
昨天在某个程序猿的公众号里,听了一下午阿里算法资深专家小二分享《2022年目前淘系算法的内部资料》。
今天就把小二分享的部分ppt截图出来,并且给大家深入浅出的解读一下,现在淘系的搜索算法,是怎么工作的。
排序算法的背景问题
先看第一张ppt,目前小二举例的时候,一般会用两个类目,一个是服饰,一个是3c。
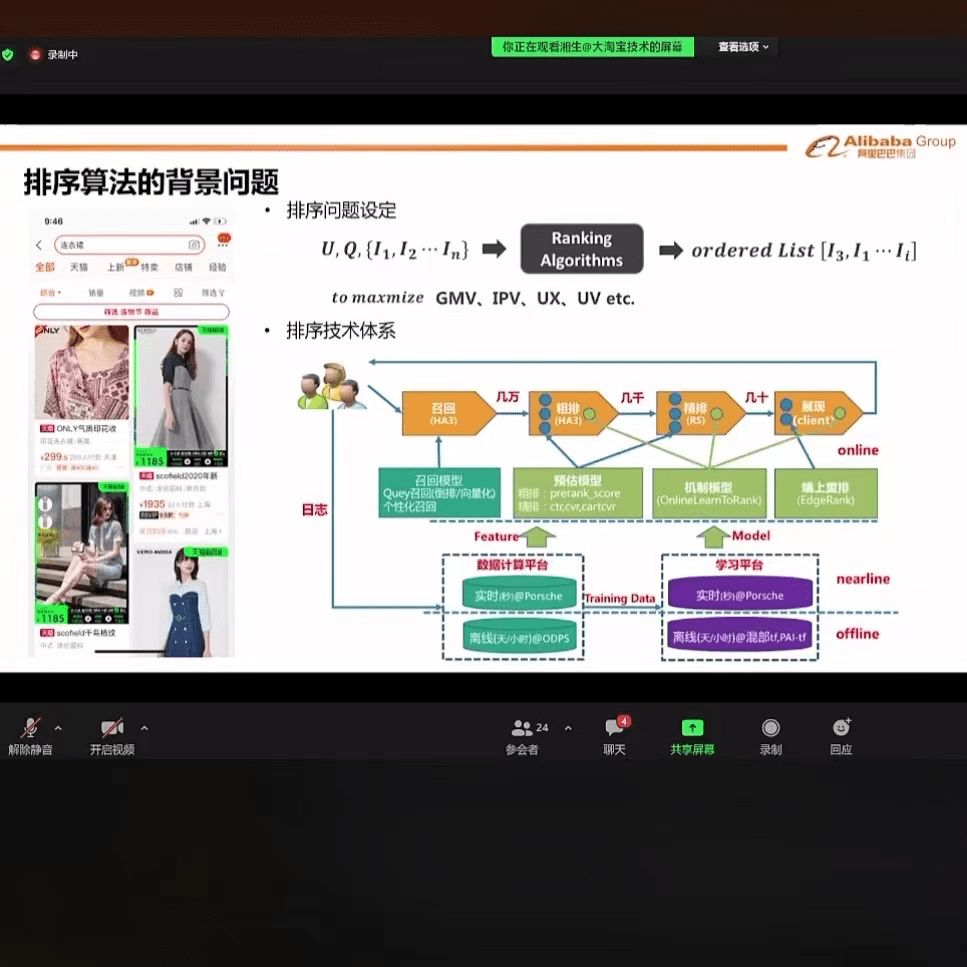

往往以服饰为主,3c数码配件类目,作为差异化参照物。
也就是说,研究淘系算法,用服饰类目的产品去研究,才能了解最前沿的算法改变。
先说了淘系搜索目标,是多目标,比如gmv(平台交易总额),ipv(进入商品页的点击次数),ux(用户体验)等等。
基于这多目标,算法工作的流程是:
- 1.用户有了搜索关键词行为。
- 2.通过召回模型,在数据库里匹配几万个商品。
- 3.通过预估模型,在几万个商品里,找到符合要求的几千个商品。
- 4.通过极致模型,利用人工学习算法,精选几十个最符合的产品,进行展现。
算法工作的过程,最终实现的目标,是为了实现交易总额,搜索结果点击率和用户体验,这三个核心维度的最优化。
【注意】
不完全把交易额,当成唯一目标。早期淘系就是解决刚需,转化就是的唯一目标。
但目前淘系不仅想要刚需市场,也想要“种草”市场。
而种草的核心表现,不是立刻购买,是唤起兴趣,而唤起兴趣的具体行为,就是点击。
【结论】
点击率,无比重要!
