

文|姚 悦
编|王一粟
“这两年内,大模型带来了750倍算力需求的增长,而硬件的算力供给(增长)仅有3倍。”华为昇腾计算业务总裁张迪煊在2023世界人工智能大会上,揭开了被大模型“暴力计算”引发巨大算力缺口的真相。
而这个算力缺口还在进一步扩大当中,张迪煊预计,到2030年 AI 所需的算力,相对2020年还会增长500倍。
与此同时,由于众所周知的原因,算力国产化也迫在眉睫。
针对如何补足算力短板,毕马威中国数字化赋能主管合伙人张庆杰认为,需从三大途径解决,分别是算力建设、基础设施的共享与优化、算法的优化和数据的质量。这其中,算力建设被摆在首要位置。

华为在近年算力建设中颇为积极。据中信证券7月研报,国内现有城市智算中心中,以建设数量计,目前华为占据整体智算中心约79%的市场份额。
除了以量取胜,提升算力集群的能力更为重要。就在2023世界人工智能大会上,华为宣布昇腾AI集群全面升级,集群规模从最初的4000卡集群扩展至16000卡,算力集群迎来“万卡”时代。
华为轮值董事长胡厚崑表示,昇腾AI的集群相当于把AI的算力中心当做一台超级计算机来进行设计,使得昇腾AI集群的性能效率达到10%以上的提升,而且系统稳定性得到十倍以上的提高。
张迪煊在群访中亦对光锥智能透露,早在2018年,华为就判断人工智能会快速发展,并改变过去小模型的开发模式,形成大算力结合大数据生成大模型的模式,所以华为那时候就开始开发算力集群产品。
步入AI时代,已经无法再像单机系统时代那样靠堆芯片拉升算力,而是要系统化重塑算力基建。在扩大巨量算力供给的同时,要解决算力利用率、使用门槛高等问题,最终还要实现算力生态化。
算力集群迎来“万卡”时代
今年ChatGPT引爆算力需求后,硬件端最先火的是GPU,英伟达总市值年内已经上涨了66%,最新为1.05万亿美元。
以英伟达A100为主的GPU成了大模型必备的香饽饽,但仅靠堆卡也无法应对“百模大战”的爆发之势。那么,如何把宝贵的算力资源,发挥到极致?
既然单个服务器已经很难满足计算需求,于是将多个服务器连接成一台“超级计算机”,正在成为当下“算力基建”的主攻方向,这台“超级计算机”就是算力集群。
2019年,华为就发布了Atlas 900 AI训练集群,当时由数千颗华为自研昇腾910(主要用于训练)AI芯片构成,到今年6月已经支持到8000卡。而在刚刚结束的世界人工智能大会上,华为更是宣布计划今年年底或者明年年初,做到超过16000张卡的集群。

万卡集群是什么概念?
以1750亿参数量的GPT-3模型训练为例,使用8张V100显卡,训练时长预计要36年,512张V100显卡,训练时间接近7个月,而1024张A100的训练时长可以减少到1个月。
按照华为的评估,训练GPT-3模型,100B的数据量,在8000卡的Atlas 900 AI集群下需1天即可完成训练,16000卡集群下仅需半天即可完成。
但别看“万卡”算力大、效率高,真正想要用它去训练模型,绝非易事。
正像中国工程院院士高文所说,“有人说全世界能在1000块卡上同时选连一个模型的只有几千人,能在4000块卡上训练的不超过100个人,在10000块卡上训练模型的人数更少了”,在千卡和万卡上训练和推理数据,对于软件规划、资源调度挑战非常大。
首先,万卡量级的训练,对分布式并行训练提出了更高的要求。分布式并行训练是一种高效的机器学习方式,将大规模数据集分成多个部分,再在多个计算节点上并行训练模型。这样可以极大缩短训练时间,提高模型准确性和可靠性。
昇腾算力集群的分布式并行训练,就需要倚仗华为自研的昇思MindSpore AI框架。
昇思MindSpore支持多种模型类型,还开发了一套自动混合并行解决方案,实现数据并行和模型并行的混合并行训练。
相同算力和网络下,这样的双并行策略可实现更大的计算通信比,同时还解决了手动并行架构的现实困难,让大模型开发和调优效率提升。
此外,由于分布式并行训练,每训练出一个结果,需要所有的芯片同步一次,这个过程中,会有出错的概率。这种情况放在万卡规模量级上,就对于稳定性提出更高要求。
“昇腾的可靠性和可用性的设计,可以做到30天长稳的训练,对比业界的最先进3天左右水平,提升了将近10倍性能的稳定性、可用性优势。”张迪煊表示。
算力集群的效率如何提升?
算力集群还不仅仅是规模扩大,效率也需要有很大提升,否则就会出现卡数越多,算力利用率反而下降的问题。
以华为在内蒙古乌兰察布市部署的数千卡规模的AI集群为例,在同等算力下,计算效率能够提升10%以上。
如果按照昇腾的指标,1000卡的算力约300P,千卡就能提升约30P,万卡就能提升约300P。
“300P算力24小时可以处理数十亿张图像、数千万人DNA、10年左右的自动驾驶数据。”一位从事云计算业务的人士向光锥智能表示,提升算力效率,也就降低了计算成本。
如果说从千卡的300P到万卡的3000P还得靠堆卡“大力出奇迹”,那这10%的效率提升,背后就需要更为复杂的系统性升级。
除了整合华为的云、计算、存储、网络、能源综合优势,昇腾算力集群还进行了架构创新。
一台服务器就是一个节点,华为在计算节点层面创造性推出了对等平构架构,突破传统了以CPU为中心的异构计算带来的性能瓶颈,从而提升整个计算的带宽、降低时延,节点性能得到30%的提升。

