


文/半月
编辑/周雄飞
ChatGPT火爆来袭,各路创业者们正赶着上车。
有着大模型储备的大厂,纷纷下场布局。上月底,在360科技2023年数字安全与发展高峰论坛上,其官方正式发布大语言模型360 AI。
而在更早以前,作为国内率先对人工智能领域布局的百度,也推出了旗下多模态大模型应用——文心一言,据百度CEO李彦宏介绍,该模型具备文学创作、商业文案创作、数理推算、中文理解、多模态生成五个使用场景的综合能力。
与此同时,阿里,美团等大厂的一大批高管,看准机会相继宣布创业,拿出大部分身家,只为做出中国版的ChatGPT。
先是在今年2月,原美团联合创始人王慧文在社交媒体上宣布出资5000万美元,设立北京光年之外科技有限公司,并表示75%的股份用于邀请顶级研发人才,打造中国OpenAI。另据最新消息,光年之外近期已启动新一轮融资。
次月,阿里前技术副总裁贾扬清也透露了他下一步的创业打算,据他介绍其目标是AI大模型底层技术相关,目前融资已基本到位。
除此之外,还有字节跳动旗下今日头条前用户产品负责人张前川、快手前国际化技术负责人王美宏、IDEA研究院理事长沈向洋、循环智能联合创始人杨植麟等高管,试图在ChatGPT风口中,寻求“再就业”的机会。
一大批创业者们前赴后继,“ChatGPT们”正加速狂飙,这背后少不了多个行业“保驾护航”。
要建立ChatGPT这样的大模型应用,少不了算法、算力和数据三大行业的支持,简单说,应用要高效运行起来,就需要强大算力的支持,而要让应用背后的算法更为聪明,则需要源源不断地向其“投喂”高质量数据。

由此可见,算法大模型想要实现升级和迭代,最为关键的就是需要大量数据的训练,而要保证这些数据的质量,就需要对数据进行清洗、标注、质检等多个步骤,要完成这一目标,少不了标贝科技、海天瑞声为代表的一批数据标注提供商的助力。
现阶段,数据标注厂商们已耕耘多年,且各有“两把刷子”。
标贝科技,作为多年扎根在数据标注领域的企业,专注于智能语音交互与AI数据服务,并通过精细化的定制服务打出自己在行业中的优势。截止目前,标贝科技服务项目累计超过1000项。
除此之外,海天瑞声、Scale.AI、Appen等玩家,同样是专注于数据标注的厂商,具备全套的产品与服务,在语音、计算机视觉、自然语言理解等领域皆有布局。
随着GPT-4等大模型的进一步发展,对于训练数据质量的要求必将更为苛刻,摆在数据标注厂商们面前的,是无限机会与挑战。
1、ChatGPT创业潮来了,高质量数据成“刚需”
ChatGPT正为交互领域带来“划时代”的改变。
随着1946年,世界第一台现代计算机EDVAC诞生,交互1.0时代正式开启。人们用打孔纸,通过输入0、1二进制的机器语言与计算机进行交互,直到上世纪70年代,人机交互迎来一次新的蜕变。
当时,随着首台个人计算机的问世,相比于此前用打孔交互不同,人们可以通过鼠标、键盘向计算机传达任务:即通过点击电脑图标、以及用键盘输入指令向计算机下达命令,从而让计算机做出反馈,自此,计算机开始“飞入更多寻常百姓家”。