从LR到深度模型
第二张ppt,淘系从2017年开始进行的深度学习,也就是千人千面。

算法从原来的单一销量维度,到现在的单场景多任务。
这里的场景,是指主搜索场景,天猫搜索场景,店铺内搜索场景等,我们卖家关注的,就是主搜索场景。
在主搜索场景下,有多任务:
ctr(曝光点击率)cvr(转化率),加购率的最优结果。
我们不需要知道,具体算法怎么工作的,只要知道算法的结果是为了点击率,转化率,加购率最大化。
那我们想拿搜索流量,就要围绕着点击率,转化率和加购率这三个点,去选产品就可以。
【注意】
从头到尾,没有提uv价值这个数据。
手淘深度预估模型的基础结构
第三张ppt,预估模型里(从几万个粗排结果,到几千个结果的过程)最核心的工作,是在曝光没发生前,预估点击,转化,加购的概率。
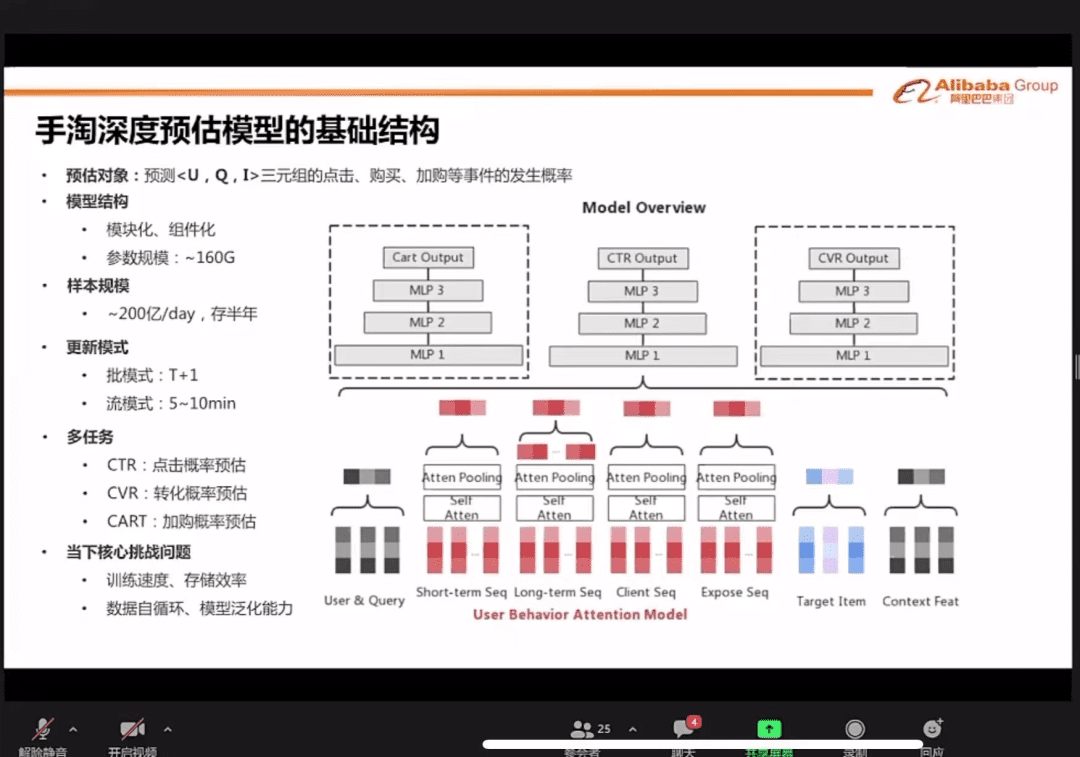
预估之后,根据反馈进行排序更新:
1.批模式更新,就是累积一批数据,统一处理,这个时间周期是一天,每天早上8点更新。
2.流模式更新,流动数据处理,处理时间是5-10分钟(抖音,直播间的算法)。
淘宝的更新模式,是批模式+流模式:
- 1.在一天之内流模式不断更新。
- 2.第二天早上8点左右,把一天累积的数据,再批处理一下,做大更新。
