
A/B实验是最直观且科学的一种评估策略因果效应的手段,如果我们想数据赋能业务,A/B 实验是我们的基本工具。我们需要多个流量组提出多个策略想法,然后通过比较不同组的指标表现来选择最合适的方案。做ab实验需要两个条件为前提:同质性和无偏性。
实验中的不同组应该是同质的,这意味着它们都相同或极其相似以确保结果可比性,这通常通过平台工具随机分流来实现。实验也应该是公正的,核心指标只受实验策略本身的直接影响。只有控制了全部干扰因素,才有可能接近Treatment和Result之间的因果关系。


为什么优先做AB实验,而不采用前后对比等方式?
相比前后对比等方式,AB实验有以下优势:
同质 – 保证可比性
- 可以有效控制其他干扰因素。举例来说,如果我们采用前后对比方式来观察某项策略上线对核心指标的提升效果,我们无法有效控制前后两个时段的其他外部环境变量是一致的,例如其他策略影响或者周期性波动等。而AB实验是对比不同用户群体在同一时间的数据,可以有效控制这些外部的干扰因素。
- 可以避免选择性偏差。举例来说,如果抖音上线了一个新的功能,我们通过对比”使用过这个功能的用户”和”未使用过这个功能的用户”之间的数据,来论证使用这个功能可以提升用户的消费兴趣这个观点,则会犯了选择性偏差这一错误。原因是,会使用新功能的用户本身就是对抖音更感兴趣、使用更高频的用户,如果将会使用新功能的用户和未使用新功能的用户进行对比,衡量的其实是高频用户和低频用户之间的差异,而非新功能带来的策略效果。而AB实验由于会进行随机分流,对比的是同质的用户群体,因此可以避免选择性偏差带来的影响。
无偏 – 保证效果复现
- 通过实验设计构建上线后的真实情况以保证 A/B 观测到的指标收益可以真实地作用在全量上线后,避免单一实验观测到很好的效果,但上线后大盘指标未达预期等矛盾的现象;
- 即便有以上所有的措施对实验结果进行保证,我们仍然有可能观测到虚假的效果。因此,在分析实验数据时我们需要加上置信与否的概念,通过统计概率模型保证实验收益在上线后也有较高的可复现性;

AB实验的步骤是什么
如果希望执行一个严谨科学的AB实验,我们通常需要遵循以下六步曲:
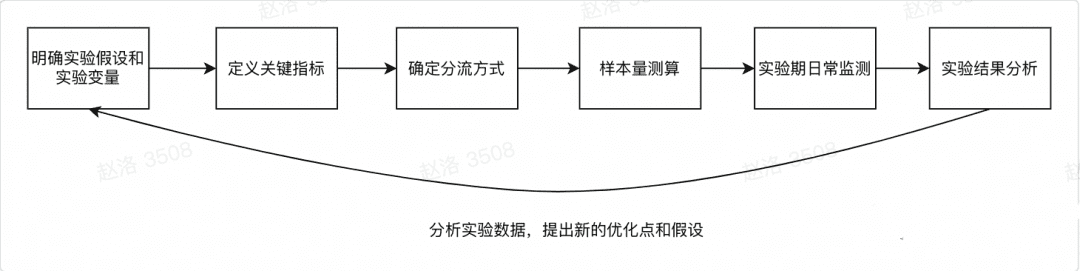
1、明确策略假设以及实验变量
AB实验的第一步就是明确实验需求产生的背景以及实验目标,即我们希望借助实验验证什么猜想假设,并且我们需要从用户角度以及数据角度去论证假设的可能性。
在有了一个明确且有数据支持的假设后,我们需要考虑我们的策略评估是否可以利用AB实验进行。尽管A/B实验是策略评估的常用方法之一,但其有着特定的适用场景,在以下几个场景,AB实验是无法应用或者成本过高的:
- 策略已经全量上线,需要后置的评估策略上线效果;
- 某些策略的渗透率过低,使用实验方法很难达到置信的样本量,所以不开实验;
- 策略本身不具备实行随机AB实验的条件,比如一部分用户无法使用某类功能而另一类用户则可以,这一情况会引发舆情问题;
- 进行AB实验成本较高,ROI较低的情况。比如从开发角度,维护多套代码成本过高。
确定可以采用AB实验对策略效果进行评估后,这时需要确定实验变量。通常一个好的实验变量需要满足以下几点:
- 实验变量需要根据假设创建。如果实验变量与假设无关,那么实验就失去了意义;
- 需要符合单一变量原则,这样我们才能通过对比发现因果性,并根据实验结果量化正向和负向的影响程度。举例来说,如果实验组的策略是A1+B1,对照组的策略是A2+B2,那么我们就无法得知实验组和对照组的指标差异是由于A策略的改动导致的,还是B策略的改动导致的。
2、定义关键指标
对一个业务来说,指标多种多样。哪些指标需要重点关注,哪些是仅仅关注,哪些可以不关注。这个指标的定义为了说明业务的什么情况?指标变化代表了什么?