这之后,虽然出现了Windows等多款操作系统,并且这些操作系统自身也持续不断地进行着更新,但从本质将人机交互依然是通过编码和解码后的机器语言来进行。
直到2022年,OpenAI带着ChatGPT的到来,让交互领域再度迎来“iPhone”时刻:人们能够直接用自然语言流畅地与计算机进行交流,并且计算机能够直接理解自然语言并与用户进行反馈和对话。
之所以说是ChatGPT开启了新的交互时代,是因为相较于以往的对话模型,ChatGPT有着质的飞跃。
经过连线Insight体验,ChatGPT能够从中国诗词歌赋聊到西方人生哲学,并在最后进行总结;而以往的对话模型只能表达一首简短的中文诗。也就是说ChatGPT能够实现多轮及结合上下文的不间断聊天,且能记住以往指令,同时用各国语言沟通无障碍。
而ChatGPT背后的大模型还在不断迭代:从2022年底的GPT-3.5到2023年初的GPT-4,性能又得到了全方位的提升。
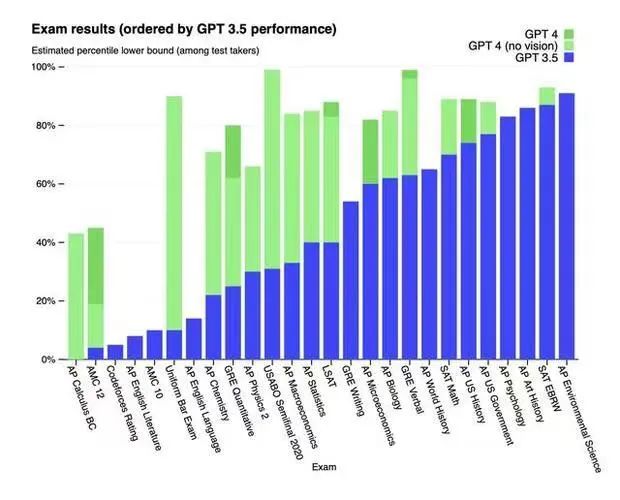
GPT-4较于GPT-3.5的性能提升,图源OpenAI
当看到ChatGPT在人机交互上跨时代的表现后,很快,各行各业都向ChatGPT们发出邀约。
最为声势浩大的莫过于微软,在2020年,微软下了血本投资OpenAI 10亿美元,在2023年,微软迎来摘果子时刻:微软正在将自家生态逐步和GPT进行结合,从而形成全新的AI生态。
上月17日,微软发布融合GPT-4能力的Microsoft 365 Copilot。据了解,Copilot将会被内置到Word、Excel、PowerPoint、Outlook、Teams等应用之中。
简单来说,用户只需要对Office下一个编辑的指令,Word、PPT、Excel等就会自动“干活”。例如,在制作PPT时,Copilot可以基于用户的输入内容自动生成PPT页面,并提供字体、颜色、背景等设计风格建议,并且Copilot还可以自动检测演示文稿中的错误和重复内容。
就当微软在ChatGPT领域落子的同时,国内科技公司百度也率先站出来,发布了它的类ChatGPT产品——文心一言。据连线Insight测试,文心一言同样具备ChatGPT的众多能力,比如对于提问做出及时、准确的回应,以及可以结合上下文进行不间断的交流和应答。
看到文心一言的能力后,国内各个行业的企业们纷纷响应,争相成为该产品的合作伙伴。比如汽车行业的集度、长城,媒体行业的澎湃新闻、大众日报,家电行业的海信、美的等企业,纷纷接入百度文心一言。截止目前,已有650+公司,等待着百度文心一言的支持。
OpenAI、微软和百度引领之后,有更多的科技公司参与到类ChatGPT大模型的争夺中来。
上月底,在360科技2023年数字安全与发展高峰论坛上,其官方正式发布其大语言模型360 AI。目前360的构想是,在To C端,基于搜索场景推出人工智能个人助理类产品;在To SME端,将基于生成式大模型推出SaaS化垂直应用,如结合生成式AI的“企业即时通讯工具-推推”等。
