分析
- 3.模拟构造请求
- 4. 大规模验证
- 5. 小红书滑块解决
搭建抓包环境
这里不多说,我主要使用 IOS 手机 charles 。有时候也会使用 mitmproxy。
基本上就是证书安装,还有 ios 信任证书, 就可以抓到 HTTPS 的包了。有时间详细介绍下。
特别提示 mitmproxy 有一个定制代码功能。mitmdump 这个非常好用。可以在代码里面进行中间数据串改。
抓包分析
第一步配置好抓包环境后,第二步就是抓包了。在微信里面搜索小红书小程序,然后打开。
下面就是看到的内容。这里选了旅行的 tag。

点开任意一篇文章进行抓包,这里我们点击右上角的美女(我就喜欢美女嘿嘿)。
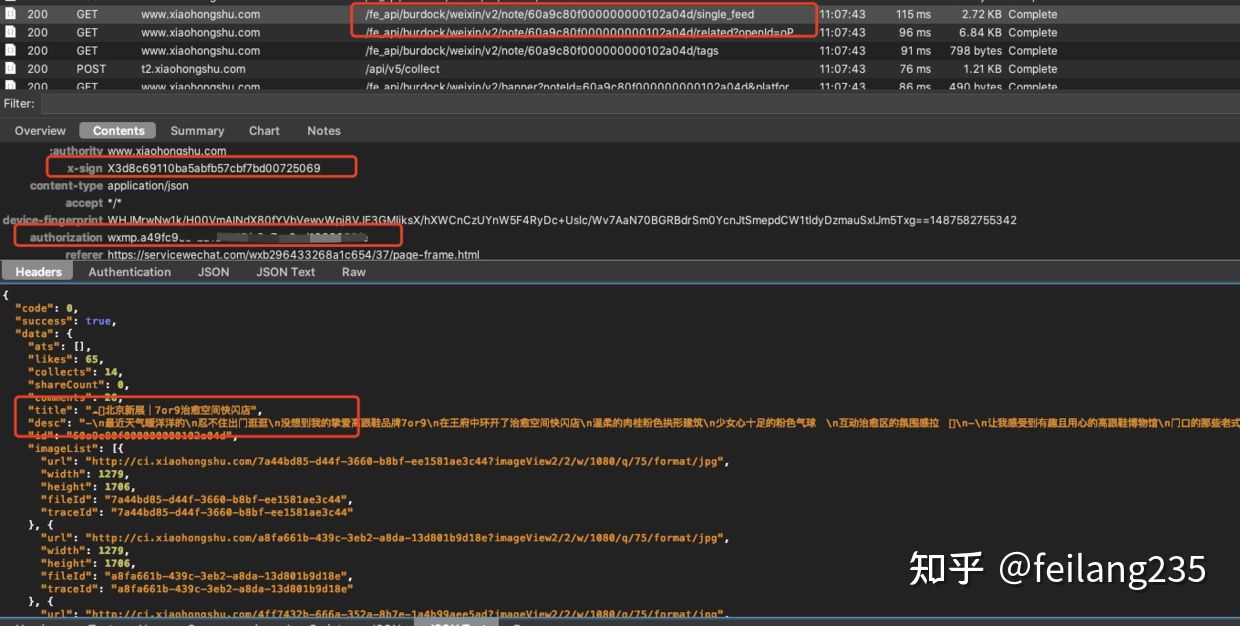
在 charles 中查看访问的链接。下图就可以看到请求的链接和返回的数据了。
进行测试:在链接上右键,Copy cURL Reqest 就可以得到 curl 的请求。复制到 iterm 中执行就可以得到数据了。

这只是单一的一个数据验证。没问题了。接下来就是小规模验证数据。
上面的图,中间有两个标红的地方需要特别关注,第一个是 x-sign 第二个是我打码的 authorization 。
模拟构造请求
模拟构造请求的时候,就需要关注上一步的 x-sign 和 authorization。authorization 是固定的,每一个用户一个 authorization。相当于登录的 session。这个是不会变得。但是大量请求会出滑块。这个后面再说。接下来就是 x-sign 验证。
多抓包几个链接分析查看 x-sign 都是 33 为的,而且首位都是 X。那么很容易联想到 x-sign 就是 X+md5 的结果。
既然是 md5 就可以在代码所有请求里面搜索 md5 。然后找到详细的位置分析后进行编码就行了。
这里分析到了详细的算法。算法实现方式也有了。详细的代码逻辑就不展示了。
大概就是 将所有参数组合再加上一个盐值(slat)进行 md5. 最后在首位加上一个 X。(仅供交流,需要加feilang235)。
获得上面两个参数后,接下来就是用代码进行模拟请求了。这个简单。python requests 一把梭验证 x-sign 没问题就行。
大规模验证
少量抓取没问题后,接下来就是大规模验证下。将相关接口都写完后
- 1. 小红书进行搜索
- 2. 搜索得到的笔记,进入笔记详情
- 3. 查看笔记的评论
- 4. 获取评论的用户信息
以上就是一个全链路循环。
代码完成后,开始抓取,结果跑了一会后,出现滑块了,程序错误。
滑块分析,这个过程比较难。折腾了很久才搞定。这里说一下大致原理。
- 1. 模拟请求小红书滑块滑块接口
- 2. 得到小红书滑块的图片
- 3. 对小红书滑块图片进行处理,对颜色做处理,分析出滑块位置
- 4. 使用 js 进行模式拖动,完成滑块的滑动动作。
- 5. 对结果进行提交,并且轨道需要加密。
- 6. 完成小红书滑块验证
通过上面的步骤就可以完成滑块处理了。然后又可以愉快的抓点数据了。当然如果量太大了估计也会对账号产生影响。不过目前我还没有遇到过。
补充说明
文章仅对小红书小程序抓包进行了分析,作为技术交流。如果对小红书造成了影响请联系我删除。
后续尽量带来 快手爬虫,抖音爬虫等 APP的分析。期待。
—— 如果觉得文章还OK,请转发 ——
特别提示:关注本专栏,别错过行业干货!
PS:本司承接 小红书 / 淘宝逛逛 / 抖音 / 百度系 / 知乎 / 微博/大众点评 等 全网各平台推广;
咨询微信:139 1053 2512 (同电话)
首席增长官CGO荐读:
更多精彩,关注:增长黑客(GrowthHK.cn)
增长黑客(Growth Hacker)是依靠技术和数据来达成各种营销目标的新型团队角色。从单线思维者时常忽略的角度和高度,梳理整合产品发展的因素,实现低成本甚至零成本带来的有效增长…
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/mcn/xiaohongshu/41547.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