此外,算力可是用电超级大户,尤其是上百台服务器联合起来,降低能耗也需要同步实现。
计算能力提升,服务器能耗也越来越高,传统风冷已经无法支撑高散热,就亟需解决如何能在政策严格限制PUE(电力使用效率)的情况下,仍保证服务器散热能力的问题。
在几种散热路线中,液冷被认为是主流的解决方案之一。
液冷方案本就比传统风冷方案更省电,昇腾采用了直接把冷夜注入每块芯片的精准供给方式,相比浸没式(流浪地球中放入海底的方案),可以降低日常运维的成本,也减少冷却液泄露污染环境的风险。
“精准供给取决于芯片板卡上都设置传感器、电控阀门,再加上中央控制,可以实现为不同芯片在不同的负荷下,提供精细化冷量输送。”华为计算工作人员向光锥智能介绍。
2021年11月,发改委等部门发布的文件明确指出,新建大型、超大型数据中心PUE低于1.3,而内蒙古、贵州、甘肃、宁夏节点的数据中心的PUE更是要控制在1.2以下。昇腾的算力集群已经实现低于1.15的PUE。
降低算力门槛,要靠生态
“电力是即插即用的,基本上不需要教老百姓怎么用。而算力,即便你提供给企业,很多人是不会用的。”中国工程院院士、中国互联网协会咨询委员会主任邬贺铨表示,现在算力(使用)门槛太高。
一位业内人士也向光锥智能表示:“中小企业很难得到训练服务器的技术支持,加上国产软件生态缺失,中小企业也很难自己玩转。”
即便算力集群怎么强大,需求端打不开,也终将会制约整个算力发展。而AI算力能否达到像电力一样的“低门槛”使用标准,生态尤为重要。
这也是为什么英伟达当年遭受华尔街的“白眼”,也要不计成本投入CUDA软件系统的原因。正是CUDA,实现让一个普通学生就可以进行显卡编程,英伟达进而利用软硬件协同,打造生态系统,最大程度扩大了算力供应。
除了英伟达,苹果在实现良好的用户体验方面,更早印证了生态系统的重要性。
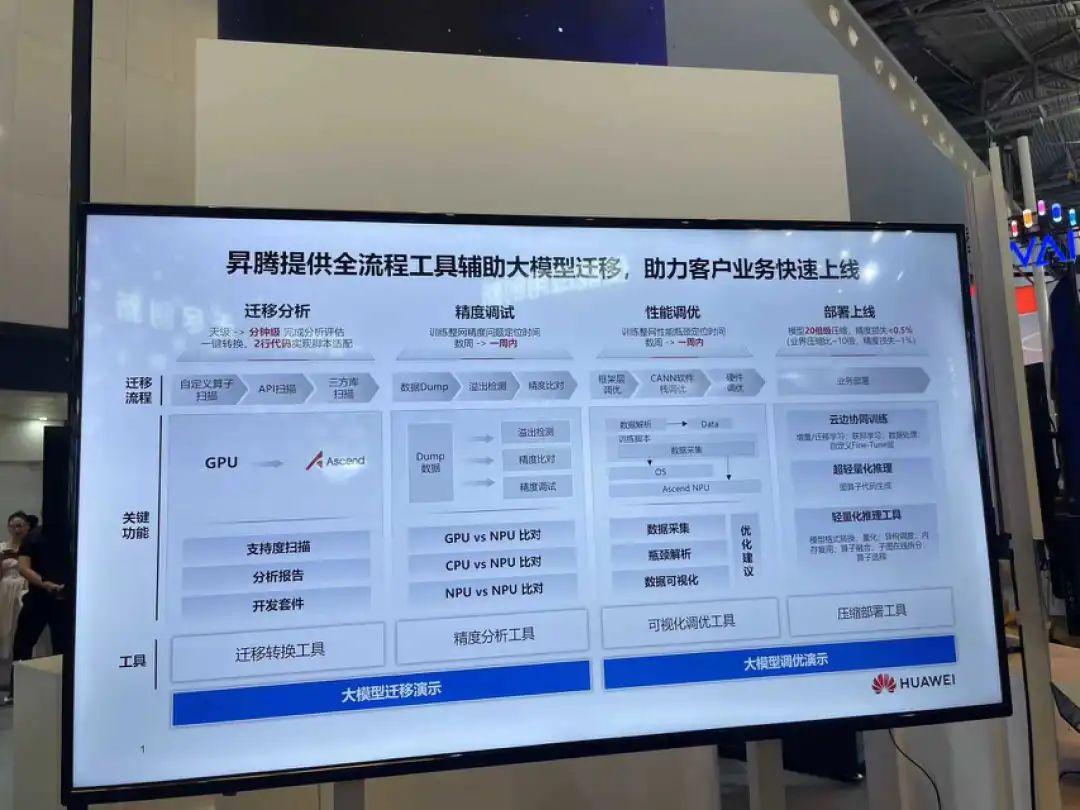
当前,华为昇腾已经搭建了一套自主创新的软硬件全栈系统,包括昇腾AI集群系列硬件、异构计算架构CANN、全场景AI框架昇思MindSpore、昇腾应用使能MindX以及一站式开发平台ModelArts等。CANN正是对标英伟达的CUDA + CuDNN的核心软件层。
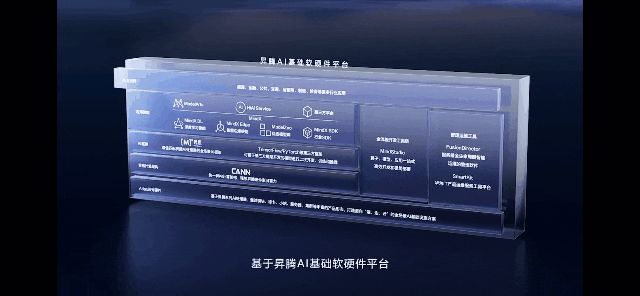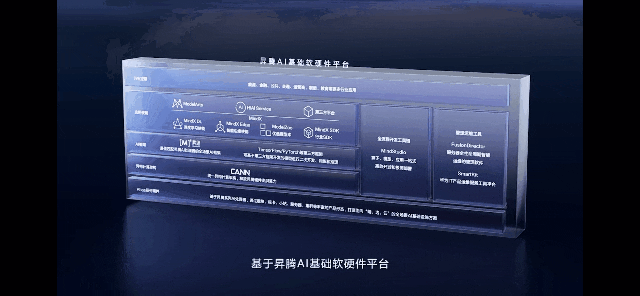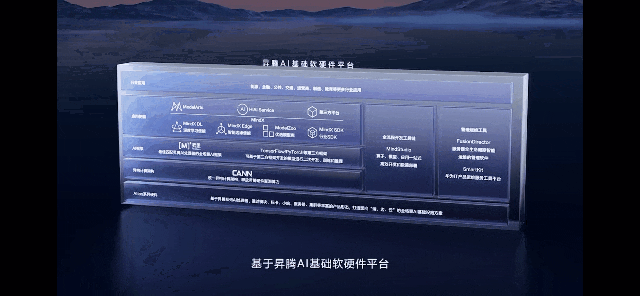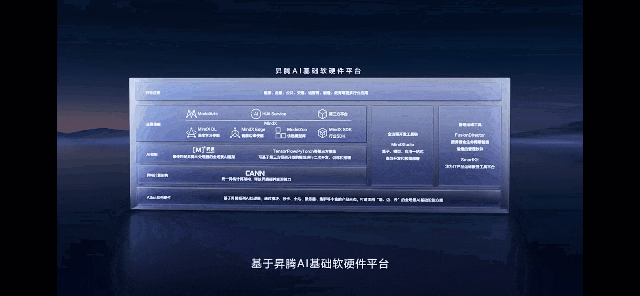
张迪煊表示,“昇腾AI支持了中国近一半原创大模型的原生创新,也是目前国内唯一完成千亿参数大模型开发并商用的技术路线,各开源的Transformer类大模型实测训练性能,可以达到业界的1.2倍。”
这些背后,则是华为将上述的软件开源、硬件开放。