除此之外,网易、科大讯飞等科技公司的产品也在孵化之中:2月8日,网易有道对外表示,该公司未来或将推出ChatGPT同源技术产品,应用场景围绕在线教育;2月9日,科大讯飞表示,其Al学习机将成为公司类ChatGPT技术率先落地的产品,并于今年5月发布。
随着越来越多科技大厂布局类ChatGPT大模型,行业内外对于GPT-4等大模型也提出越来越多样的要求:既要其懂得驾驶语言,赋能智能座舱甚至是自动驾驶;又要求其博览群书,并给出群书中的关键论点;还要会塑造虚拟人物,懂得人类的喜怒哀乐等等。
这也意味着,行业内外对于大模型必备的“三件套”(算力、算法、数据),正提出更高的要求。
对于大模型“世界”来说,算法是“生产关系”,是处理数据信息的规则与方式;算力是“生产力”,能够提高数据处理、算法训练的速度与规模;而数据是“生产资料”,高质量的数据是驱动算法持续迭代的养分。
基于这一重要性,目前对于算力的持续投注已是行业共识,政府也开始出手。
先是部分地方政府开放算力资源促进地方产业发展。今年1月,成都出台《成都市围绕超算智算加快算力产业发展的政策措施》,政策表明,成都每年将发放总额不超过1000万元的“算力券”,用于支持算力中介服务机构、科技型中小微企业、科研机构、高校等使用国家超算成都中心、成都智算中心算力资源。
再到次月,国家发布算力交易平台,促进算力的流通。东数西算一体化算力服务平台在宁夏银川在当月正式上线发布。据悉,东数西算一体化算力服务平台将瞄准目前最稀缺、刚需迫切的ChatGPT运算能力,以支撑中国人工智能运算平台急需的大算力服务。
需要注意的是,如果没有高质量数据,算力再充足也无济于事。参考ChatGPT,其高质量数据是其在有效场景下采集到的原料数据,经过数据清洗、数据标注、质检等环节后产生的。
高质量数据对于ChatGPT改进的重要性,可从以下案例中,窥见一二。根据InstructGPT实验发现,随着模型参数量的增加,模型性能均得到不同程度的提高。
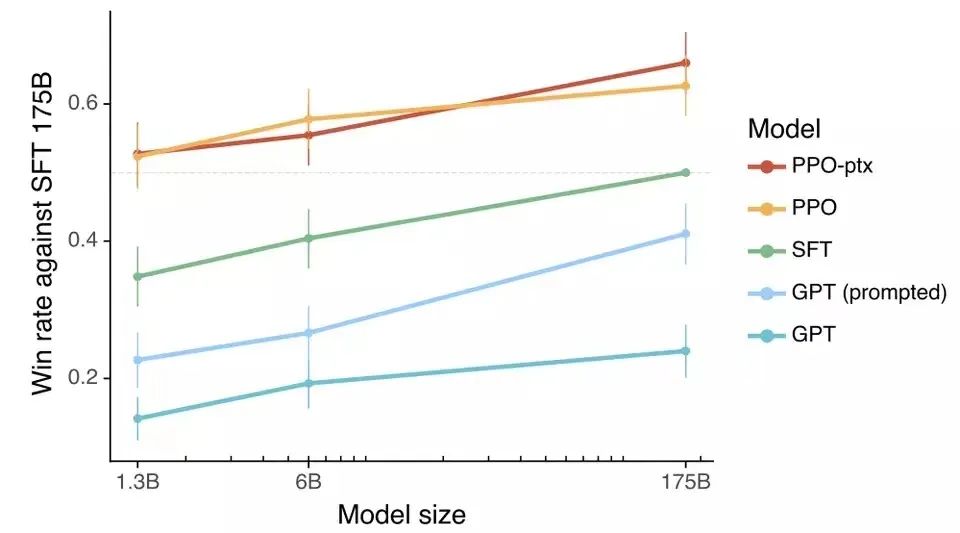
模型参数量与模型性能变化情况,图源InstructGPT
通过强化学习—PPO(近端策略优化)生成的模型,比100倍参数规模无监督的GPT模型效果更好。这里的PPO,便是2017年由OpenAI提出的一种基于随机策略的DRL算法,通过对策略的更新与监督来提高策略的效率。
可以说,有监督的标注数据是大模型应用成功的关键之一,且标注数据贵不在数量而在质量。在GPT-4等大模型高速、高质量发展中,高质量数据是“卡脖子”的存在。
现如今,各行各业纷纷向ChatGPT们发来邀约,ChatGPT们急需补充养分。而若想要真正提高ChatGPT的竞争力,高质量数据必不可少。
2、数据标注,乃“兵家”重地
从GPT-3到ChatGPT,大模型经历了5次迭代。
据东方证券研报显示,在这几次迭代中,最明显的变化是,在训练方式上增加了RLHF,即让智能体通过接收来自人类用户或专家的反馈来调整自己的行为的方法,同时用上了起码7.7万人工标注的语料库。