- 3.然后流模式再基于批模式的更新结果,继续实时更新。
【注意】
搜索批模式,每天都会更新,如果你流量没变化,那是说明你产品赛马没过关,所以停留在原来曝光池。
在这里我们看到,商品数据中,因为成交延迟的问题,所以比起抖音,直播,做实时排序难度更大。
抖音用户刷到某个内容,喜欢就关注了,没关注后面也不会去找了。
但淘系用户看到某个商品,当时没买,有可能过一周后,又找出来买。
用户个性化的多维视角
第四张ppt,在得到精排的几千个结果之后,会基于用户信息,把结果基于用户反馈。
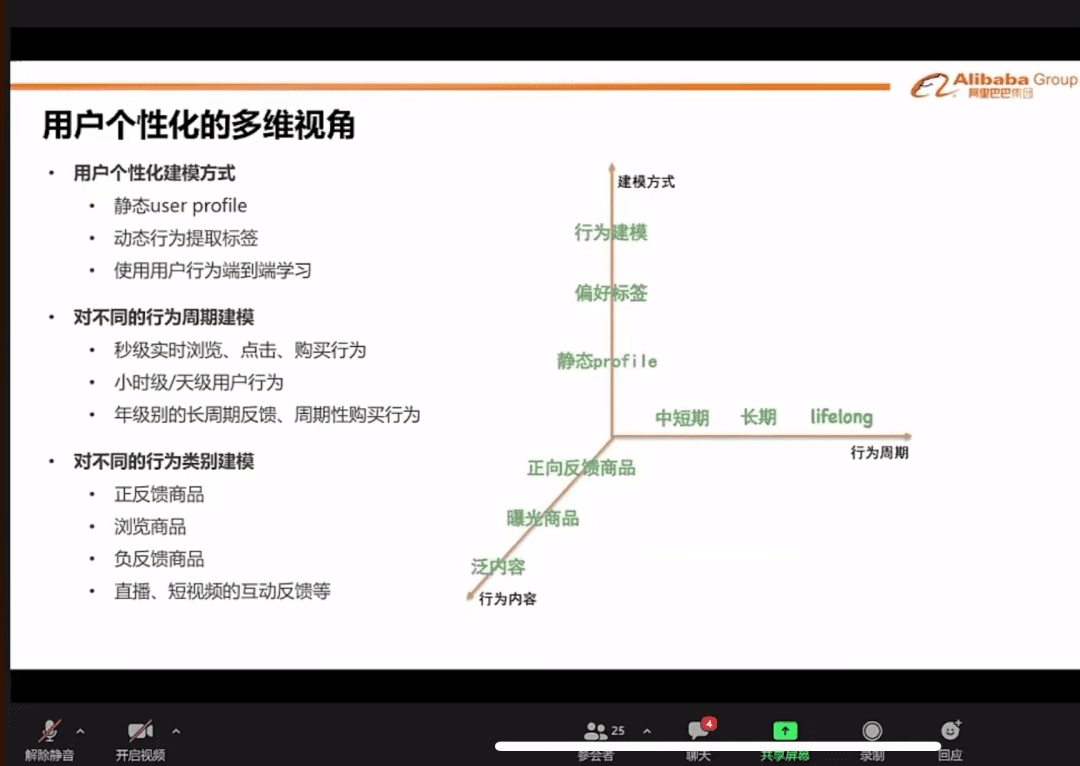
做千人千面的展示,而千人千面主要关注下面3个维度数据:
一、关注用户资料:
1.用户的注册信息,年龄,性别等。
2.动态行为提交的标签,浏览过的店铺。
3.基于用户行为,学习到的数据资料。
二、关注用户行为周期:
1.秒级行为:浏览,点击,购买。
2.小时级和天级行为。
3.年级别的反馈,复购。
三、关注用户行为的类别:
正反馈加分 :点击 ,加购,购买。
负反馈减分:停留时长短,曝光未点击。
之前我们只关注“正反馈”结果,但今天听小二分解,他们更在意的是“负反馈”,因为比起正反馈,负反馈数据量更大。
一个搜索结果页面,没有点击的产品数,往往比点击的商品数量更多。
