

划重点:
1、如果将开发大模型比做是“造房子”,那AI Infra 就是“工具箱”,而中国缺少的正是工具和原材料制造工厂。
2、根据国外市场的情况,可以将整个AI Infra大致分为数据准备、模型构建、模型产品三个层面,在这三个层面中的每一个节点,都是创业公司的机会点。
3、“数据准备”是中国AI Infra第一个机遇。围绕着“以数据为‘能源’”,本身就是一条十分复杂而又基础的产业链,而我国的数据相关产业链,几乎都是云大厂“一带而过”,缺乏深耕在某个细分领域的垂直竞争。
4、在AI大模型的训练过程中,为训练和推理提供工具和调度平台也正在成为一个新的市场“模型中台”,但从目前国内的情况来看,“模型中台”确实是创业大佬们的游戏。
©自象限原创
作者|程心
编辑|罗辑 排版|李帛锦
ChatGPT火爆之后,科技圈有不少人想谱写AI 2.0的中国故事。
据「自象限」不完全统计,短短一个月,国内有名有姓的大佬下场AI创业已经不下10位。但当AI Infra赫然出现在贾扬清的创业字典里时,一位前百度NLP高级工程师一边感叹贾扬清创业眼光的毒辣,一边对「自象限」说了四个字:这事能成。
这位工程师所说的“这事”,指的也并不是贾扬清创业的成败,而是终于有人看到了中国AI Infra的底子薄弱,想要上手来补一补了,那么,国内做AGI——“这事能成”。
不止贾扬清,最早掀起“大佬创业潮”的王慧文,在披露出为数不多的消息中,Infra 出现了两次。在三个联创中,“一个Infra(基础设施)背景的联创”占据了重要的名额,与此同时,光年之外的第一个动作,便是与国产AI框架一流科技(Oneflow)达成并购意向。
被贾扬清和王慧文双双押注“AI Infra”到底是什么?在整个大模型开发中占据哪些关键节点?
顺着大佬们的思路,「自象限」将AI Infra的链条进行了盘点和国内外公司对比以反观中国现状。简单来说,AI Infra 是一套十分复杂又基础的体系,包括构建、部署和维护人工智能 (AI) 系统所需的硬件、软件和服务的组合,它包括使AI算法能够处理大量数据、从数据中学习并生成有意义的见解或执行复杂任务的基本组件。