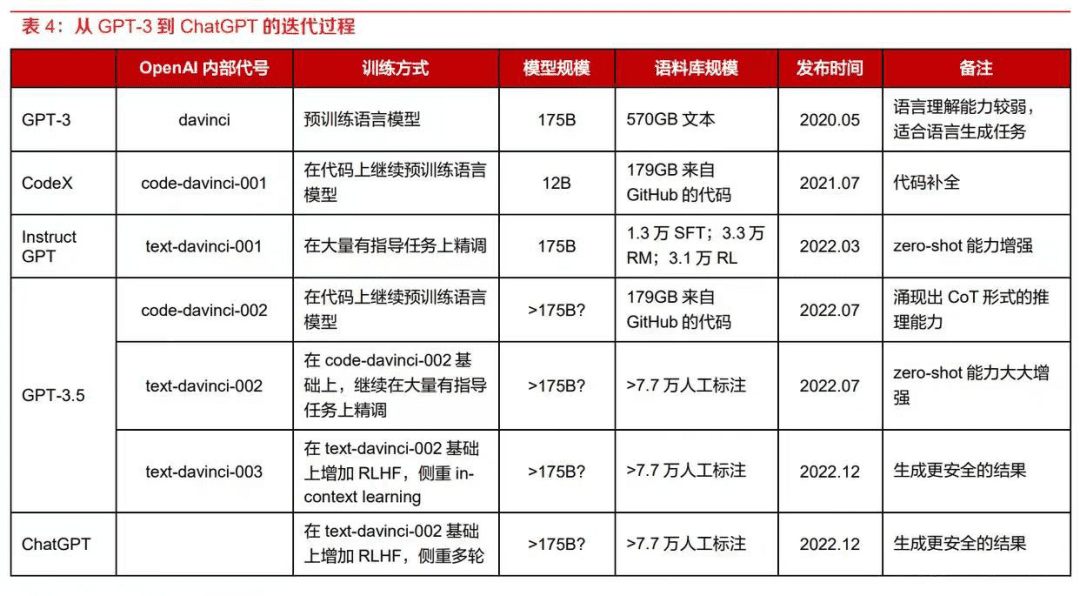
从GPT-3到ChatGPT的迭代过程,图源东方证券、未来智库
也就是说,经过RLHF的多轮磨练、大量人工标注数据的修正,2020年发布的语言理解能力较弱、名不见经传的GPT-3,才成功蜕变成为有着多轮对话能力、史上月活用户数量最快破亿应用的ChatGPT。
在这一过程中,数据标注厂商们功不可没。
目前,国内大部分数据标注服务商提供文本、语音、图像、视频等各类型数据标注,服务应用领域涵盖安防、智能驾驶、医疗、教育、金融等多个领域,主要客户包括科技公司、人工智能企业、传统企业、政府部门和科研机构等。
数据服务方面,分为数据集产品和数据资源定制服务。数据集产品按用途划分,有训练集、验证集、测试集等。而数据资源定制服务,即根据客户业务特点,专门提供定制化的基础数据全流程服务,数据内容以语音、图像、NLP、OCR为主。
目前,玩家们根据行业局势、技术优势,“各有所好”:
作为较早进入数据标注行业的玩家,标贝科技在能力上具备全面性,同时也更专注于智能语音交互。目前,标贝基于AI+SaaS开放平台,提供语料库建设与标注、指令微调服务、基于人工反馈的强化学习标注三大服务模块,与微软、百度、阿里、科大讯飞等国内外百余家企业客户建立合作,涵盖汽车、教育、客服、零售、阅读、智能硬件等多个领域。
标贝科技ChatGPT标注平台操作页面,图源标贝科技
其中,基于人工反馈的强化学习标注便是ChatGPT背后的秘密武器。简单来说,就是用人工标注的方式,不断地将结果去反馈给模型:回答好的给出正反馈,回答不好的,就通过加分机制的方式让模型进一步的自我迭代,并进行不断的调优,直到回答正确。
在数据标注行业中,除了标贝之外,也有其他玩家共同推动行业发展。
比如数据服务商Appen,主营业务包括数据采集、数据预处理与模型评价三大类,业务类型齐全。又或者是国内的厂商海天瑞声,已然形成文字、图片、音频、视频等多模态标注布局,可在全球进行190种语言、方言的采集,多场景图像、视频采集以及多行业领域文本语料制作。
但就能力来看,标贝在图文、音视频领域有着更为全方位的布局,因此其在智能语音大模型数据标注上,有着绝对话语权。
对比各家官网发现,标贝在智能语音标注层面提供的工具、产品以及解决方案是最全的,除此之外,标贝推出多语种语音识别数据库,覆盖美式英语、英式英语、韩语、法语、西班牙语、俄语、阿拉伯语等多语种,解决多语种识别训练语料稀缺的难题。
同时,标贝所打造的模型更为高效、所提供的服务也更为全面。
在对话大模型优化数据设计方案上,除了最基本的数据采集和清洗技术外,标贝科技还拥有一系列高效处理数据、优化模型的技术。
例如,模型微调技术,相对于从头开始训练(Training a model from scratch),微调技术能够省去大量计算资源和计算时间,提高计算效率的同时提高准确率。
又或者是终身学习技术,能够让模型在不同的任务上依次训练,并能够胜任所有任务,而不是像传统的机器学习那样,一个网络只能胜任一个任务。基于此,模型能够举一反三,同样能够省去大量计算资源和计算时间。
