

文|光锥智能 周文斌
2018年以后,Transformer及其衍生变种的大模型开始逐渐替代卷积神经网络,席卷自然语言处理、图像识别、语音识别等多个AI领域。
2019年,也是在AI DAY上,时任特斯拉AI总负责人安德鲁·卡帕西(Andrej Karpathy)提出,特斯拉自动驾驶要像人一样开车,要在2021年取消激光雷达,并引入“大模型”对特斯拉的自动驾驶系统进行训练。
之后,特斯拉代表的纯视觉自动驾驶方案在行业里独领风骚,而在安德鲁·卡帕西的推动下,Transformer大模型也开始成为解决自动驾驶难题的主流方案。
大模型的特点是结构简洁、可无限堆叠基本单元得到巨大参数量,只要拥有足够规模的数据,其可提升的潜力上限就极高。但问题在于,要驱动大数据,训练大模型,就必须要有超大算力的支持。所以,特斯拉在2019年同时发布的还有Dojo超级计算系统。
在国内,毫末率先引入了Transformer的技术,之后也是最早建立自己超算中心的自动驾驶企业。就像在大家普遍选择高精地图的时候,毫末选择了重感知方案一样,虽然当时不是主流,但后来却逐渐成为行业共识,如今超算中心也大有成为自动驾驶企业标配的趋势。除了特斯拉之外,2022年蔚来、小鹏、大陆等多家企业都开始建立自己的超算中心。
走与大多数人不一样的路,这不仅是毫末对自动驾驶的深度理解和洞察,也是毫末自身战略勇气和战略定力的表现。而历史的经验也在一次次说明,毫末的判断每一次都踩中了自动驾驶发展的脉搏。
1月5日,毫末再次举办AI DAY,这一次,毫末在自动驾驶数据智能体系MANA(雪湖)的基础上,又推出了新的智算中心MANA OASIS(雪湖·绿洲)。
毫末智行董事长张凯在AI DAY上提到:“随着自动驾驶企业向3.0时代迈进,“大模型+大数据”的数据驱动模式,成为自动驾驶技术进化的关键,而驱动大模型和海量数据训练的超算中心将成为自动驾驶企业的入门配置。”

毫末智行董事长张凯
当拼完大模型,自动驾驶又开始拼大算力,这不仅让自动驾驶公司在技术难度上提升了一个台阶,也在“钞能力”上又提高了要求。
不过,当一切准备就绪,自动驾驶在城市落地的可行性也提升了一大步。
01 生长于雪湖的智算中心
对于自动驾驶来说,算力的重要性不言而喻。
特别是当越来越多搭载自动驾驶辅助系统的车辆行驶在城市道路上之后,复杂的道路环境、指数级增长的车辆都让自动驾驶的数据量爆发式增长。
而数据量增加,原来依靠CNN卷积神经网络训练自动驾驶的方式效率就有些低了。所以2018年之后,在特斯拉的带动下,能够提高训练效率的Transformer训练模型开始流行。
但问题也随之而来——要驱动这样的大数据、大模型就必须要有超强算力作为支撑。
“超算中心将会成为自动驾驶公司的入门配置”,张凯在此次AI DAY上表示,这将是自动驾驶2023年的一大趋势。
事实上,国内外头部的自动驾驶相关企业都在建设自己的超算中心,比如2022年6月英伟达披露,蔚来正在利用它们的芯片构建数据中心,以支持深度学习模型的迭代和自动驾驶算法的训练。8月,小鹏也宣布和阿里云在乌兰察布建成了自动驾驶智算中心“扶摇”。
