

图片|Photo by D koi on Unsplash
©自象限原创
作者|罗辑 程心
编辑|庄颜 排版|李帛锦
“泛而不强”的中国芯片
面对中国算力短缺的问题,更多人是“知其然不知所以然”,本质是因为整个算力体系相当复杂,而芯片只是中间最重要的一部分。
通常来讲,我们说的算力包含三部分,即基础算力、智能算力和超算算力,而AI大模型主要依靠的是智能算力。
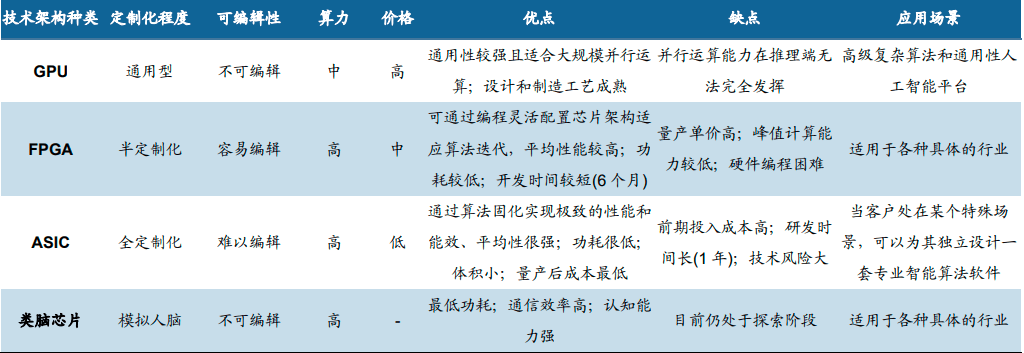
所谓智能算力,就是由GPGPU、FPGA、ASIC这样可以加速AI计算的芯片组成的服务器平台提供的算力,它们负责大模型的训练和推理。据IDC数据,2021年中国人工智能服务器工作负载中,57.6%的负载用于推理,42.4%用于模型训练。
▲ 图源:信达证券研报
虽然可以提供的智能算力的芯片有三类,但GPGPU其实占了目前主流市场90%的份额,剩下的10%才是FPGA、ASIC之类的产品。
GPU市场份额更大在于其通用化。
梳理中国算力的发展脉络,大致趋势可以以深度学习和大模型为节点划分为三个阶段,包括前深度学习时代,深度学习时代和大模型时代。2015年,以AlphaGo为节点,算力进入大模型时代。
在大模型时代之前,人脸识别、语音识别还是AI的主要应用场景。这个阶段大多数训练就已经是基于GPGPU来实现的了,也因此GPGPU形成了目前最为成熟、完备的软件生态。由于其芯片特点,GPGPU的通用性也更强,架构也更适合AI大模型的训练和部署。
而相应的,作为定制化和半定制化的FPGA 和 ASIC ,就只能应用在一些针对性的垂类领域。因此它们对模型的成熟度、对企业的模型研究深度都有更高的要求。
简单来讲,通用型的GPGPU适合刚入门的小白和资深大牛在内的所有人,而FPGA 和 ASIC作为定制款就只适合真正有经验的“玩家”。当然,通过这样的定制化之后,FPGA 和 ASIC芯片的产品和解决方案也有更高的性价比。
在应用场景的基础上,芯片的应用在AI大模型的训练上又分为训练和推理两个具体的环节。目前能够运行大模型训练的只有GPGPU,具有代表性的芯片就是英伟达的A100、A800、H100、H800。