从指标重要程度来看,指标可以分为主要指标、次要指标和护栏指标三类:
- 主要指标:需要优化的目标指标,决定这个实验的最终发展方向。这类指标不需要多;
- 次要指标:次要指标可以从多个角度反映实验策略的效果,辅助进行全量决策;
- 护栏指标:用于辅助保障 A/B 测试的质量,衡量 A/B 测试是否符合业务上的长期目标,不会因为优化短期指标而打乱长期目标,防止发生“捡芝麻掉西瓜”的情况;
从指标类型来看,可以分为平均、计数、求和、比例、留存等等;
3、确定实验分流方式
分流指的是我们直接将整体用户切割为几块,用户只能在一个实验中。AB实验的核心思想在于寻找两组同质且与大盘类似的小流量对象群体,通过观察不同策略在这两组同质对象群体上的表现,来预估策略应用到全量后的效果。因此,如何合理的分流找到这样的对象群体,则成为了影响AB实验评估准确性的关键因素。
这里需要注意分流对象与随机单元。
- 分流对象是需要根据核心指标来确定的根据什么来进行分流,例如在短视频场景,我们的策略是提升消费指标则分流对象就是用户,而如果我们的策略是提升创作者活跃度则分流对象就是创作者;
- 随机单元就是AB实验要达到随机的最小单元。例如一个网站中,最小分流单元可能是页面级别、访问/会话级别,或者是用户级别;
我们需要保证实验的分流是均匀的,一般实践中,主要采取AA空跑的方式来验证:
- AA空跑:针对选定的实验组和对照组,在上实验策略前先空跑一段时间。如果空跑期的样本量和各项指标均无显著差异,则认为实验分流是均匀的。这种方式的缺点是需要空跑期,会延长实验所需时间。(审核员分流也可以前置在随机分流时观测两组历史数据的差异,差异大建议重新分流)
- 回溯:在进行实验后,将实验期的用户选出来,观察这些用户在实验前的表现。如果实验期用户在实验前的表现无显著差异,则认为分流是均匀的。
4、样本量测算
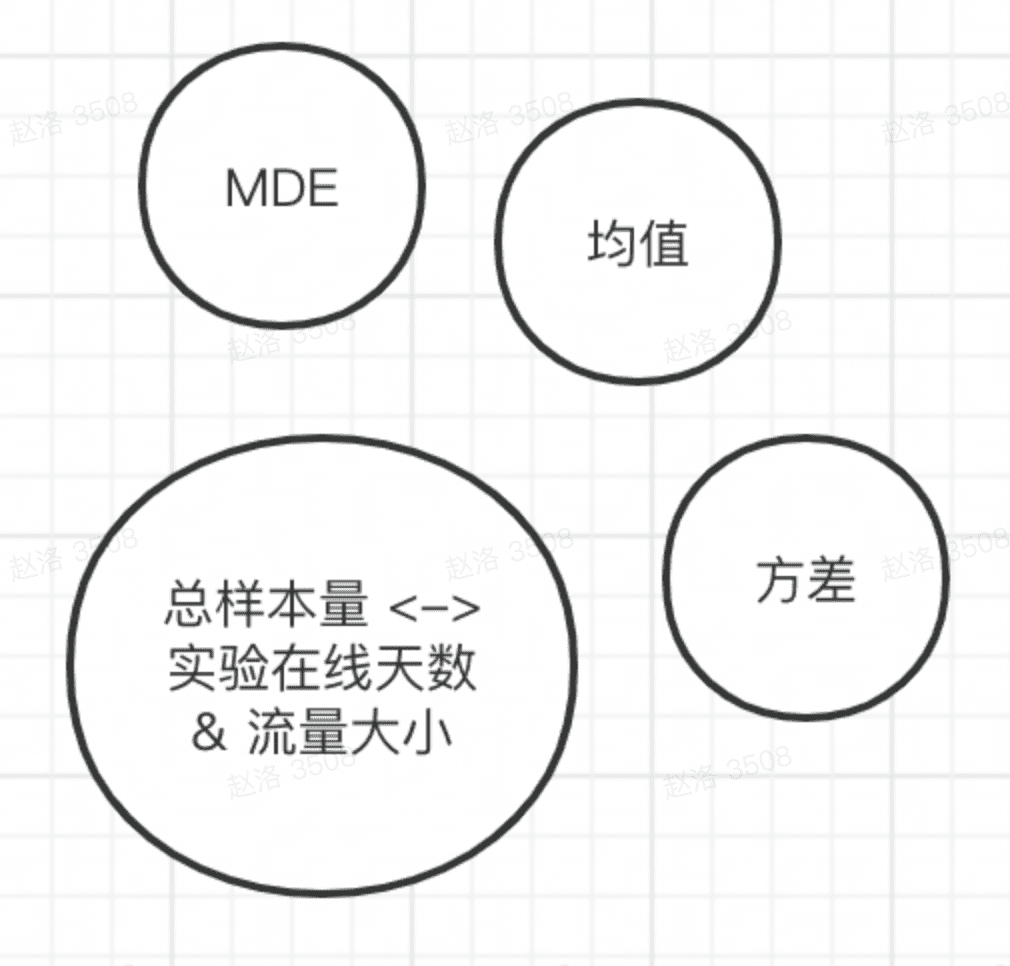
对于AB实验来说,在实验的第Ⅰ/Ⅱ类错误率确定的前提下,实验能检测到的敏感度会与实验样本量呈现负相关关系。也就是说,实验希望能检测到的指标精度越高,所需要的样本量就越大,这样可以使实验的敏感度大于我们预期的策略效果提升(MDE)。
因此,针对我们希望检测到的预估效果MDE(通常由离线测算所得,如5%/10%等),我们需要计算实验所需要的最小样本量。在给定错误容错率下,最小样本量由MDE、均值、方差共同决定。此处需要注意的是不同的指标类型的方差计算方式是不同的,在实操中如果分流单元和分析单元不一致需要特殊处理。
