
导读:B站千亿级数据同步,每天100T+数据导入是如何实现的?本文将介绍Apache SeaTunnel在哔哩哔哩的实践。包括以下几方面内容:
- 工具选择
- 日志
- 提速/限流
- 监控自理
01
工具选择
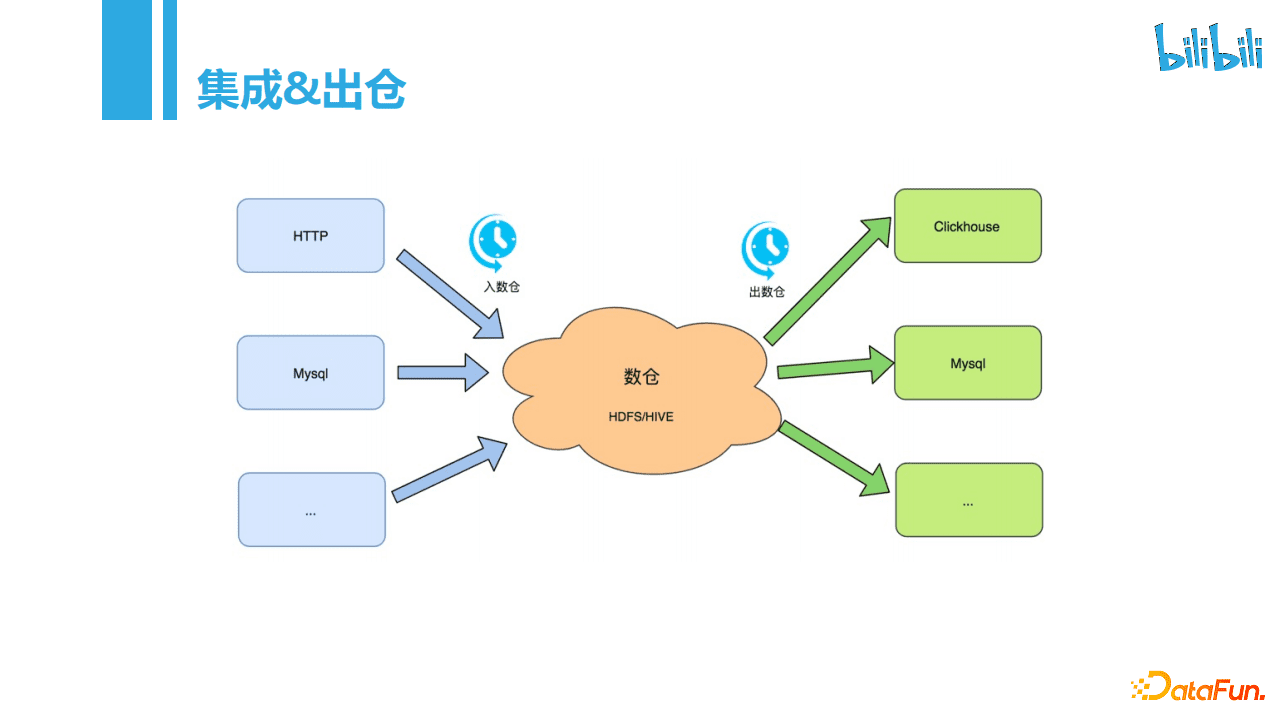
数据集成和数据出仓的大体流程如下图所示,主要以数仓为中心,从HTTP、MySQL等外部数据源抽数入仓,在数仓内做相应业务处理后,出仓到对应的Clickhouse、MySQL等存储,供业务使用。

B站数据平台在离线出入仓工具上目前主要有两类。一类是基于DataX二次开发的Rider项目,另一类是基于Seatunnel 1.1.3二次开发的AlterEgo项目。
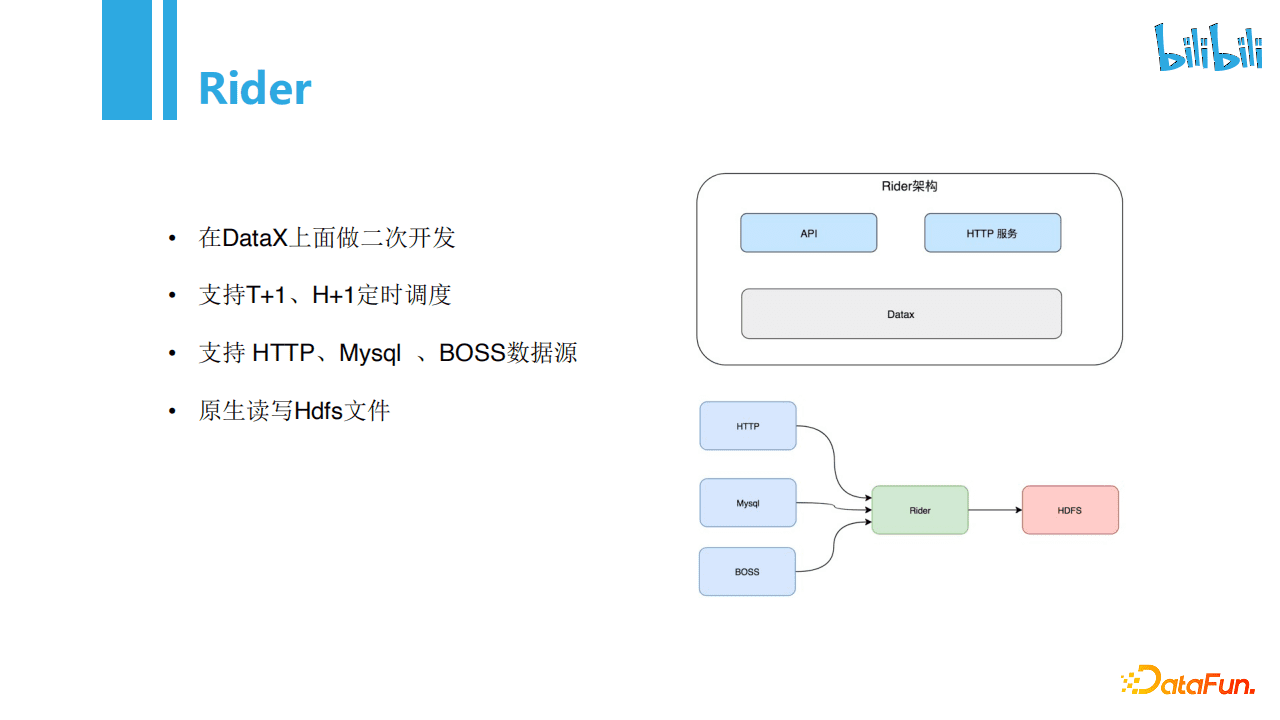
上图展示了Rider的架构。
Rider在使用上支持T+1、H+1定时调度,在数据源上支持HTTP、MySQL、BOSS等作为数据源,此外Rider在使用上主要原生读写Hdfs文件。
DataX虽然在单个进程下已经足够优秀,但是不支持分布式,另外在大数据量下表现不是很好,Seatunnel在分布式场景下表现优秀,一方面构建在spark之上,天然分布式,另外且自带了很多插件,非常适合二次开发。我们调研后,在Seatunnel基础上二次开发了AlterEgo项目。
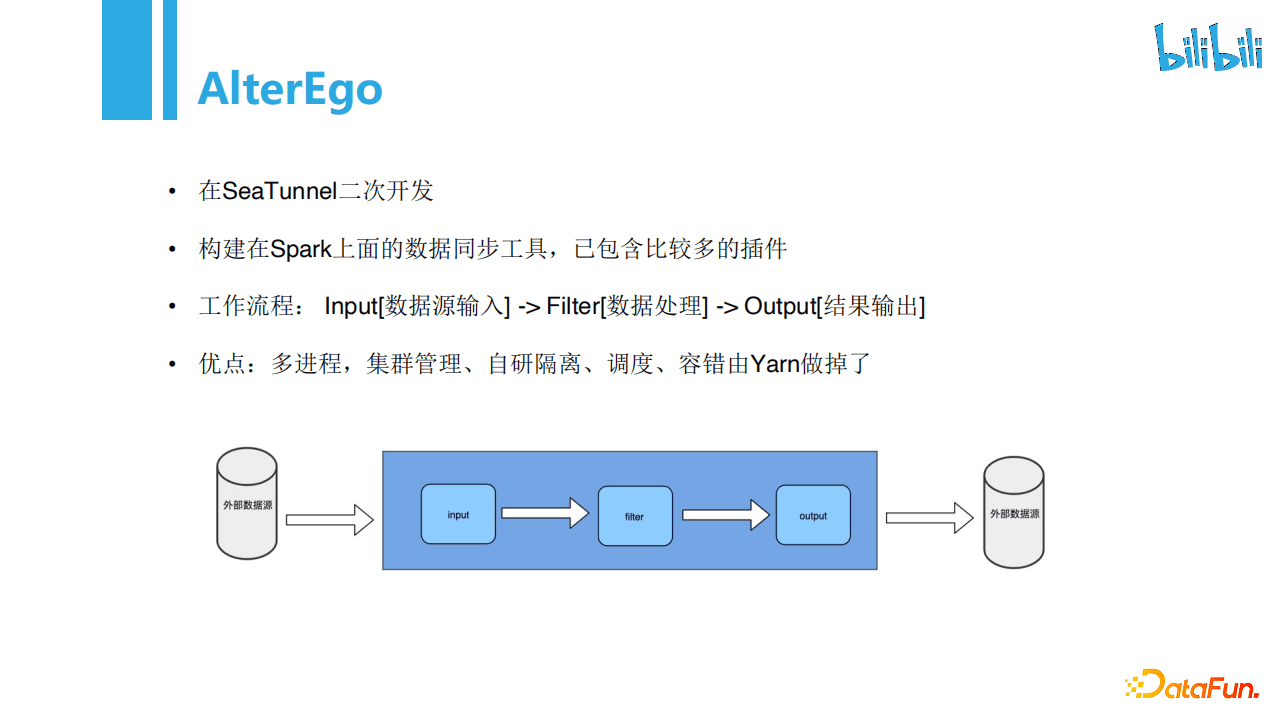