在国外,除了特斯拉之外,全球头部的汽车行业Tier 1大陆集团也在构建自己的高算力集群,用于加速开发自动驾驶解决方案,主要应用场景包括深度学习和仿真测试。
成立仅仅三年,毫末作为一家创业公司,其在关键领域的布局丝毫不逊于这些巨头。2021年,毫末在年底的AI DAY上发布了自己的自动驾驶数据智能体系MANA,中文名字叫雪湖。
这是一个源自《三体》的名字,罗辑在这里悟出了“黑暗森林法则”,成为他持有的一把利剑为人类带来66年的和平。而这次毫末在AI DAY发布的智算中心绿洲(MANA OASIS),也从雪湖当中孕育而出。

火山引擎总裁谭待(左),毫末智行CEO顾维灏(右)
从数据上看,MANA OASIS绿洲具有每秒67亿亿次的浮点运算能力,具有每秒2T的存储带宽,和每秒800G的通信带宽。

首先是浮点运算,AI大模型的训练依靠的不再是传统CPU的逻辑推理能力,而是以AI加速器为主的浮点运算能力。
其次是存储带宽,自动驾驶的训练任务文件通常比较复杂,比如毫末用来训练的自动驾驶数据被称为Clip,它是包含图像、视频,以及毫米波雷达、激光雷达等多种信号的小文件。
无数这样的小文件构成自动驾驶训练的数据,自动驾驶在训练过程中需要随机调用这些数据,为了降低延迟,提高数据的访问和传输效率,就需要更大的存储带宽作为支撑。
为此,毫末还专门组建了一套以场景库标签为索引的文件管理系统。有了这套系统,在2TB/s存储带宽支持下,MANA OASIS针对百亿规模的小文件随机读取延时小于500微秒。
最后则是800G的通信带宽,这是因为自动驾驶所需要的模型需要更好的并行计算框架才能把硬件资源都利用起来。再加上现在人工智能发展很快,新的算法层出不穷,需要尽快引入新的技术和模型,这些都需要高通信带宽的支持。
在毫末看来,智算中心或许和罗辑的面壁计划一样,可以成为解决当前自动驾驶瓶颈的一把利剑。

图源:《三体》动画
但到这里毫末其实还不满足,他们想要在智算中心上做一些更极致的优化。也是这个原因,这次毫末的智算中心的合作伙伴选择了火山引擎。
作为字节旗下的云服务平台,火山引擎在支持抖音的过程中积累了对视频、视觉丰富的理解和经验。毫末CEO顾维灏也特地提到,火山引擎在这一方面为MANA OASIS提供了很大助力。
例如在高性能算子库方面,火山引擎提供超过500个高性能算子,基本让当前神经网络所能用到的算子都有了高性能版本,这让MANA OASIS可以支持包括Transformer在内的超过200组网络结构。
而在大模型的训练框架上,MANA OASIS能够实现单机8卡就能训练百亿参数大模型的效果,实现跨机共享expert(专家)的方法,完成千亿参数规模大模型的训练,训练成本降低到百卡周级别;同时,MANA OASIS还能同时处理图片、点云、结构化文本等多种模态的信息,既保证了模型的稀疏性、又提升了计算效率。