但这类芯片目前国内的储备并不多。据「财经十一人」报道,国内目前拥有超1万枚GPU的企业不超过5家,其中拥有1万枚英伟达A100芯片的最多只有一家。另有消息提到,目前腾讯、字节、百度英伟达A100的存量都不超过2000枚,阿里的存量大约能过万,而更多公司都只能采用英伟达的中低端性能产品。
事实上也是如此,自A100和H100被禁止之后,中国企业就已经将目光放到了它的替代品A800和H800上了。目前,国内几家头部互联网企业都向英伟达下了1.5万~1.6万左右的A800和H800订单,涉及金额大概在十亿美金左右。
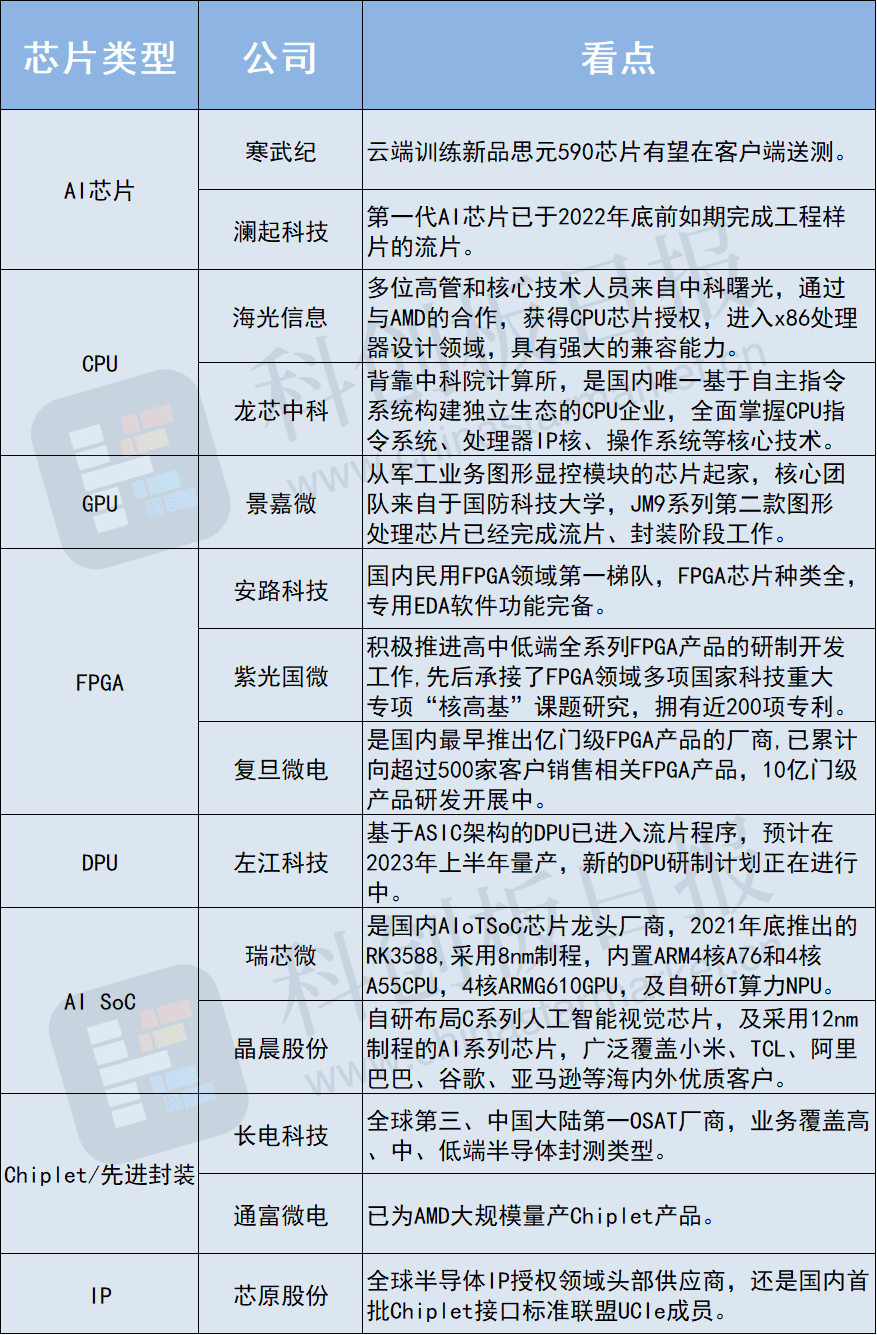
当然,国内其实也有自己的AI芯片,甚至在上一个国产芯片风口中起来的大多数有名有姓的企业做的都是应用在云端的AI芯片。
比如壁仞科技、燧原科技、天数智芯、寒武纪等等,都有自己的GPU产品,甚至部分产品的理论指标都不错。
比如寒武纪最好的产品思元270,在硬件指标上大概就能接近英伟达的A100,而且价格比A100还低,百度在训练文心一言时就小规模的部署了一些。
而之所以没有实现大规模部署,原因其实有两方面,一个是寒武纪的这款芯片智能运行大模型的推理部分,即它并不是一个通用的GPU。而另一方面在于,寒武纪目前还不具备大规模部署的能力。
这种大规模部署的能力具体又分为两点,一个是其供应链是否能够支撑起芯片的大规模出货,毕竟一旦大规模部署,一个公司的需求就是上万枚。而另一个关键点在于,当大规模出货之后,寒武纪还需要为客户配备大量的人力配合开发,而寒武纪在这方面目前也有没大力推动的意愿。
而除了国内领先的半导体公司之外,国内芯片的整体水平还是比较低的,有业内资深专家表示:“目前国产芯片的性能整体在英伟达的30%左右。”
AI大模型的训练要求芯片能够处理高颗粒度的信息。但目前国产GPU大多对信息处理的颗粒度不高,还不具备支撑大模型训练所需的能力。
另一方面,目前的国产GPU大多只能处理单精度的的浮点运算,比如壁仞科技BR100、天数智芯的智铠100,以及面提到的寒武纪思元270等等,它们在FP32的理论指标上做得不错,但没有处理FP64的能力。
目前从公开信息来看,国内唯一能支持FP64双精度浮点运算的只有海光推出的DCU深算一号,但它性能只有A100的60%左右。
▲ 图源:科创板日报
除了这些专业做芯片的半导体公司之外,国内的互联网大厂也几乎都有自己的AI芯片。