AlterEgo的工作流程:Input[数据源输入] -> Filter[数据处理] -> Output[结果输出]。
集群规模方面,由于历史原因,目前离线集群与出入仓工具集群是分开部署的。出入仓工具集群节点数20+,CPU核数750+,内存1.8T+;每日出入仓调度任务同步数据方面,日均记录数上千亿,日均数据量在100T以上。
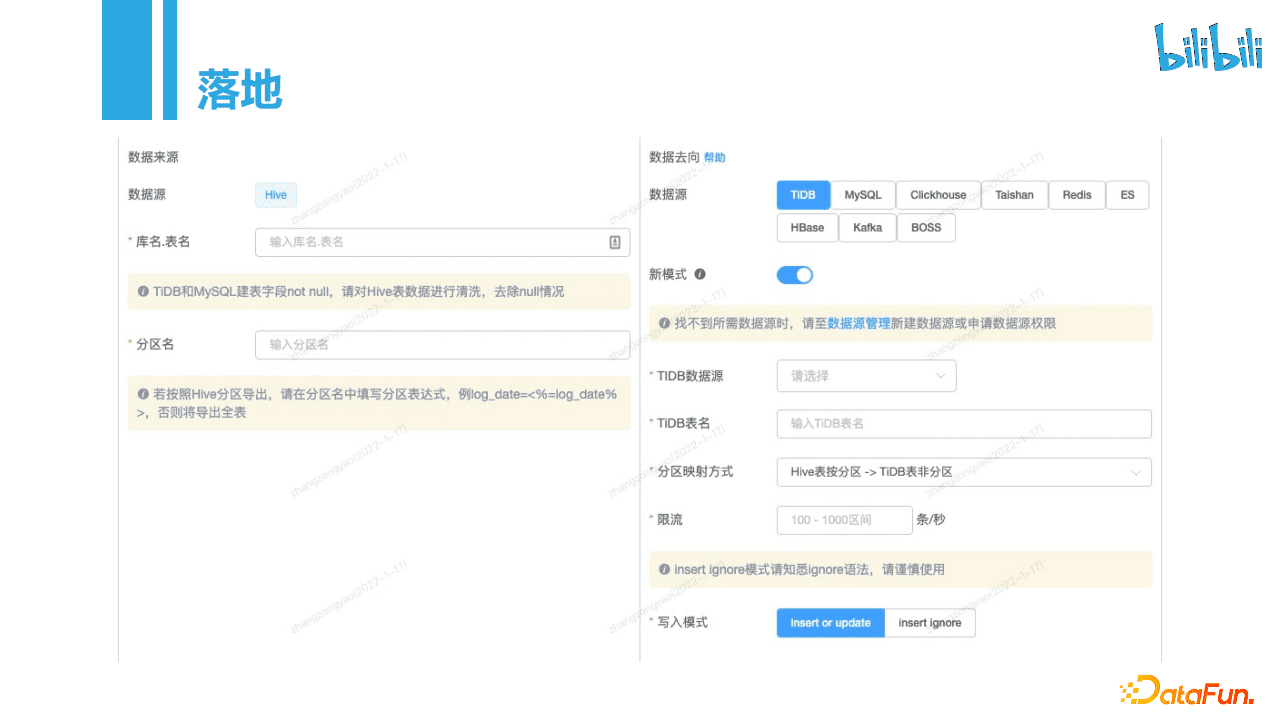
在落地方面,主要提供了界面化操作,对任务做了抽象和封装,平台化后提供给用户使用。平台会根据用户不同选择,把任务封装为Seatunnel的配置格式或DataX的Json格式配置。目前平台的功能如图,用户可以选择数仓数据源的库名、表名和出仓后存储的目标数据源的信息。这里为了管理接入血缘考虑,和安全规范使用流程,用户在界面内不被允许填写用户名密码,可以选择对应创建的数据源。在存储个性上,比如为兼容MySQL协议的数据源的导入上,支持了Insert Ignore、Insert Update方式导入数据。字段映射可以通过界面上拖拽完成配置。
在任务运维界面,通过DAG查看调度任务上下文,出仓和入仓的整个过程中,任务是互相依赖的,前面的任务出问题会导致后面的任务产出慢、数据延迟等。因此排查问题的过程中,往往需要在任务DAG中找到上游依赖最长的链路或是未完成链路并排查问题。
02
日志