整体上,字节通过部署Lego高性能算子库、ByteCCL通信优化能力、大模型训练框架等软硬一体的方式,把算力优化到极致。张凯透露,“MANA OASIS的应用让毫末的自动驾驶训练效率提升了100倍。”
在智算中心的加持下,张凯认为,随着自动驾驶AI大模型在云端的深入应用,行泊一体的持续迭代升级和效率提升。车端智能驾驶系统的综合成本将大幅度实质性降低。以重感知技术为主,主要依托视觉方案的智驾系统将可以在中低算力的车端平台上部署。
“2023年,智能驾驶的下半场进入加速期,高阶辅助驾驶产品的商业应用将迎来大规模落地。”张凯表示:“到2025年中国高阶辅助驾驶搭载率将达到70%。智能驾驶功能成为必选因素,智能驾驶已迎来商业化的加速发展。”
02 用大模型“降本”“增效”
有了智算中心,自动驾驶公司就能更加高效地训练大模型。
在这次AI DAY上,毫末发布了五个最新的大模型,分别是视频自监督大模型、3D重建大模型、多模态互监督大模型、动态环境大模型和人驾自监督认知大模型。

首先是视频监督大模型,它解决的主要是数据化标注的问题。
前面提到,为了降低成本,提高训练效果,毫末将原来的离散帧,也就是单帧标注数据变成了连续的Clip形式。但问题在于,当新技术应用之后,过去积累的数量庞大的单帧数据就无法再使用了。
“真实的视频每秒至少10帧以上,原来的离散帧一秒钟只会标注一帧,中间还有许多空隙是没有标注的。”毫末技术副总裁艾锐这样解释单帧和Clip的差别。
所以,为了把之前的数据用起来,毫末就需要把单帧数据的空隙补上,标注成Clip的形式。只是这个过程如果用人工标注,成本会非常高,所以才有了视频监督大模型,这是一套数据自动标注的方法。

图:视频自监督大模型演示
“目前我们基本上达到了百分之百的自动化,只需要非常少量的,大概2%的人工做一遍抽检就可以了,整个成本节省是非常显著的。”提到视频监督大模型的效果,艾锐如此说道。
在国外,特斯拉其实也做着类似的事情。去年6月份,特斯拉开启首轮裁员,首先被裁的就是数据标注的员工,一个原因就在于自动标注系统的应用。
然后是3D重建大模型,解决的是低成本数据获取和补充的问题。
自动驾驶发展到现在,各大企业已经累计了几千万,甚至上亿公里的路测数据。这些数据可能解决了自动驾驶99%的corner case,但是剩下的1%因为不太容易遇见,所以需要花费巨大的成本或者时间。
比如同一个环境,春夏秋冬不同的时间,同一辆车的通行情况也会有所不同。如果按正常的数据收集,这个过程就很长。
而3D重建大模型则可以通过几张照片,或者某个场景的一段视频就把这个场景主要的静态结构以3D的形式重新建立起来。这其中的逻辑和之前流行一时的元宇宙虚拟人捏脸有些相似,即用户只需要上传一张照片,平台就能够生成一个3D人物模型,让你看到不同角度的样子。
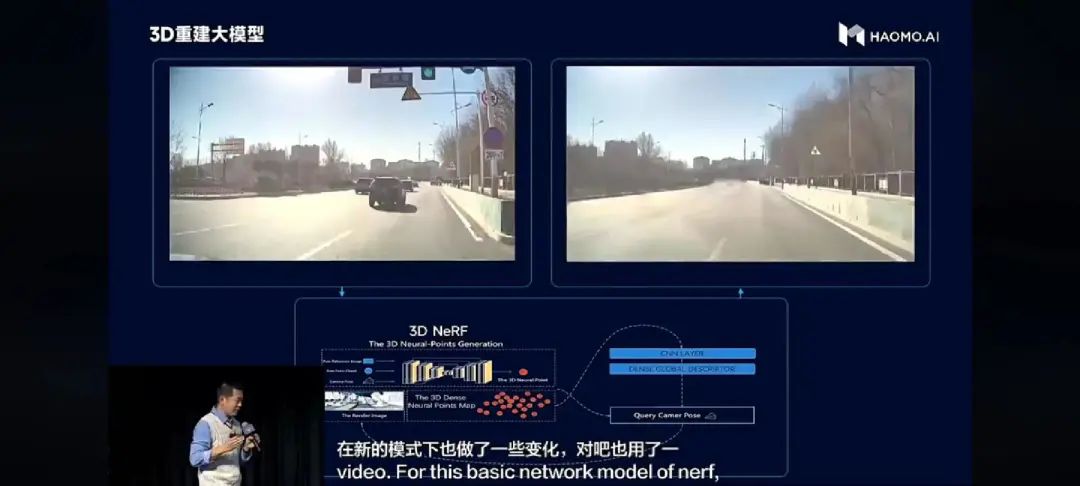
图:左右两个视频,你能分清哪个是3D重建的吗?