比如阿里在2019年发布的含光800,百度在2020年发布的昆仑芯,腾讯在2021年发布的紫霄,以及华为的昇腾系列等等。
但这些大厂的AI芯片大多也都属于的定制版本,在应用上也面临诸多限制。
除了前面提到寒武纪的芯片只能用在推理之外,华为的昇腾通用性也很差,它只能应用在MindSpore这类华为自己的开发框架下,以及他们优化好的大模型上。任何公开的模型都必须经过华为的深度优化才能在华为的平台上运行。
当然华为也有自己的优势,即昇腾芯片涉及的所有IP都是买断的,不会存在技术被卡脖子的问题。同时华为围绕自己的AI大模型和芯片建立了一系列的算法和软件,实现了自己的闭环。
整体上,从芯片的角度国产算力的长征才刚刚开始,我们在部分细分领域实现了一定的程度的国产替代,但仍然无法实现更多环节存在性能不足和算力漏洞。
而随着大模型的发展越来越热,市场对算力的需求仍将呈指数级上升,国产芯片厂商既要解决算力问题,还要解决软件生态和工具的问题,难度可想而知,但市场留给我们时间却不多了。
云 for AI有戏,AI for 云差千里
纵然“云智一体”已经成为了讨论的前提,在众多关于云与智能关系的论调中,无非是云计算巨大的存储和计算空间,能够帮助大模型训练大幅度降低成本。
但这却并不足以道出其中乾坤。
用一个形象的比喻,云与AI就像是新能源与自动驾驶的关系。传统燃油车的架构复杂,在智能化改造方面,并没有足够的空间去安装摄像头、激光雷达和芯片,只有在新能源车简化了发动机系统和整车架构的前提下,才使得自动驾驶硬件和软件有接入的空间,并以智能化为目标重塑整车结构。当下新能源与智能化如同一对双生子,同步向前迈进。
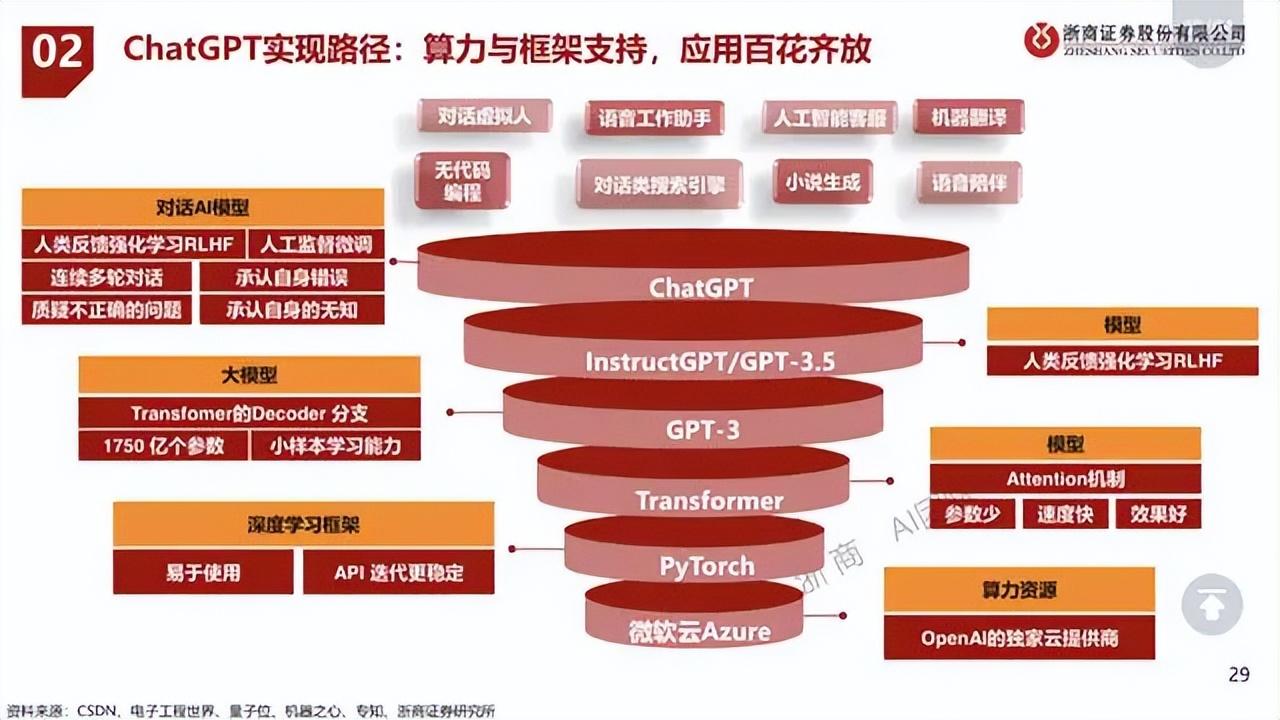
同理,在传统的存储和计算架构中,并没有那么强的弹性和空间,能够适应AI训练过程中的变化和应用,用传统服务器和存储结构训练大模型,简直是用诺基亚手机玩原神。而云计算的存在,既保证了快速响应、快速变化的空间,连接了底层硬件和上层应用,同时也给了大模型训练更强的算力支撑,可以说,没有云,就不会有大模型。
▲ 图源浙江证券股份有限公司