即如果将开发大模型比做是“造房子”,那AI Infra 就是“工具箱”,而中国正是缺少工具和原材料制造工厂。
在这样的背景下,未来3~5 年,相比于受限大模型能力变化的应用层面,AIInfra反而会更加稳定。毕竟大模型公司搞军备赛,那卖武器的公司增长一定十分可观。
但问题在于,如今中国的AI产业链在这一块还处于相当空白的状态。国内基于ML进行数据标注的公司星尘数据创始人就曾提出过这个问题,中国有没有AI Infra公司?答案是,没有。
他认为“国内从业人员太过于专注在方法论上,而方法论是公开的,但实际不公开的内容才有更多Knowhow和壁垒性。”
所以,如果说应用生态是显性创业机会,那么AI Infra便是隐形的蓝海。事实上,当AI进入2.0时代,AI Infra在整个AI产业链的价值也正在发生变化。
我们根据国外市场的情况,可以将整个AI Infra大致分为数据准备、模型构建、模型产品三个层面,在这三个层面中的每一个节点,都是创业公司的机会点。
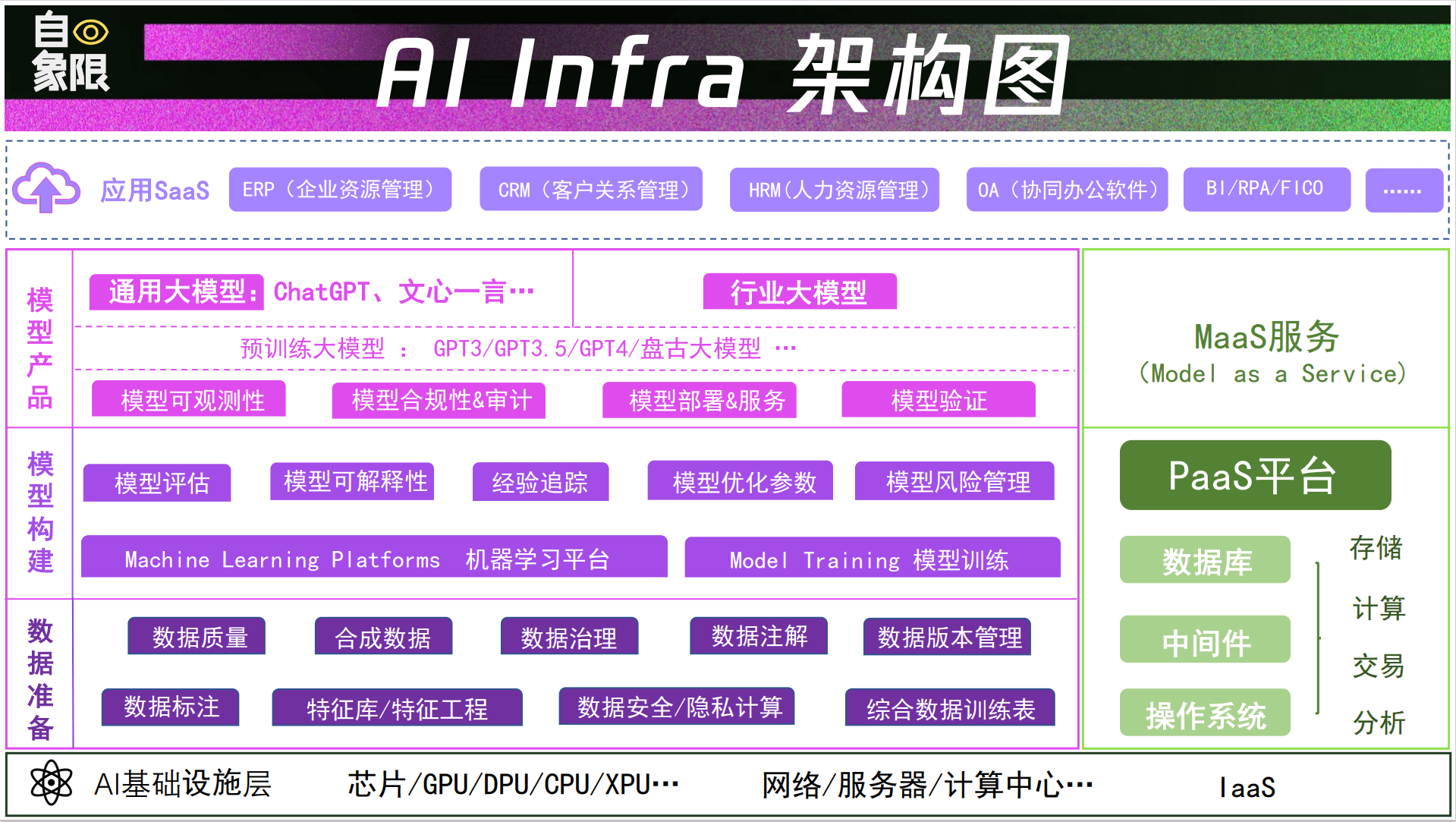
图片为自象限原创,转载请注明出处(公众号后台回复“AI Infra”获取高清大图)
其中数据准备又可以具体拆解为数据质量、数据标注、数据合成和应用商城与工程;模型构建又包括机器学习平台、版本控制和实验跟踪、模型风险管理;模型产品则包括模型部署和服务、模型监控、资源优化等。
这些细分场景都在成为AI产业链的新“聚宝盆”。本文重点结合海外头部公司对AI基础层的研究,梳理了在大模型训练中比较重要,亦或是国内目前比较薄弱的方向,希望给国内创业者予以启发。
数据新产业链中的“聚宝盆”
“数据准备”是中国AI Infra第一个机遇。
对比中外生成式AI的发展会发现,中文数据的缺乏一直中文AI大模型的是最大的短板之一。
有公开数据表示,截至2021年,在全球排名前1000万的网站中,英文内容占比60.4%,中文内容占比仅1.4%。但作为AI三要素(数据、算力、算法)中最基础的部分,数据又是整个AI大模型训练的前提。没有数据,就相当于巧妇难为无米之炊。