有了这样的技术,自动驾驶训练就可以通过算法得到一些极限路况下的数据,或者补充一些之前缺失的数据。比如我们拥有某个路段春天的行驶数据,通过算法就可以直接获得冬天的数据。
“我们现在的很多算法研发在做场景数据补充的时候都会使用这个方法,基本上能让我们感知在这些困难场景下的错误率有明显的下降。”艾锐提到。
而这两个模型总结下来,解决的都是数据分布、处理效率和成本的问题,这也是智算中心核心要解决的问题。
再然后是多模态互监督大模型,它解决的问题是如何让车辆识别并通过复杂路况。
在自动驾驶行驶过程中,毫末发现对于已知物体,自动驾驶的识别都没有问题,但如果道路上出现一些奇怪的、无法描述的东西自动驾驶就还存在缺陷。
解决这个问题,最简单粗暴的方法,是将所有遇到的物体都做上标注,但成本也很高。而且更大的问题在于,各种奇怪的物体其实是不可能完全标注的。
所以毫末选择了另外一种方法,就是不去纠结这个东西具体是什么,我们只需要知道它有多高、多宽、是否会对行驶产生影响。
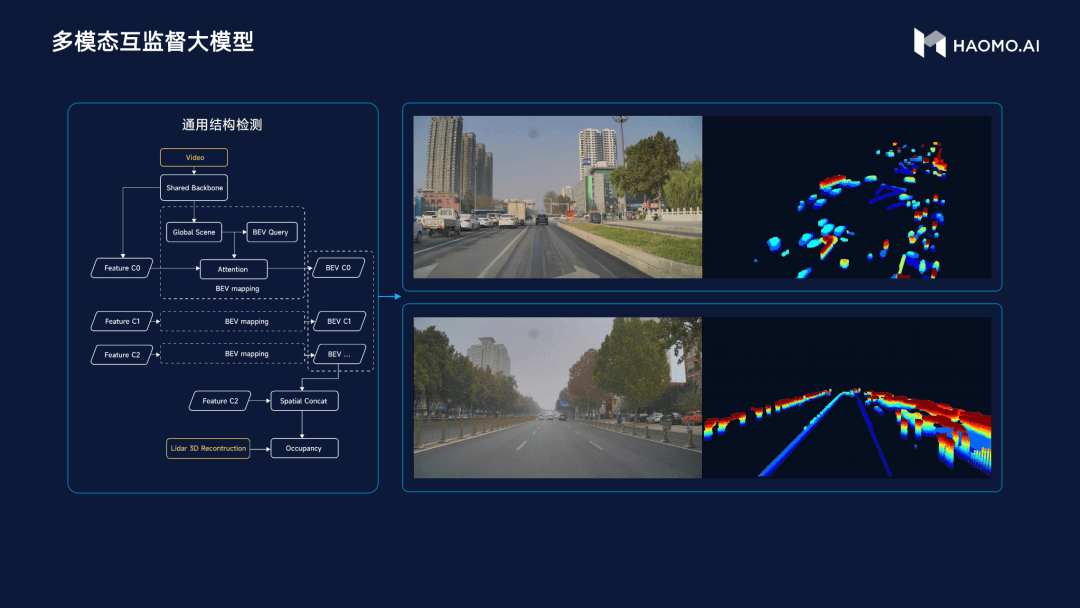
在去年的AI Day上,特斯拉也发布过一个名叫占用网络(Occupancy Network)的算法。这个算法不去纠结障碍物具体的语义,而是以3D几何信息的方式对物体进行显示,其感知结果就直接可以用来指导自动驾驶路径规划。
而毫末的多模态监督大模型,则是通过让视觉、激光雷达、毫米波等不同传感器相互监督,再采用激光雷达点云对视觉进行验证的方法,达到与占用网络相似的结果。
之后的动态环境大模型,则主要是为了让自动驾驶车辆摆脱高精地图的限制。
其原理在于,让自动驾驶把注意力机制从常规的空间注意力转到拓扑注意力,用一个自回归的编码器来实现,让系统能够像人一样,根据现在的情况预测之后的道路情况。
艾锐称,“这种方法我们在北京和保定的很多路口都做了尝试,对于大部分的路型,使用现在的方法都没有问题,可以达到95%的准确率。”
最后的人驾自监督认知大模型,则是为了让自动驾驶开车更像人。