从2012年开始,中国以阿里云为“带头大哥”开始了一段云计算的征程。10年过去了,在全球排名上,阿里云已经仅次于亚马逊AWS和微软Azure,排在世界第三的位置,在基础设施的建设和算力准备上,可以说中美并没有拉开太大差距,这也是为什么,在《ChatGPT启示录系列|万字长文解码全球AI大模型现状》一文中,我们强调中国在大模型上有一定的底气,而日本错过了云时代,也就错过了AI。
但在多模态大模型和AIGC的进一步推动下,对云计算能力提出了新的要求。AIGC需要多模态数据和强大的模型,包括不限于时序、文档、宽表、结构化、非结构化、图片数据等,还要将各类数据融合在一起,提供存储、使用能力和推理能力,这是中国云厂商将要面临的新挑战。
不过,云 for AI 解决的仍然是发电问题,AI for 云解决的才是发电效率的问题。前者的重点在于“车能不能跑起来”,而后者的重点在于“车能跑的多快”。
这来自于AI对云计算底层架构的改造。
以基础软件中,国内跑的最快的数据库为例。在阿里云瑶池数据库峰会上,李飞飞不断强调“智能化是未来云原生数据库发展的动力”。用智能化的技术接入数据库的运维,比如异常检测、HA切换、参数调参等等。
异常检测场景的智能化可能要更为容易理解,假设该数据库存在10张表格,按列分布,非智能化数据库(包括传统数据库和云原生数据库)的检测模式,需要将这10张表逐列检测,最终定位故障点。而分布式则可以将10张表拆开同时检测,用一张表的时间跑完十张表,提高检测效率。但智能化数据库则可以通过引入AI能力,制定检测标准,精准定位、精准打击,将检测时间从10分钟缩短到几秒。
这不仅需要强大的AI能力,也是不断测试不断优化模型的结果,最终让云成为智能云。
带这个思考重新看“2019年,微软Azure花10亿美元买断OpenAI成为其独家供应商”,就更加感叹纳德拉的老奸巨猾。一方面,Azure成为OpenAI的独家供应商后,所有基于ChatGPT和GPT4的MaaS(模型即服务)服务都长在Azure上,这将为Azure快速获得市场份额,甚至有反超AWS的可能。另一方面,OpenAI通过Azure训练自己的AI大模型,也快速、高强度打磨了Azure的智能化能力,目前Azure是全球排名第一的智能云。
微软负责云计算和AI业务的执行副总裁斯科特·格思里(Scott Guthrie)在接受采访时说:“我们并没有为OpenAI定制任何东西,尽管其最初是定制的,但我们总是以一种泛化的方式构建它,这样任何想要训练大型语言模型的人都可以利用同样的改进技术。这真的帮助我们在更广泛的范围内成为更好的AI智能云。”