需要明确的是,围绕着“以数据为‘能源’”,本身就是一条十分复杂而又基础的产业链,涉及到数据质量、数据标注、数据安全三个主要部分和多个环节。
未来在AI活跃的氛围下,中国一定会涌现出多个大模型,目前仅百度就有36个大模型,阿里、百度、腾讯、华为每家的大模型都不低于三个。而大模型越“热闹”,对后端数据的需求数量和质量也会更高。
但反观我国的数据相关产业链,几乎都是云大厂“一带而过”,缺乏深耕在某个细分领域的垂直竞争,「自象限」整理了几个产业链中的关键机会,仅供抛砖引玉,期待更多创造。
1、“数据质量”新机会:曾在这里摸爬滚打的企业,或迎来“出头之日”
整体上看,数据质量的机会分为两个部分,一部分是在技术侧,机器学习和自动检测正在成为数据质量的新机会。另一部分是在市场侧,随着AI市场规模越来越大,数据质量正在从产业链末端扩展成为供应商直接服务企业。
未来,随着AI成为社会发展的底座,数据质量会成为每个企业的刚需。但国内数据质量尚未受到足够的重视,缺乏专门做数据质量的企业,它更多是以大公司附庸品的形态出现,更像是“顺手”做的事情。
但实际上,数据质量是需要市场化的,就像汽车公司没办法生产每一个零部件一样,只有让数据质量成为整个产业的底座,通过众人拾柴火焰高的方式,才能推动整个行业的发展。
在国外,数据质量是十分垂直的赛道。这类公司的核心目标,是帮助人工智能企业最大限度地减少劣质数据带来的影响,他们的产品通常包括数据可观察性平台、数据整理和偏见检测工具,以及数据标签错误的识别工具等等。
国内其实也有这类的公司,但数量稀少。比如针对数据治理的公司有亿信华辰、普元、石竹、龙石、华矩科技、卡斯特等等。这些公司有一个非常明显的特点,就是他们在数据的细分赛道里摸爬滚打了很久,但因为这个赛道过于垂直,因此无论是资本还是市场都对他们关注不多,导致他们一直没有“出头之日”,也导致他们和国外专业的数据治理公司差距甚远。
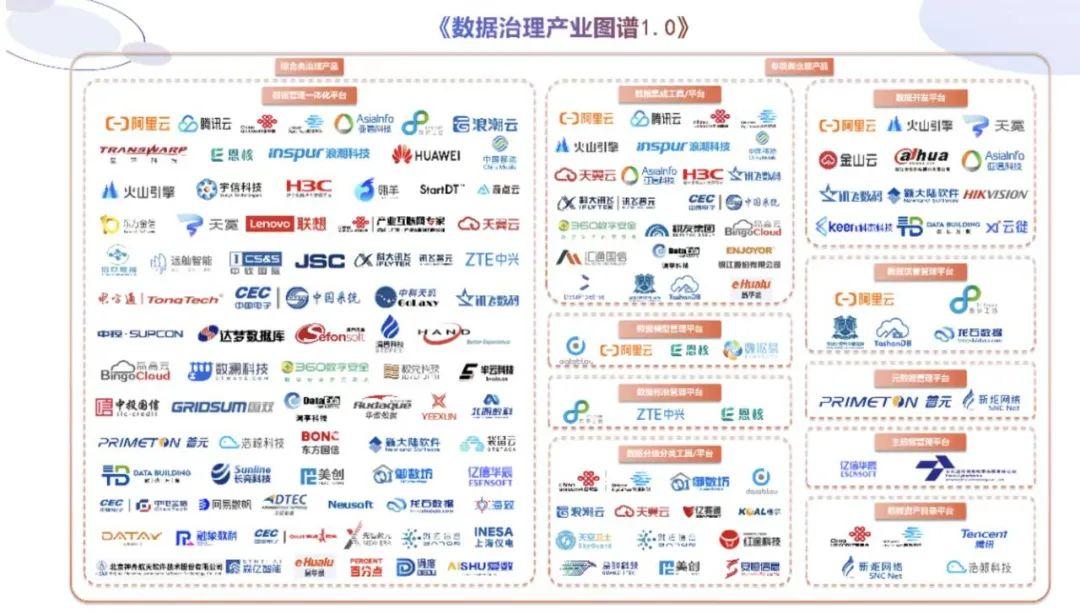
▲ 图源《数据治理产业图谱1.0》