在过往的自动驾驶训练中,企业通过数据驱动的方式解决驾驶决策的问题。各种数据一股脑地喂给AI,AI并不会分辨其中的好与坏,只是单纯的将各种数据综合,因此它往往会得到一个平均数,而无法提升到一个好司机的水平。
所以人驾自监督认知大模型的目的,就是为了让自动驾驶系统区分“什么是好的驾驶方法”。
在传统的解决方案中,最直接的办法就是采集许多司机的行为,让模型学习他们的开车行为。或者用人工进行标注,告诉AI什么是好的,什么是不好的。但这样成本又会很高,而且最重要的是,对于自动驾驶来说,这是一种比较黑盒的方法,即自动驾驶只是在单纯的模仿,是知其然而不知其所以然。
人驾自监督认知大模型在做的,是去对比学习那些被司机接管的数据,毕竟接管往往意味着司机对AI的驾驶不满意,而学习接管后的驾驶方式,则能够帮助AI在驾驶能力上越来越向老司机靠近。
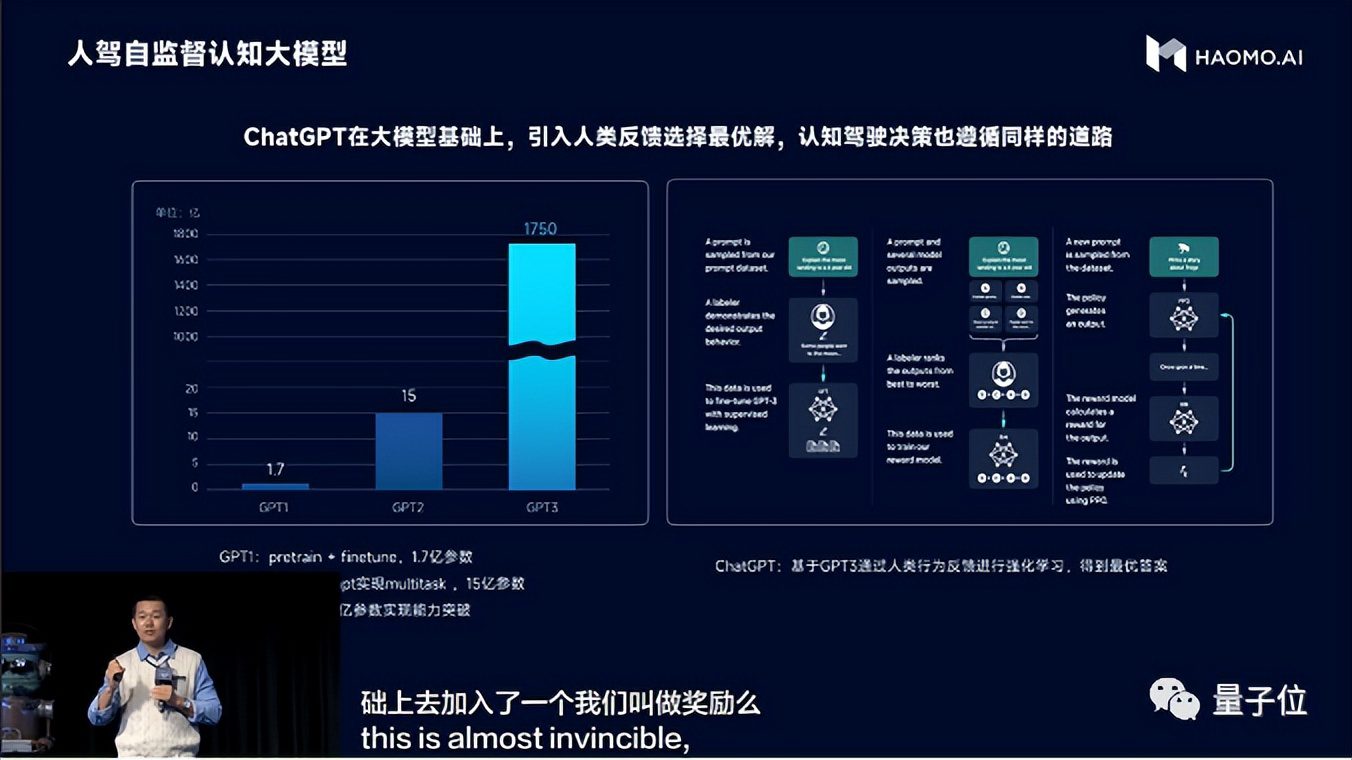
艾锐提到,毫末之所以会选择这种方案,也是因为受到最近很火的ChatGPT的启发。
“在GPT-3之前,谷歌OpenMind已经做了好几年,但并没有引起特别大的反响,这次ChatGPT突然火了,一个很重要的原因是把一个人类行为的反馈加进来,有一个专门用人类行为进行反馈的强化学习。”艾锐提到:“通过人类的这些反馈行为,AI可以分辨它应该在什么时候给出什么质量的回答,然后自动把一些低质量的回答去掉,所以大家才觉得这个机器人比较像个正常人。”
03 辅助驾驶“城市争夺战”
从智算中心到五大模型,毫末总是会用更低的成本,更高的效率获得、处理自动驾驶数据。
比如视频监督大模型和3D重建大模型都是为了降低数据获取成本,提高数据获取的效率。而多模态监督大模型是为了减少数据处理中人工参与的部分,以此来降低成本。
能做到这一点,是因为毫末对于自动驾驶在场景落地的终极思考足够深入。
除了特斯拉之外,2022年4月,毫末发布了中国首个大规模量产的城市辅助驾驶产品;9月初,小鹏城市辅助驾驶(NGP)开始在广州推送,之后不久搭载华为自动驾驶的极狐汽车在深圳城区智能导航辅助(NCA)。而除了这些已经发布、落地的,蔚来、理想、阿维塔,新势力有一家算一家,都给城市辅助驾驶定下了时间。