平台化落地其实难度不大,套个皮就可以了,但是很多时候我们要考虑的是面向运维开发,细节都是对用户是封装好的,需要为用户提供足够的运维工具支持。这里以日志为例,排错是很常见的场景,当用户排错时,用户并不希望看到密密麻麻且无用的Yarn日志,但如果使用spark日志,由于Spark环境配置繁琐,直接暴露Spark UI给用户也会让用户的使用体验不佳。此外,在后期我们整合入离线大集群后,集群节点数目有四五千个节点,集群规模大就导致日志聚合会慢,日志响应时间长。
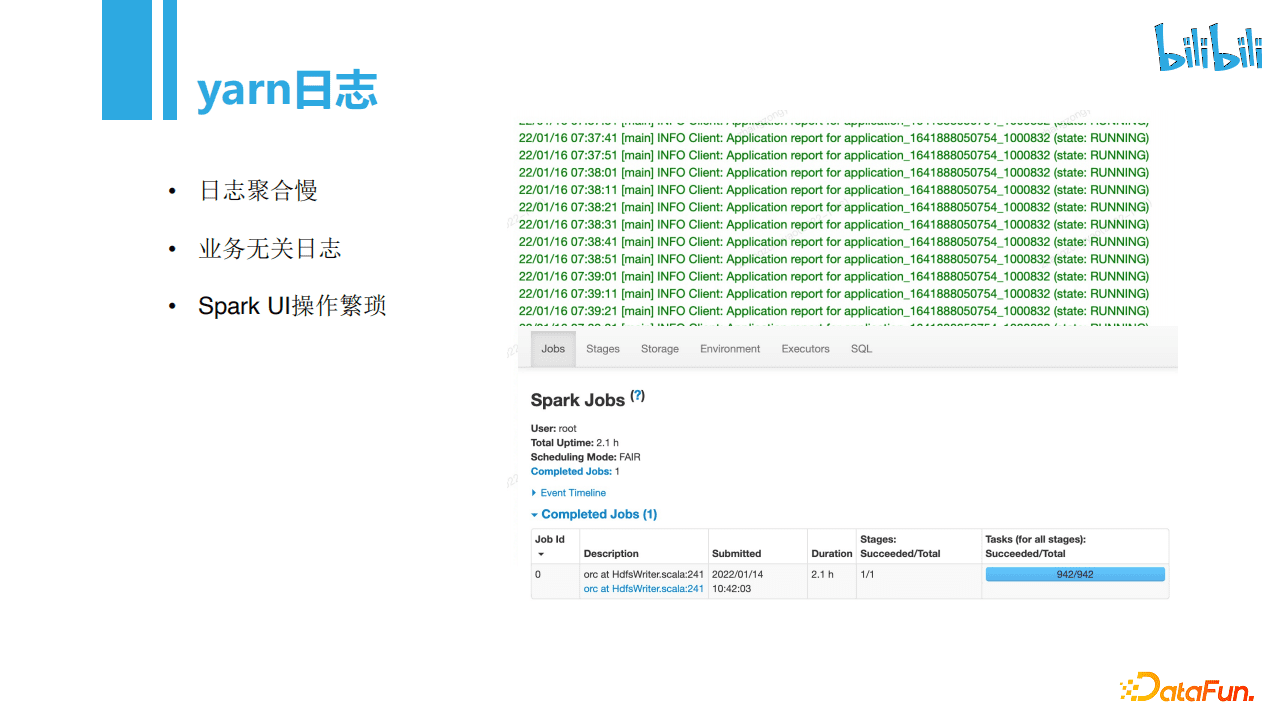
为解决日志查询困难的问题,我们对日志层做了优化,在Spark上使用LogAgent把业务日志转发到我们的日志服务上。为方便查询,且让日志历史信息可追溯,LogAgent在日志中追加了jobId、jobHistoryId、priority等信息。这样采集日志后,我们会根据日志内信息做各类告警,例如当任务出仓条数为0时发送告警等。此外,当日志有报错打出,用户可以直接在日志界面展示的日志里定位程序的问题,所有操作直接在平台就可以完成,而不需要其他复杂的配置。
03
提速/限流
- ClickHouse出仓
Clickhouse数据出仓方式有三种:
写分布式表:写入性能偏低,代码比较简单,不需要依赖RDD Repartition。
写Local表:需要在本地做一次repartition,会有性能压力。但写入性能会更高,和写分布式表一样,主要用Jdbc协议。
BulkLoad:BulkLoad将写压力前置到Spark层,写入速度快,降低了Clickhouse侧压力,写入不影响读性能,做到读写分离,更加安全。依赖的是文件复制。