国内的数据公司目前大多停留在筛选阶段,而国外的公司却能通过深度学习对数据进行深度挖掘,在同样的数量上获得更多有价值的部分。这种差距主要源于:
第一,国内数据处理方式老套。许多中国的数据公司仍然在使用数据建模这样的传统方法进行数据处理,而国外已经开始使用机器学习的方式进行自动处理、自动标注,自动检测安全等工作。
第二,数据处理效率低下、可用的优质数据占比低。中国的数据公司在做数据处理的时候仍然处在初级阶段,即在一堆数据中将符合标准的数据筛选出来,只是不同的公司筛选的标准不同,得到的结果有所差异。而国外的公司却能在数据处理的过程中,通过对数据不停的清洗、修改得到更多符合条件的优质数据。
简单来说,在AI 2.0时代,大模型的训练对更全面、更准确、可溯源的高质量数据有着更庞大的需求,同时也对效率有更高的要求,依靠机器学习自动检测质量问题,将会是一条新的路径。
同时,在数据成为“新石油” 时代,数据质量并不能只靠大模型的发展带动,每个企业都需要对内部数据的质量进行精粹,发挥市场化的力量,大范围提质。
对标国外垂直赛道中的典型案例Anomalo,它使用ML自动评估和通用化数据质量检测能力,实现了数据深度的可观察性,以及数据质量检测的能力泛化。
简单来讲,它一方面把数据质量这件事检测这件事做得更深,另一方面通过能力泛化将其做得更广。
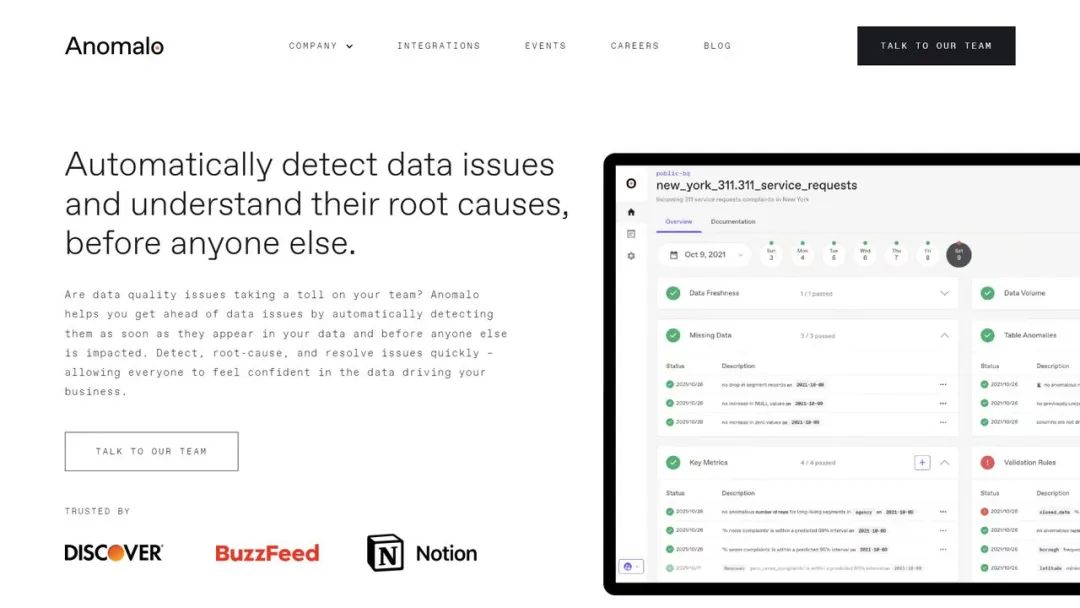
▲ 图源Anomalo官网
2022年10月,Anomalo与Google Cloud达成合作,企业可以使用无代码关键指标和验证规则或通过任何自定义SQL检查来微调Anomalo的监控。简单的说,Anomalo上云后,对于企业而言几乎可以无门槛接入,且适配性高。
Notion是Anomalo的核心客户之一,Notion是国外最大的All in one 办公软件,国内的飞书学习的就是它。其软件工程师对此评价到“Anomalo团队的功能、集成数量和响应速度够非常强大,用户易于导航并找到他们正在寻找的内容。”
2、数据标注新机会:从“人工标注”到“算法标注”
