
《增长黑客》是一个带给拥有核心价值产品实现用户增长和转换一套思维体系。旨在通过数据分析,花更短的时间和最少的费用去帮助产品快速实现“拉新、留存、激活、营收”过程。实现这个过程的关键点又在于不断的发现问题、优化问题和解决问题。
书中用理论和实践案例,阐述了在AARRR各个阶段为了用户增长和转换而提出的许多实用的数据分析、增长实验的方法。
而以数据说话无疑成为整个增长过程是否成功的基础。
如何快速知晓你的产品没有市场
在阅读过程中,“如果本身产品就有问题,是否有必要建立增长团队开展增长试验呢?”这个问题一直出现在我脑海中,所幸的是第一章最后就给出了否定的答案。
如果你的产品本身就没有市场,或是市场过于小众,那么就算是有资本最终都是回天乏术。
而如何去快速知晓我们的产品是否有市场?这让我想起了“羊和草地”的定位方法。这种方法还可以让我们清晰的意识到“产品是否有问题?”、“我们的产品是否有问题”。
“羊和草地”实则是YY的创始人和董事长李学凌分享出来的一种“用户画像”理论,但我觉得其更像是一种快速定位论。这种方法区别于usp和增维定位法的是,他强调产品在增长前,首先得有一块草地(产品面世最初的预设目标市场或是小范围试错出来的市场即是草地),而首批用户即是羊,羊来了羊走了、走了的羊又回来了、羊来了吃的开心、羊来了不想再来……这些情况都反应着你的产品是否有市场,市场是否小众。最终给公司经营者一个信号:是否需要继续做?!需要在哪个环节发力从而快速增长下去?
数据可能告诉你的经验或你眼中的世界都是错误的
在增长黑客工作流以及增长团队的岗位要求中“数据”是第一步骤,可见“数据”的重要性,而数据的最大敌人就是“经验”这个以往的认知。
让我想起了一本由Hugo老师推荐的书,瑞典医学教授Hans Rosling的《Factfulness:Ten Reasons We are Wrong About the World(事实:我们误解世界的十个理由)》,书中罗列了许多问题,最后给出的答案会让你恍然大悟“哇哦,原来这个世界上并不像我们想像的那样”,而全书旨在说明一个情况,那就是“你眼中的事实”往往和真相南辕北辙,这就是所谓的“认知偏差”。
下面我们来看看书中罗列的13个问题,你可以试着回答一下。
“
先诚实回答以下13条问题(不要百度):
1. 在世界上所有的低收入国家中,有多少女孩读完了小学?
A. 20% B. 40% C. 60%
2. 这个世界上大多数人生活在什么样的国家?
A. 低收入国家 B. 中等收入国家 C. 高收入国家
3. 在过去20年内,全球极端贫困人口在世界总人口的比例发生了什么样的变化?
A. 几乎翻倍 B. 几乎没有改变 C. 几乎减半
4. 当今世界的预期寿命为:
A. 50 B.60 C.70
5. 目前,全球儿童人口(0-15岁)大约为20亿。据联合国预测,到2100年,全球儿童人口大约为:
A. 40亿 B. 30亿 C. 20亿
6. 据联合国预测,到2100年,全球人口将增加40亿。这个变化主要来自于:
A. 会有更多的儿童(0-15岁)
B. 会有更多的成年人(15-74岁)
C. 会有更多的老年人(75岁及以上)
7. 在过去100年中死于自然灾害的人数发生了怎样的变化?
A. 翻倍了 B.没有改变 C.减少了一多半
8. 目前全球人口大约有70亿。下面哪个地图最准确地反应了人口的分布?(每个人像代表10亿人口)
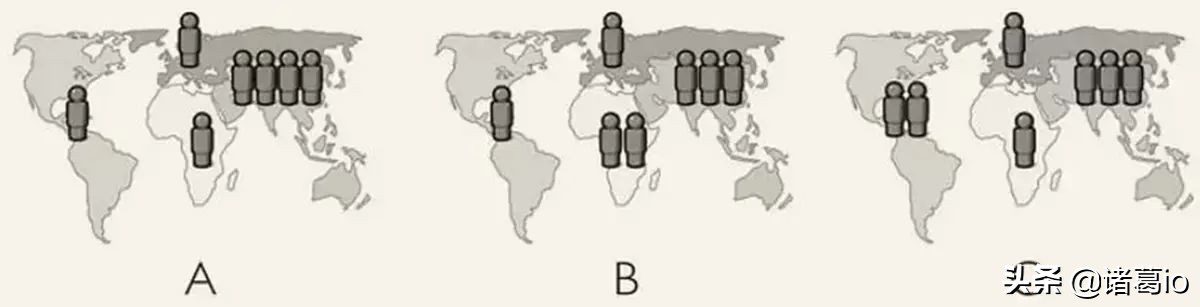

9. 世界上有多少1岁的儿童接种了某些疾病的疫苗?