Clickhouse出仓任务调度记录达到60亿以上,数据量达到13T以上;手动补数据数据量在70T,数据量和记录数都在不断增长。
- 创作中心-出仓加速
简单介绍下我们对创作中心的数据出仓做了一系列优化,加速了数据出仓过程。
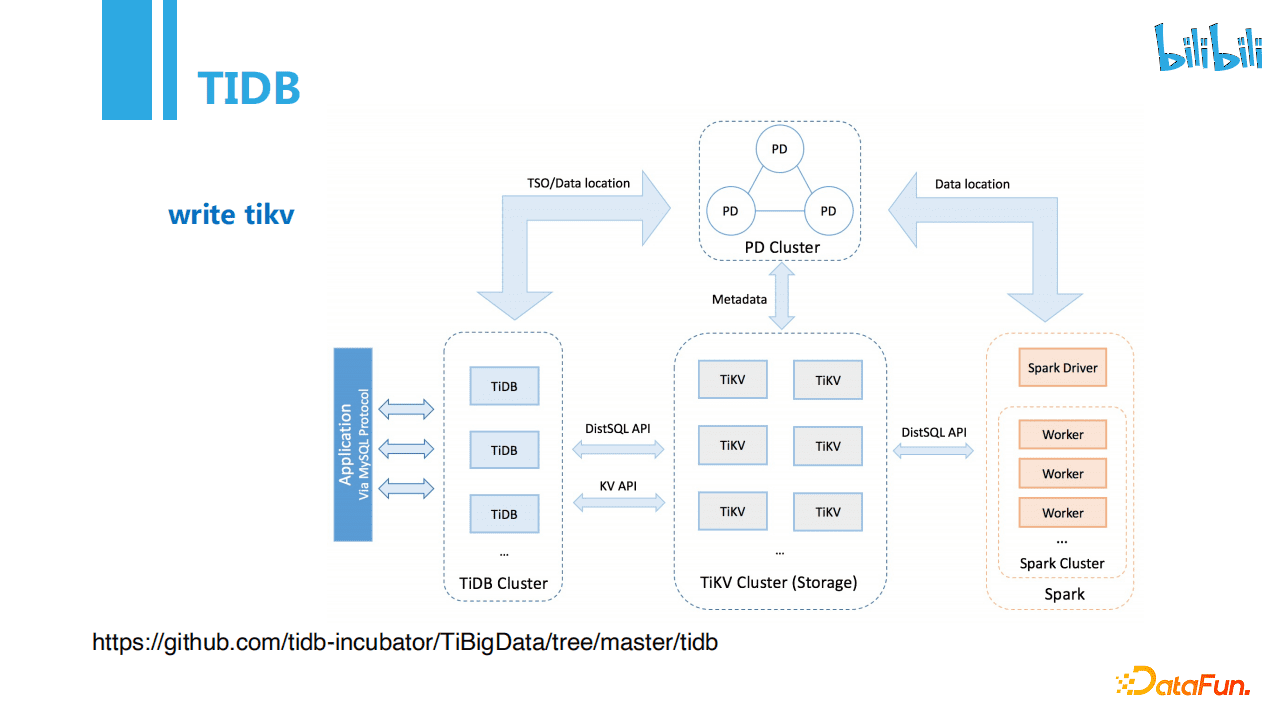
创作中心使用大量使用TiDB,我们利用jdbc协议批量写数据。当写得快会导致TiDB-Server IO高、压力大。另外在数据出仓过程中,可能有新建分区表的需求,当出现DDL操作时,写入很容易出现Information schema is changed导致失败。如果存在更新数据场景,也会由于Insert update时需要把数据全部读出,当任务出现失败后重试时任务耗时会增长,性能降低。此外,TIDB集群是有限的,多个业务同时写入TiDB时候会出现多实例竞争写入资源,导致写入时间耗时增加。
以上问题,我们的应对方案主要是基于业务大都为KV查询,用自研的分布式KV存储TaiShan替代TiDB。创作中心业务主要集中在点查和Range查询,比较适合KV类存储。TaiShan是B站自研的分布式KV存储,经过多次出仓实际压测,TaiShan的Batch写入方式和TiDB性能接近,实际使用并没有多少性能提升,写入多时也会影响到读的业务。我们最终采用正在做的Bulk Load方式写入TaiShan。Bulk Load优化和前面介绍的Clickhouse的优化类似,将写入压力前置,放到SeaTunnel层来生成数据文件;对于业务库能实现简单的读写分离,但可能会存在一些热点问题,需要前置一次repartion。