负反馈行为举例:曝光未点击,点击未加购。
【结论】
如果重视负反馈数据,也就意味着,只要产品不行,绝大多数的增加曝光量“运营”行为,都是自杀。
用户行为序列模型
第五张ppt里,重点讲解了行为模式下,是怎么打分的。
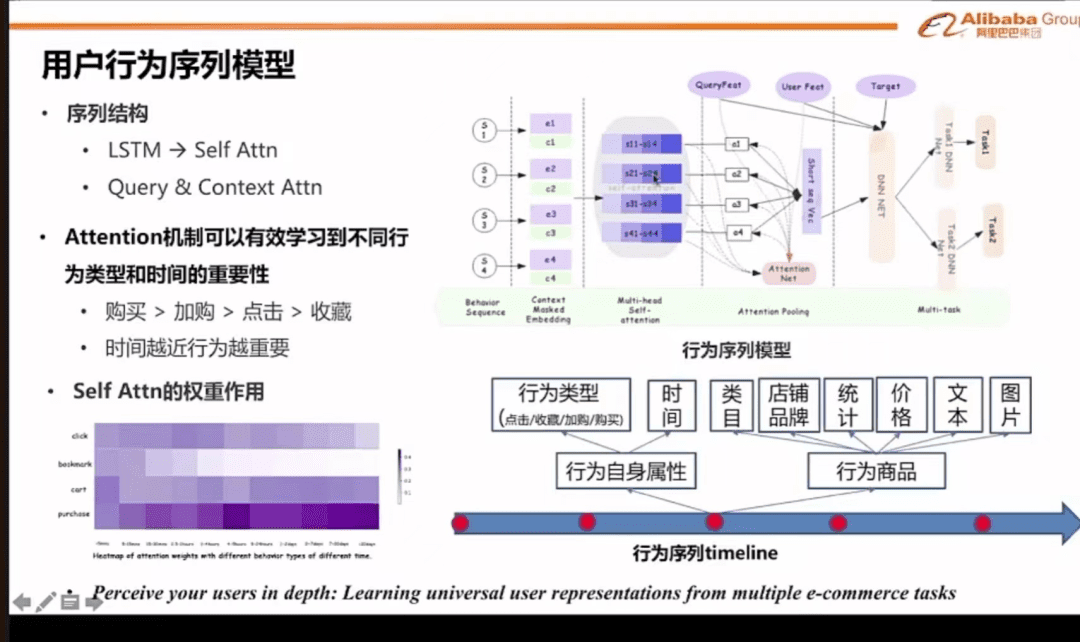
行为打分的重要性排序:
购买>加购>点击>收藏
这个重要性排序的原因,是发现距离购买的时间越近,动作行为越重要。
比如,收藏的往往近期不下单,加购的很快会下单,所以加购比收藏更重要。
搜索的机制模型的排序算法,本质上就是基于用户行为打分,正反馈加分,负反馈减分。
而不同的正反馈,加的分值不一样。
比如购买+10分,加购+7分,点击+3分,收藏+1分
同样道理,不同的负反馈行为,也会减不同的分值,货比三家加分并不是最多,曝光未点击应该最多。
【结论】
点击率,是商品搜索里最重要维度。
在线学习
第六张ppt里,列举了在线学习的难点和解决办法。
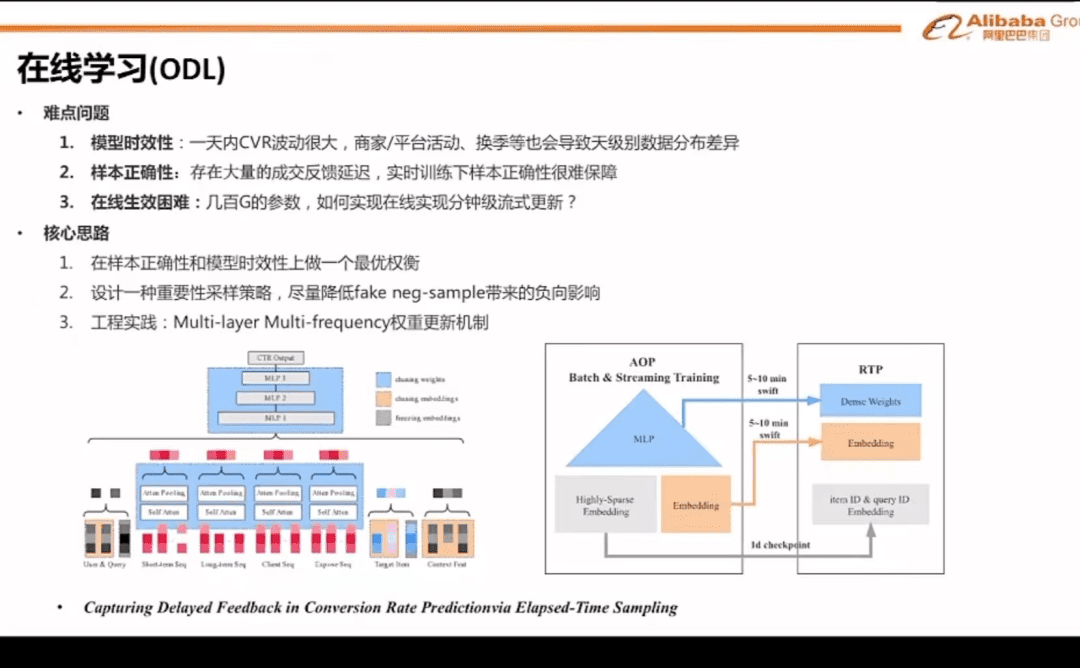
1.时效性:
比如现在春节前,和春节,红色相关的产品,反馈表现很好。
但春节一过,反馈就会出现很大差别。
这个就是我研究小红书的最大收获,我们发现小红书的笔记,都要讲究“天时”。