数据标注者正在从人工标注,向自动标注和智能标注迈进,中间的变化不仅是效率的提升,也将迸发出巨大的产业机会。
在AI 1.0时代,人工标注是AI发展最典型的特点,在那个“有多少人工就有多少智能”的时代,全世界的AI发展都与底层廉价劳动力资源息息相关。
但在AI2.0时代,李开复点明与AI 1.0的第一个差异就是无需人工标注,AI可以阅读海量的文本,进行自监督学习。可以说,标注后的数据是AI大模型的命脉,它的性能和准确性直接取决于标注数据的质量和数量。
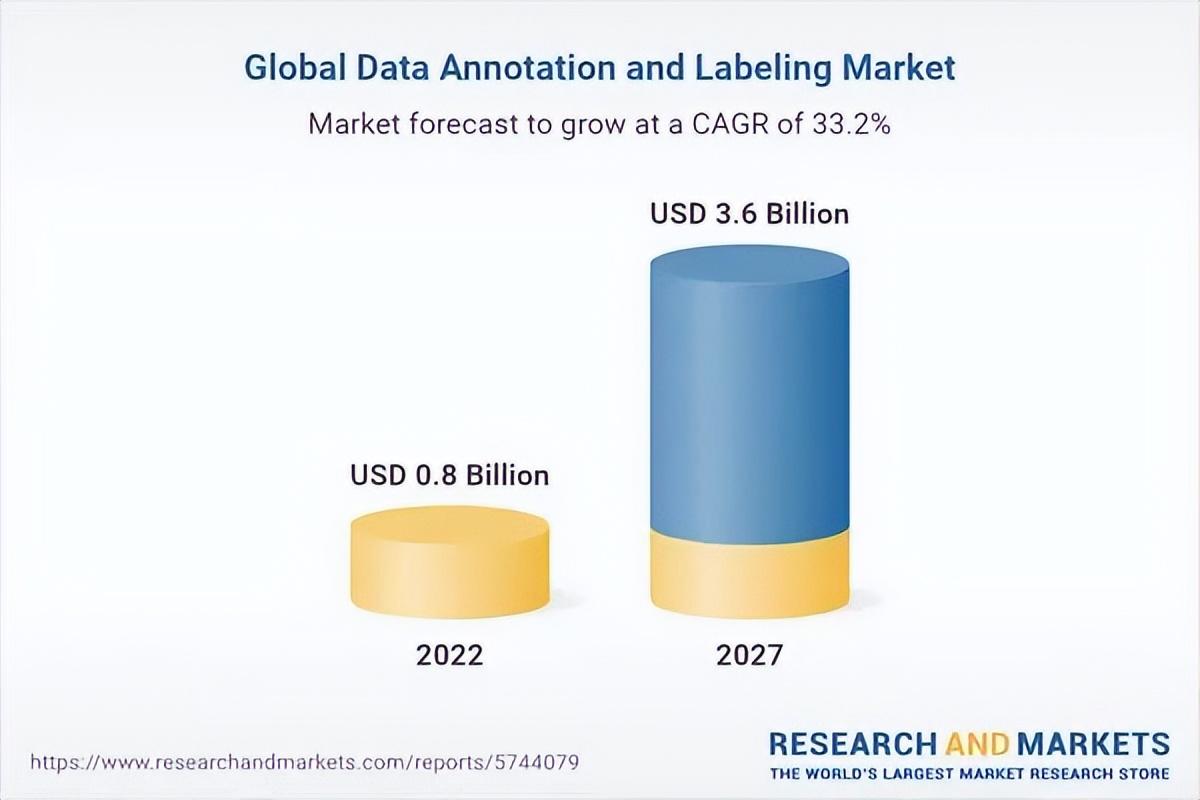
在AI产业链中,数据标注也占据了非常大比重,据AI分析公司Cognilytica的数据,数据标注环节的耗时占比可达25%。根据researchandmarkets的报告,全球数据注释和标签市场预计将从2022年的8亿美元增长到2027年的36亿美元,预测期内复合年增长率为 33.2%。
▲ 数据标注通常包含图像、文本和视频。 ▲ 数据标注通常包含图像、文本和视频。
以AI大模型之前,以AI最为人所熟知的自动驾驶领域为例,数据标注和训练一直是自动驾驶技术研发中成本最高的两个“吞金兽”,为了解决成本和效率问题,无论是国外特斯拉还是国内的毫末,都在人工标注到标注自动化,再到标注智能化的路径上进行探索。
自动驾驶仍然是数据标注/图片标注使用量最大的一个应用场景,而未来,随着文本大模型、多模态大模型的不断涌现,还将出现新的增长机会。
从人工标注到算法标注,是底层智能化的变迁。这其中跑的最快的是Scale.ai,目前Scale.ai是全球最大的数据标注公司,据外媒报道,目前Scale.ai最新一轮E轮融资3.25亿美元,估值达到73亿美元。
Scale.ai早期走的也是人工标注路线,利用了印度标注团队,靠着比美国更便宜、更高效的标注服务打开市场。在行业选择上选择了当时大火的自动驾驶赛道,并早早与Waymo等龙头企业达成合作。
后期随着技术的发展,AI训练对数据的广度、深度、精度要求也越来越高,为了解决这个问题,Scale AI将AI应用在数据标注服务中,先用AI识别,再由人工负责校对其中的错误,校对完的数据再“投喂”给训练模型,使下一次的标注更加精准。