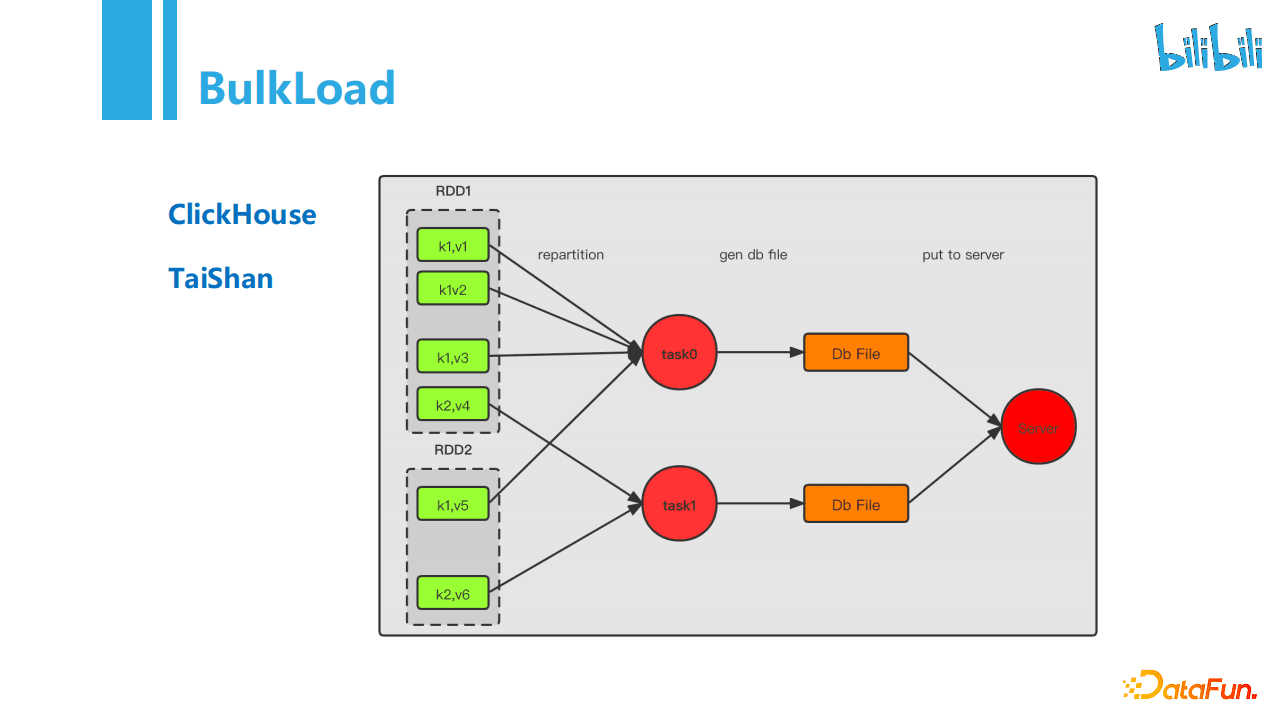
我们对jdbc协议写入TiDB和BulkLoad的方案分别做了压测,TiDB写入3、4亿条数据多实例写入的情况下,压测任务要运行两小时以上,TaiShan只需要十几分钟即可跑完压测,从结果来看Bulkload简直不要太好,但有个无法回避的问题是TiDB集群是多个业务同时写入的,分散到单个任务看起来写入时间长。
我们也在尝试绕过TiDB直接将数据写入TiKV,这个方案我们也在调研和实践中,感兴趣的小伙伴可以看下:
https://github.com/tidb-incubator/TiBigData
- 限速
在出仓场景,实际上还要考虑限流以及熔断,没有限速可能导致业务库有一些问题,毕竟服务器能力有限,写的太快将导致读有影响。最开始我们使用的方法是在代码内Sleep,简单实现就是假设数据写入很快,可以在一毫秒内完成,那么写入的耗时就是代码中sleep的时间,假如为例限速1w或5k,我们会通过sleep的时长就可以得出Spark需要的Executor数,达到间接的、不准确的限流。漏斗桶和令牌桶一个限制流入一个限制流出,我们用的不是很多。分布式的话我们小范围使用了Sentinel,但分布式限流如果触发熔断可能由于写入资源有限而写入一直处于熔断状态,导致写入时间长、数据任务破线。BBR算法是个很好的工具,有很多种实现,依赖的参数很多,甚至可以有对端的CPU及内存水位,不断尝试得到最佳写入量,在使用上可以很好的改善峰值问题。