5、进入实验期
在进入实验期后,需要对实验数据进行日常监测,日常监测主要观察以下几方面:
- 样本量。在实验的过程中,应当日常观测实验组和对照组的样本量是否均匀。如果在进入实验期后,实验组相比对照组的样本量出现显著差异,应当立即排查样本量不平的原因(实验策略导致分流不均?实验策略埋点上报有问题?…)
- 各项实验指标。如果在实验的过程中,实验组和对照组的指标出现不符合预期的差距,也应当立即排查该现象出现的原因。
- 核心护栏指标。如果实验策略对实验组的核心护栏指标产生严重的负向影响,如商业化广告收入严重下降,也应立即同步各方,决定是否停止实验。
6、实验结果分析
在实验周期结束后,需要根据实验数据进行分析。分析的框架可以根据实验指标,衡量对主要指标、次要指标、护栏指标分别的影响,从而给出是否全量的建议。在分析实验数据时,通常会有以下问题:
实验指标不显著怎么办?
可以看一下核心指标的走势,如果有单调递增的趋势,可以适当延长实验时间再看一下效果,大样本是王道。其次判断统计功效问题,如果在进行了样本量计算后,实验指标依然不显著,则一方面需要通过观察实验指标的相对/绝对差值考虑是否实验策略真的没有显著影响,另一方面可以通过CUPED等方法减小指标方差,或者更换监测指标剔除无渗透用户以提高指标检测精度。
是否可以通过实验数据,找到对实验策略敏感的用户群体?
找敏感用户群体可以通过维度拆解的方式,观察实验策略对不同用户群体的影响差异;也可以通过causal tree/uplift model的方式,从模型角度计算单个用户群体/单个用户的CATE,从而对实验效果的异质性进行探究。
关注的多个实验指标有正有负,如何判断是否可推全?
首先,确认哪边的指标是本实验更重要的指标,同时关注护栏指标和北极星指标的情况(若护栏指标和北极星指标显著负向,拒绝推全)。其次,判断正负指标是否存在相关性或者是否存在兑换关系,综合盘整体收益是如何。
如果实验效果不好,没有推全,是否说明这个实验没有任何价值?
事实上在各大公司中,大部分的AB实验结果都是失败的。如果某个实验没有推全,我们依然可以通过实验数据,去探寻本次实验失败的原因,从而发现是否有新的可能的改进点。根据新的改进点继续进行实验,最终进行策略的快速迭代。
作者| 赵小洛 数据分析师
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/quan/78119.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