目前,Scale也将业务拓展到无人车、无人机和机器人等领域,同样也在向下游拓展,开发自有模型提供给其他数据标注公司,并逐步进入AI/ML价值链的更多环节。客户包括美国国防部、PayPal、自动驾驶公司及科技巨头。
3、数据隐私和安全新机会:“合成数据”或成AI数据主力军
正如互联网的发展长河中,崛起过如360、金山毒霸等“安全专家”,移动互联网时代的腾讯手机管家、360手机卫士一般,在AI时代,“安全”将仍然是技术和应用发展的底盘和重心。
目前,随着AI技术呈指数级发展,合规和隐私风险的行业痛点也在逐渐暴露,3月的最后一天,在西班牙媒体指责OpenAI未能遵守用户数据保护法规后,意大利相关部门也以类似的理由宣布了对ChatGPT的禁令。
隐私计算和数据安全话题被重新推上风口浪尖。
3月下旬,OpenAI曾发布声明,称因为ChatGPT开源库中存在一个漏洞,致使一些用户可以看到其他用户的信息,包括用户姓名、电子邮件地址、付款地址、信用卡号后四位以及信用卡有效期。
ChatGPT目前拥有超过1亿用户,虽然OpenAI并未说明,“一些”用户泄露到底是多少数量级,但哪怕只有千分之一的用户接触到了这一漏洞,其后果都是不可估量的。
中国面对大模型的保守和谨慎也有一部分来源于对数据安全体系的不信任。国家层面也不断提出加大安全性测试和常态化管理投入,包括数据外泄等问题的紧急检测和修补措施,以及更先进的预防体系建设,如内控流程的完善、数据脱敏处理等,最大限度保证安全性。
数据显示,中国信息安全市场的潜在空间高达1000亿元上下,与全球安全服务市场64.4%的份额相比,我国安全服务市场占比仅为19.8%。目前国内信息安全产业依然以硬件为主,代表企业如奇安信、新华三等。软件市场空白度高,发展潜力巨大。
除了更加强大的数据安全保护之外,从根本上解决数据隐私的问题也成为一种思路,其答案就是数据合成。
合成数据即由计算机人工生产的数据,来替代现实世界中采集的真实数据,来保证真实数据的安全,它不存在法律约束的敏感内容和私人用户的隐私。