04
监控自理
- 监控
在使用上,我们承接了几乎所有的离线出仓和入仓任务,作为数仓的零层和尾层,在入仓和出仓时需要及时感知可能存在的问题,一方面任务打优先级,方便分级处理,在运行时,基于历史指标预测当前任务的指标,当出现问题时及时告警接入检查。
AlterEgo中,我们在Spark的Application Job内定时上报写入速度和写入的数据量。Rider是常驻的可以运行多个Job,在Job中以Job为单位上报监控数据。AlterEgo和Rider的数据全部接入到消息队列里,消息最后被Aulick消费。Aulick内设计了多种指标监听器,用于任务的监控,包括运行时间、起止时间、速度、数据量、失败重试次数和TiDB和MySQL特有的插入/更新数据量。基于这些采集的指标数据,可以做到任务实例页,方便用户查看,另外汇总信息可以通过Grafana工具以及其他BI工具功能展示,异常告警交由Sensor做告警触发。
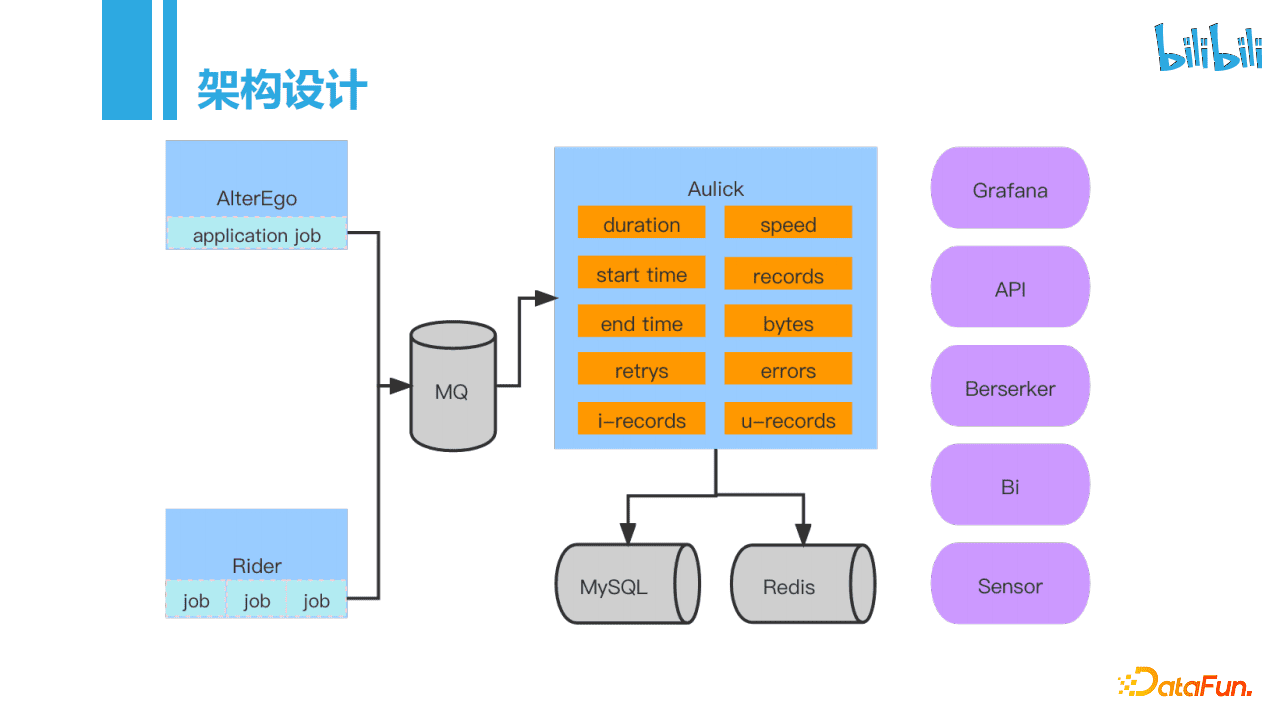
数据采集上,Rider方式实现有的内存Channel可以拿到同步的数据量等指标信息。AlterEgo方式由于是分布式,会有多个Executor进程同时上报,目前我们主要是通过自定义了累加器完成指标的上报,Executor端在使用累加器时实例化定时采集线程,由于各个Executor进程启动时间不同,所以在上报时的时间点是不准确的,在使用上我们把时间按照10秒一个窗口进行规整,如在0-10秒上报的数据会全部规整到0秒上进行汇总。