首先,在基础软件上,昇腾围绕大模型开发、训练、微调、推理等全流程,进行了一系列的开源和支持。
除了已将AI框架昇思MindSpore开源,昇腾还提供了大模型的开发套件,可以支持十几行代码的全流程脚本开发。用张迪煊的话讲,就是“为了让大模型开发做到开箱即用”。
微调是大模型具备行业属性的关键环节,对应用效果起决定性作用。对此,华为昇腾提供了低参微调模块,集成了多种微调算法。张迪煊介绍,包括 LoRA、P-Tuning 等仅需 5%的微调参数,可实现全参微调的效果。
此外,针对大模型推理部署难、成本高等一系列的问题,华为昇腾在开发工具链 MindStudio 上集成了自动剪枝、蒸馏、量化工具,“精度损失0.5%的基础上,做到了20倍的模型压缩”张迪煊介绍,推理阶段支持在线分布推理,能够使应用快速上线,推理时延小于50毫秒。
“张迪煊介绍,推理阶段支持在线分布推理,能够使应用快速上线,推理时延小于50毫秒。
硬件方面,华为也对外提供主板、SSD、网卡、RAID卡、Atlas模组和板卡,来支持合作对象的AI硬件产品开发。
基于当前算力供应紧缺的情况,华为昇腾也重点针对“算子和模型”,提出了的迁移、适配的方案。
训推一体化行业落地最后一公里
在初步搭建算力生态后,能否持续良性运转,最终还要回归到大模型商业化的问题上。
“不作诗,只做事”,华为刚刚发布的大模型盘古3.0,与其他国内大模型一样,落地的重点都放在了“行业”身上。而且盘古大模型已经在天气预测、药物研发和选煤等诸多行业、超过1000个项目中“上岗”。