A. 20% B. 50% C. 80%
10. 全世界目前30岁的男性平均接受了10年的教育。那么同龄的女性平均接受了多少年的教育?
A. 9年 B. 6年 C. 3年
11. 1996年,虎、熊猫和黑犀牛被列为濒危(Endangered)动物,这三个物种中,目前有几个变成极危(Critically endangered)?
A. 两个 B.一个 C.一个也没有
12. 世界上多少比例的人有电用?
A. 20% B. 50% C. 80%
13. 气候专家认为,在未来100年间,全球平均气温将会
A. 升高 B.保持不变 C.降低
现在看看正确答案:
1.C;2. B;3. C;4. C;5. C;
6. B;7. C;8. A;9. C;10. A;
11. C;12.C;13. A
”
如何
你答对了几道题?
值得“庆幸”是“哈哈,我居然和老师Hugo一样只答对了四道题”
如此,你还相信你的经验吗?
如何选取数据分析中的各个指标才可能是正确的?
全篇读完,我发现“消费者购买地图”的每一个环节遇到的难题和对应的解决方案,都可以是完成一次增长黑客的过程。
这个过程不在像完成“拉新,激活,留存”那样还要寻找啊哈时刻和制定北极星目标,而是以本环节的数据分析开始,对比不同用户群体(不同类型)的差异行为进行对比,找寻用户形成差异化结果(动作)的原因,继而提出不同的增长实验,以期解决相关问题(通常是让一类用户的行为变成和別种类型用户一样,好比a类用户一月消费额和次数为10,b类用户是5,那么这个增长就是想将b的购买行为靠近a)。
而另一个值得思考和难懂的,是如何去进行数据分折、关注哪些指标才是正确的、哪些数据才能看准问题…如书中引用的下面这个例子:
“对于电商企业来说,除了按照顾客的消费额来划分群组以外,其他重要的划分方式还包括顾客购买量、订单的平均金额、所购商品的类型、第一次购物的日期、在某个时间段内的购物次数(比如每月或每年)以及他们通常购物的月份或年份。比如,团队发现,90天内只购物一次的用户中在接下来的12个月里消费额达到甚至超过500美元的比例是55%,但90天内购物两次的用户这个比例是95%。因此,团队可以设计一些试验鼓励所有在90天内购物一次的用户在这期间购物两次。比如,团队可以在用户第一次购物30天后通过邮件向他们提供巨大的折扣或者特殊优惠(例如免费配送),然后60天后再发送一次这样的邮件。”
上面的数据分折团队为什么会以90天和12个月为分折周期?为什么会以500美元作为一个参考分折项?
为了找到这个答案,我努力的回忆去年在做电商时的一次体验,到时我们拥有十来家电商店铺,营收最大的一家店铺是一个独立的团队运营,其它每两至三个店铺由一个团队运营,整家公司有近千个sku的商品,我们决定要缩减商品sku数量,我们在后台将一个月和一年的销量(考虑一年是因为考虑到商品在促销季和自身的季节性销售差异)进行了对比。
1.首先我们剔除了一月和一年销量都平平的商品
2.既而我们按(近一月行,一年不行;近一月行,一年行;近一月不行,一年行)分别进行了分折
3.把每一种分类法的销量、总销额、总毛利贡献值进行对比,最终确定了第二批要剔除的商品名单
貌似这次经历并不能回答上面的问题。
那究竟如何做,才是正确的方式?我想应做到这些点:
1.大数据里用户消费周期作为一个时段
2.寻找在这个时段里的共性数据值或用户行为特征去套用户行为的结果
3.寻找最靠近的数据指标
4.小试验试错
……
感觉还是很难懂吗?
嗯
再简单点就是两点
1.忘掉经验让你以为什么应该什么的逻辑
2.先大胆的寻找共性,然后大胆去认为这些共性与结果的联系
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/quan/53177.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