目前,微软已经在努力使Azure的AI功能变得更加强大,推出了新的虚拟机,使用英伟达的H100和A100 Tensor Core GPU,以及Quantum-2 InfiniBand网络。微软表示,这将允许OpenAI和其他依赖Azure的公司训练更大、更复杂的AI模型
反观国内智能云队伍,仅有百度智能云独自站在冷风里吆喝了几年,但在「自象限」看来,百度智能云离真正的智能云还相差甚远。百度云的“智能”在于通过云服务提供AI能力,比如推荐算法、人脸识别,但这只是服务内容的不同,换汤没换药。
不过从李彦宏近期的发言来看,似乎也想明白了“进化”的方向,但可以肯定的是,中国智能云的故事不会只有百度一家,阿里腾讯华为的动作也都在镁光灯下。
「自象限」根据公开信息了解到,4月11日,阿里云峰会中阿里巴巴董事局兼主席张勇出席,或将在会上正式推出阿里大模型,接下来还有各类行业应用模型面世;4月18日,在火山引擎原动力大会中,字节跳动副总裁、火山引擎业务负责人杨震原的出现,也让业内不少人士期待和推测,是否会发布字节跳动的大模型。
然而无论是技术驱动还是市场驱动,一方面在硬件算力上持续突破,另一方面在软件算力方向试图弯道超车,在算力长征路上,中国要补的课、要打的仗都还很多。
▪ 文中配图来源于网络
本文来自投稿,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/quan/101079.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
评论列表(7条)
海光推出的DCU申算一号是国内目前唯一支持FP64双精度浮点运算的产品
GPGPU的通用性是更强的,在AI大模型训练和部署中有着更适用的架构
作为刚入门的小白,还是通用型的GPGPU更适合我
从硬件指标上来看,寒武纪思元270大概能和英伟达的A100相接近,而价格却比A100要低,难怪美国要抵制AI一些产品出口中国了
海光信息在研发方面还是投入了很多精力的
国产芯片厂商除了要解决算力,还要解决软件生态和工具,难度很大啊!
目前只有GPGPU能够运行大规模训练,其中代表性的芯片就是英伟达公司生产的