可以说,2022年以来,城市辅助驾驶成为各大车企和自动驾驶企业争夺最激烈的焦点。
但截至目前,城市辅助驾驶铺开的速度都远没有想象中的迅速。如今,支持小鹏NGP的城市仍然只有广州一个,华为NAC也仅限于上海和深圳。
而发布快,落地慢的一个核心问题就在于,面对复杂的城市道路环境,城市辅助驾驶还有太多问题没有解决。
比如高精地图的问题,华为、小鹏的城市辅助驾驶之所以被限制在广州、深圳和上海,很大一个原因在于只有这几个城市的地图通过了审核。

图:行驶中的毫末城市辅助驾驶NOH
为了避免这种限制,毫末首先提出了“重感知”的自动驾驶方案。我们会发现,在这次五大模型中的动态环境大模型就是为了让自动驾驶车辆尽量地减少、甚至摆脱对地图的依赖。
当然,地图的审核只是一方面,更多的问题还在于面对快速发展的中国城市,高精地图的数据采集、鲜度保持都面需要高昂的成本和挑战。
“我们发现,北京每100公里道路的拓扑结构平均半年会变化5.06次,为了更好地解决复杂路口的问题,我们对地图的依赖还要进一步减弱。”艾锐说。
除此之外,多模态互监督大模型则是为了增加自动驾驶在城市道路上的通过性,让自动驾驶能够适应更多的路况。
目前,城市辅助驾驶仍然属于L2的状态,而L2与L3、L4最大的区别在于,系统能否解决规定之外的场景,并保证安全。L2无法识别到运营规则之外的场景,L3能够识别到,并保证能及时移交权限给人类驾驶员。L4则需要自动驾驶不仅能够识别到运营规则之外的场景,而且大概率能够安全通过,即使不能通过,也能安全停下来。
图森未来首席科学家王乃岩这样区别L2、L3和L4:“L2系统不需要处理失效,L3系统只需要检测失效,L4系统则要妥善处理失效。”
本质上,毫末和特斯拉的方案,都是为了增加自动驾驶的通过性,并保障安全,在逐步从L2向L3,甚至L4去做过度和准备。
而这个过程,其实是依赖于重感知选择。可以说,城市导航辅助驾驶进入重感知阶段,大规模量产交付的大幕才开始拉开。