目前企业端已经在纷纷部署,这也导致合成数据数量正在以指数级的速度向上增长。Gartner研究认为,2030年,合成数据将远超真实数据体量,成为AI数据的主力军。
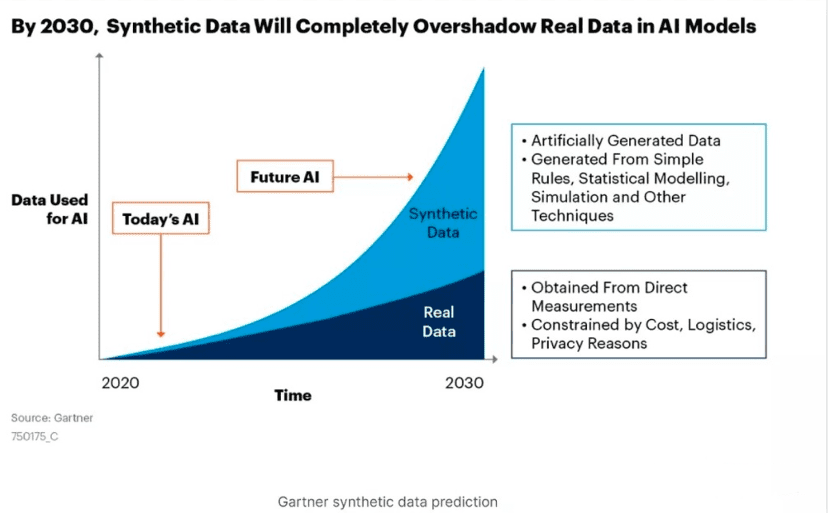
▲ 图源Gartner官
“钞能力”的“模型中台”:需要创业大佬们的新游戏
如果我们把大模型看作一个云产品,那么数据、算力、算法可以被看做是这个产品的“IaaS”,即基础设施。而在“基础设施”和前台应用的SaaS之间,还存在一个PaaS平台作为中间层,承担起为SaaS提供部署平台,开发工具等任务。
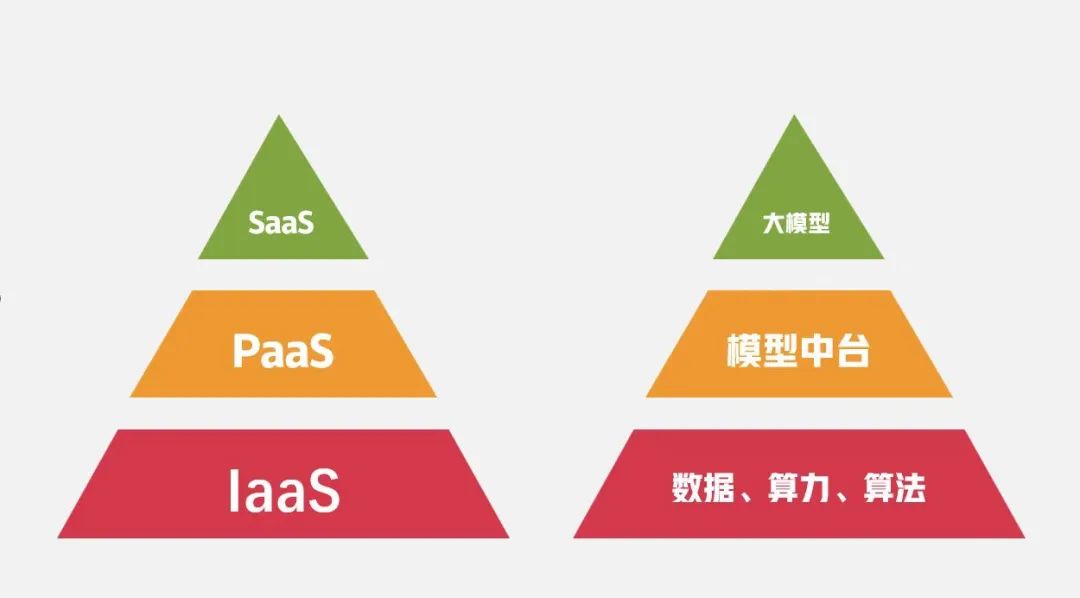
这样的结构在AI大模型中也同样存在,当训练AI大模型的前期数据准备工作完成后,数据会被送到一个新的训练池里,在这里完成训练、推理,中间也涉及到各种开发工具、统筹调度等系统,我们也可以将其称为大模型的“炼丹炉”。
现在,大模型训练已经有ML Paltform这样的平台型解决方案覆盖从数据准备训练、验证、到模型部署和持续监控的全流程,促进端到端的模型开发。
这类公司可以简单理解为“大模型开发的一站式服务平台”,为任何想要开发或使用大模型的公司做供应商服务。
事实上,如果继续对比这些年云计算的发展和变化会发现,云厂商和企业都在不约而同地加码PaaS平台。而在AI大模型的训练过程中,为训练和推理提供工具和调度平台也正在成为一个新的市场“模型中台”。
▲ 图源DataRobot
但“模型中台”市场也存在许多问题。
比如,Forrester在《The Landscape In China, Q4 2022》报告中指出目前的市场化难点:“客户使用AI技术的关键障碍之一,是缺乏开发AI解决方案和操作AI系统的能力,而AI/ML平台是解决这一问题的有效方法。Forrester依据供应商的市场情况,将其划分为大型、中型、小型三类。”
目前国外这个市场出现了“大鱼吃小鱼”的情况,大型供应商正在通过收购AI开发过程中不同部分的小型公司,以占据更大的市场份额。