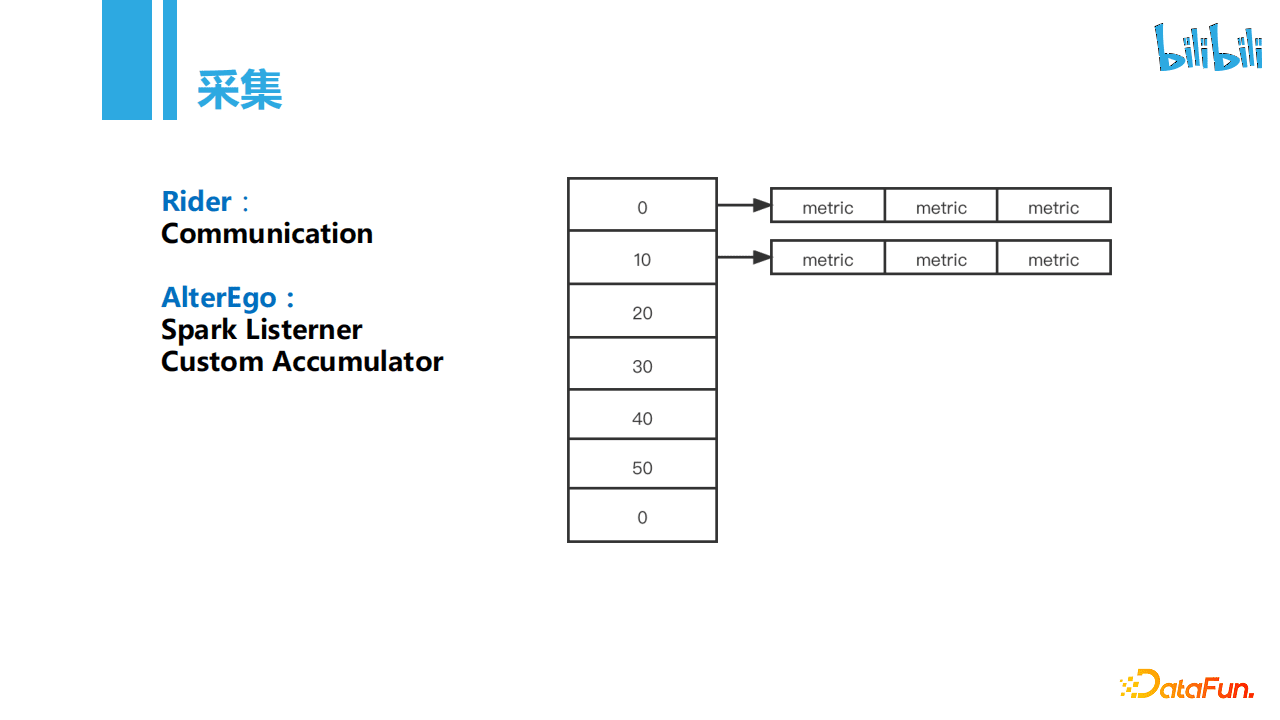
- 自理
在数据同步过程中,在数据维度上,需要发现异常读写速度、异常读写流量和异常走势,出现问题及时监控和报警,报警会有电话报警到对应负责人,对数据异常进行处理,防止由于上游数据导入任务异常导致下游数据产出问题。这类其实也可以通过DQC去做,但侧重点不同,这里更关注事中触发。
在时间维度上,基于任务历史预测,数据同步任务到时间未启动,或者任务已提交到Yarn但是由于资源不足没有启动,数据同步任务执行时间过长,也是需要及时处理。
在诊断方面,在任务失败后需要解析Error日志进行失败归因以及跟踪,方便用户自理,有一定量以后,还可以做任务的统计,以及资源优化。
05
精彩问答
Q1:3-4亿的BulkLoad压测性能提升是如何实现的?
A:BulkLoad是先写数据到本地磁盘,然后推到存储系统,由存储系统加载到内存,首先是Seatunnel分布式的,在执行时是分布式多进程生成各自的数据文件,最后再把数据文件推到存储系统, 实际的性能就看开多少并发度了,并且整个过程不会太消耗存储系统的CPU及IO压力,对读也是非常友好。
Q2:限速阶段如何感知下游压力?