而最后的人驾自监督认知大模型,解决其实是一个体验的问题。
只有让自动驾驶和人类的驾驶更像,才能给到用户更好的乘车体验,用户也更愿意买单。
这里面其实存在一个自动驾驶落地的悖论,即车企和自动驾驶企业期望软件和车辆尽快量产落地,好收回数据来持续迭代算法。但对于用户来说,面对一个并不成熟,甚至只能限制使用的产品,额外溢价去进行购买的意愿其实并不会很高。
所以,人驾自监督认知大模型本质上是基于真实用户的数据驱动,让产品的体验更好,让消费者更愿意买单,从而推动整个自动驾驶系统的训练进入良性循环。
而其背后,也预示着未来自动驾驶系统的比拼,将由具备功能转变为提升通勤效率,系统迭代更加精准,迭代速度进一步加快转移。
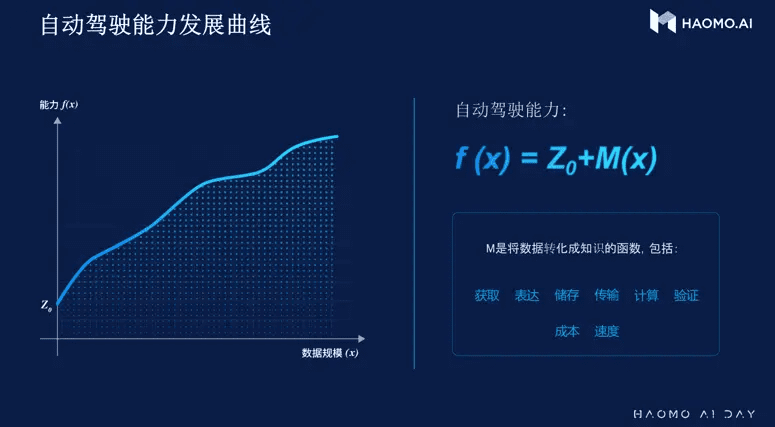
顾维灏曾总结过一个自动驾驶能力发展曲线:f(x)=Z0+M(x)。
其中F代表产品力,Z0代表第一代产品的能力,M是一个把数据转化为知识的函数,包括:数据获取、数据表达、数据存储、数据传输、数据计算,数据验证。
无论是智算中心还是大模型,本质上都是在以更低的成本获得更多M(x)的能力。而随着一系列大模型的应用,算法性能开始提升,训练成本随之降低,未来自动驾驶可能搭载的车型价格必将进一步下降,能够覆盖的城市也将进一步拓宽,让更多人能够享受到自动驾驶的体验。
截至2022年年底,毫末HPilot(城市辅助驾驶)已在包括魏牌、坦克、欧拉等近20款车型上搭载,用户辅助驾驶行驶里程突破2500万公里。2023年,毫末更是计划陆续落地到国内100个城市。
可以预见,普通人能够用上的自动驾驶将会离我们越来越近。

从左至右:毫末智行CIO甄龙豹,毫末智行CEO顾维灏,毫末智行董事长张凯,毫末智行COO侯军
本文来自投稿,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/quan/89201.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 