不过,对于国产大模型整体来说,在深度满足行业需求上,还面临一些问题。
“企业的需求非常具体,比如‘在这堆垃圾里,识别出有价值的金属’,这经过训练的小学生就可以做到,而对于大模型,企业的这种需求就太重了,而且可能最终的效果也不是很好。”企业服务商用友的一位工作人员向光锥智能表示,直接调用通用AI能力,无法满足行业中广泛存在的差异化智能需求。
华为把大模型分成三个层级,L0、L1、L2。L0就是基础通用模型,在基础模型L0的基础上,加上行业数据,混合训练得到的行业大模型是L1,然后再把L1针对具体下游千行百业的细分场景进行一些部署,得到细分场景的任务模型L2。
现在,无论是对于华为还是其他大模型企业,如何从行业大模型L1中快速生产L2模型,还有部署L2模型到端侧、边侧和云侧,成为打通行业应用最后一公里的问题。
针对这最后一公里,昇腾联合科大讯飞、智谱AI、云从等上游的大模型合作对象,提出了“训推一体化”方案。

简单理解,做模型训练就相当于大学学习阶段,推理部署(训练好的模型在特定环境中运行)就是正式上岗,训推一体化就是“边学习边实习”。
通用大模型一般都是基于广泛的公开文献与网络信息来训练,信息混杂,许多专业知识与行业数据积累不足,会导致模型的行业针对性与精准度不够,数据“噪音”过大。同时,又由于行业数据获取难,技术与行业结合难,大模型在行业的落地进展较慢。
训推一体化,支持中心节点将模型下发至企业的边缘节点进行推理,边缘站点再将数据回传至中心,进行算法更新和增量训练,实现自主演进能力。也就是,“学生主动向更适应就业岗位的方向深造”。
这样一来,就保证训练到推理的循环生产流程不再割裂。并且把发展行业大模型更大的主动权,交到了行业和企业自身,无疑能最大化满足行业的AI应用与开发场景,实现AI基础设施与行业需求深度融合。
相较于中心训练、边缘推理,训推一体化对于中小企业来说,部署成本也会更低,更会加速中小企业加入行业、场景大模型的“培养”。
对于整个算力生态来说,尽快打通这最后一公里,也就意味着被真正激活,才会有可持续的发展。
本文来自投稿,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/quan/101562.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 