目前在全球范围内跑得比较快的是DataRobot,最新一轮完成了2.5亿美元的融资,估值达到60亿美元。Dataiku最新一轮完成了4亿美元的融资,估值达到42亿美元。还有开源公司H2O.ai,最新一轮完成了7000多万美元的融资,由高盛和平安领投。
但这还只是“模型”中台的在训练部分的机会,当一个模型完成训练之后,就进入了模型部署环节。
模型部署也是未来大模型走向B端应用的一个重要环节,也有一套专属工具。
这套工具需要与底层 ML 基础设施、运营工具以及生产环境结合,来实现模型部署的三大环节,即优化模型性能,简化模型结构,并将模型推向生产。
一般来说,模型的部署可以是几周、几天,也可以是几个小时,这要看模型部署的效率。所以更快的模型部署能力也是更强的核心竞争力。
而这类工具可以将ML工程师从基础设施和硬件层面的决策中抽象出来,协调IT团队、业务人员、工程师和数据科学家的工作,提高大模型部署团队的整体效率。
除此之外,它们还能将训练有素的模型转化为敏捷、可移植(适用于任何硬件)、可靠的软件功能,并与企业现有的应用程序堆栈和DevOps工作流程相结合。简单来说就是提高模型的环境适应能力,快速与更多业务兼容。
不过,从目前国内的情况来看,“模型中台”确实是创业大佬们的游戏,对于当下中国的AI链条来说,除了高昂的启动资金和试错成本外,更需要的是超一流的专业技术,如何合理规划平台架构,深入到训练部署的每一个环节,对创始人的框架能力要求极高。
从另一个角度来看,在这场需要“钞能力”的游戏中,创业公司和资本的关系将比此前更为密切,甚至决定生死。
▪ 文中配图来源于网络
▪ 资料参考:
https://zhuanlan.zhihu.com/p/594362766
本文来自投稿,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/quan/101119.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 