天气变化,节日,甚至电影,电视剧,热搜,甚至比产品本身,更影响用户的行为反馈结果。
所以,中小卖家的逆袭机会,都出现在预测“天时”。
我们也做了一个表格,什么时间发什么样的笔记,能顺应“天时”,想要的可以联系108将社群里,你的专属班主任索取。
【解决办法】
算法在样本重要性和时效性上,做权衡。
2.正确性
成交反馈延迟,这个是我之前反复说到的。
家具类目,如果用成交作为反馈,转化周期长,反馈的准确性就会很低。
比如,这个用户点击了某个产品,未购买,系统如果把它当成负样本,准确性就大大降低。
【解决办法】
新的重要性采样策略,把加购当成“流模式”更新的维度。
不断地用“批模式”反馈结果,来升级流模式算法。
3.算力问题
数据量级太大,在线实时更新,对于算力要求太大
【解决办法】
从客户端和云两个方向,做数据更新。
客户端上的数据,不上传到阿里云,这样利用了客户手机的算力,来实现千人千面。
商品的多模态表示学习
第7张ppt,里面提到了搜索学习商品的特征信息包含哪些。
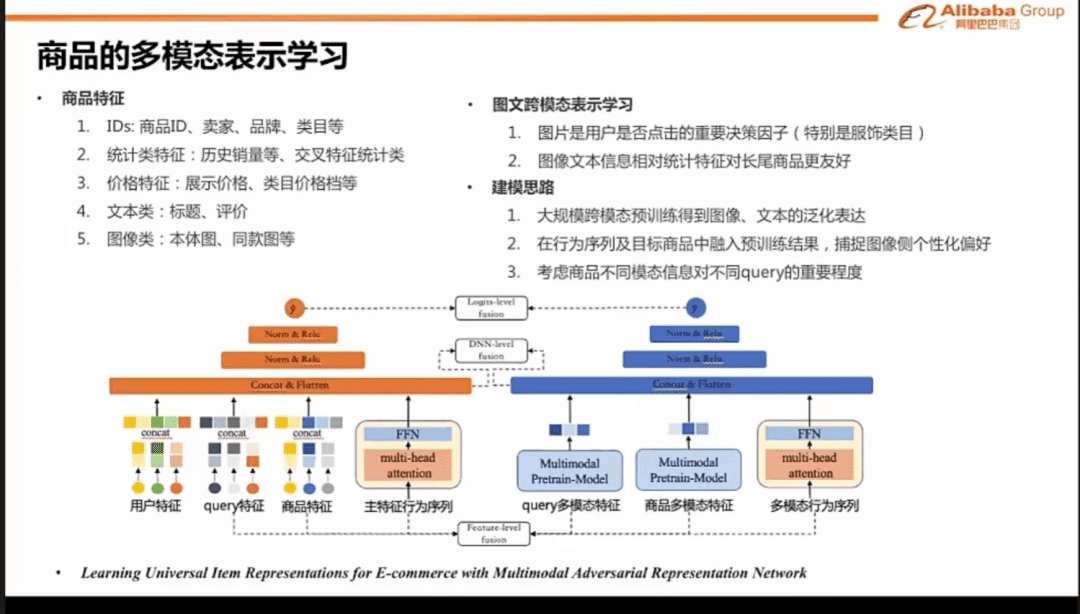
1.商品信息,卖家信息,品牌信息,类目信息
2.销量信息。
3.展示价格,类目价格档(价格千人千面依据)。
4.文本信息:不仅抓取标题,还会抓取评价里的文本。