A:感知下游压力,目前简单做法可以通过后端返回的RT时间或者失败来感知到存储端压力,目前熔断可以简单这么做,但这种不精细,无法处理好峰值问题,高级玩法可以参考BBR算法,依赖的参数很多,可以有存储段的CPU及内存水位,可以很好的改善峰值问题。
Q3:能否监控精细到Byte字节数?
A:大部分细节指标需要自己试下,B站这边是通过自定义d累加器实的现,在写入数据时记录数据字节数、条数等,简单点可以自己getBytes拿到,我们这边累加器会定时上报到消息队列,然后由Aulick消费数据后再进行相应地做报警动作。比如如果传输的字节量,字节速率存在异常,就可以及时的发下,找相应的同学协同排查问题。
Q4:DataX和Seatunnel是否可以互相替代?
A:工具平台在落地上,互相替换是很有必要的,出去性能差别外,在执行上也只是配置文件的区别。在集群规模很大后会收到很多环境问题、异常及各类问题影响,在工具使用上有个降级方案还是很有必要的。比如我们最近遇到了JDK的Bug,在kerberos认证时认证队列可能拉长,引起写入速度慢,事故当时,DataX在写数据时需要经过认证,无法及时定位问题,大部分集成任务运行出现速度慢、以及超时。为了防止事故再次出现,我们已经实现了大部分任务的可互相替换运行数据同步任务,实现任务的高可用。
今天的分享就到这里,谢谢大家。
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/quan/60849.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