5.图像信息:产品图,同款图(同款打散)。
【重点】
连衣裙举例,主图展示的款式,是服饰品类的点击率预估的重要标准。
也就是说,搜索可以通过图片识别,把图片款式识别成“风格”,然后把产品推送给喜好相应风格的人。
产品的款式,款式的背景,都会影响到图片识别的款式。
【举例】
我喜欢干净的图片,所以我在小红书里刷到的都是干净的图片。
但是我看别人小红书刷到的,都是牛皮癣的,说明主图制作的风格,也会影响到人群千人千面。
系统创新
最后一张ppt,里面提到了目前淘系搜索的一个创新。
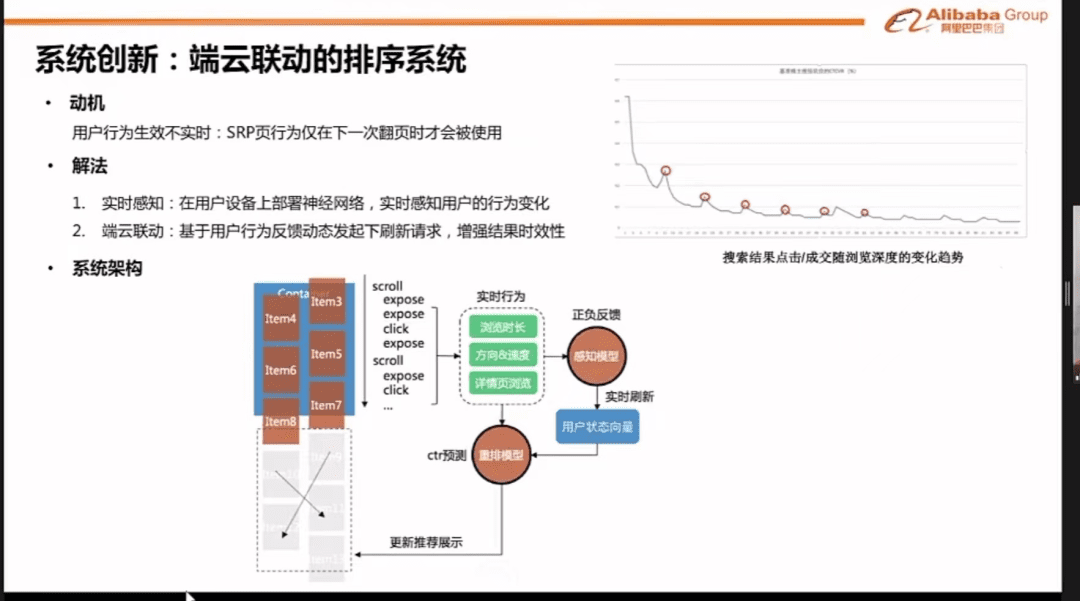
为了降低数据处理的量级,在用户客户端(手机,pc)建立神经网络,这样客户行为数据,就不用上传到阿里云,也能实现顾客手机端的千人千面。
【举例】
你搜索到第一屏结果,有了点击行为,那么你第二屏的排序,就会基于你第一屏内容的行为,进行实时的排序变化。
好了,我们今天的2022年最新淘系算法的解读,就到这里。
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/quan/57786.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