全面的服务,体现在标贝能够在模型运作的各个阶段持续助力。
基于更高效的技术以及多个场景的磨练,在中小模型落地过程中,标贝能够提供“保姆级服务”。在早期,标贝基于常年经验积累,能够帮助客户快速理清项目的技术难点和解决方案,能够帮助“初来乍到”的客户快速摸清项目脉络。
中期,标贝能够快速验证自身的数据设计和标注方案在不同开源模型规模、模型风格上的效果,从而可以预览和优化最终客户的成品模型水平,也就是说,能在项目成型之前,把偏差扼杀在摇篮里。
据标贝官方介绍,近期,其与一家大型智能AI公司合作中,在“对话大模型优化推理链(Chain of Thoughts)的数据集”项目上,标贝科技在数据方案设计阶段之前便和该客户共同验证了多个版本的设计方案在开源中小模型中的效果,迭代和修正了之前无法预估的偏置错误。
数据标注行业,玩家无数。在这之中,有着过硬技术实力、能够提供定制化、“保姆级”服务能力的厂商自然会脱颖而出。但想要让这条赛道越走越宽,还需要更多力量的支持。
3、GPT-4们嗷嗷待哺,合作乃是最优解
据国务院《新一代人工智能发展规划》预测,2025年我国人工智能核心产业规模将超过4000亿元,带动产业规模或超5万亿元。
人工智能本就火热,现如今再叠加ChatGPT推动作用,以及有标贝等高质量数据标注商的助力,让这条赛道的未来更加令人期待。但不能否认的是,目前也存在着一个残酷的事实——用于大模型的高质量数据不够用了。
据Epoch AI Research研究人员预测,大模型所需的高质量语言数据存量将在2026年耗尽,低质量的语言数据和图像数据的存量将分别在2030年至2050年、2030年至2060年枯竭。
如果数据效率没有显著提高或有新的数据源可用,那么到2040年,大模型的规模增长或许将会放缓。
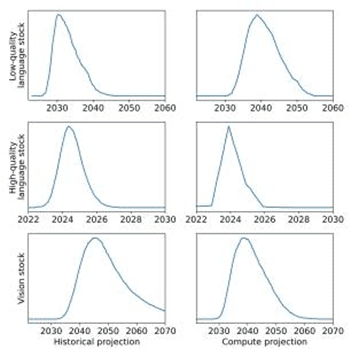
不同数据类型的消耗趋势和耗尽日期,图源Epoch AI Research
这就意味着,市场急需标贝科技等数据标注厂商高效率地产出高质量数据,为ChatGPT们补充养分。
但就目前来看,国内的数据标注行业,仍然稚嫩。
其中较大的问题是,数据标注行业缺乏“条条框框”的约束:例如行业标准的制定,商业模式的敲定等等。某AI数据标注训练师对连线Insight表示,如今的数据标注公司之间一味地拼低价乱象丛生,最终拿到项目的乙方往往没有能力承接。
与此同时,数据标注行业中的一些玩家也处于毛利率、营收持续走低的困境中。
根据海天瑞声2019-2021年财报显示,其毛利率从2019年的70.25%下滑至2021年的64.01%,营收方面也从2019年的2.38亿元,下滑至2021年的2.06亿元。
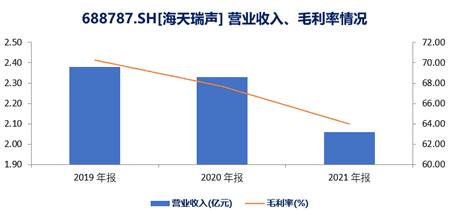
2019-2021年海天瑞声营收、毛利率情况,数据来源于同花顺,连线Insight制图
更为重要的是,随着大模型的迅速发展,供大模型训练所需的语料量,非一家能够满足。
当前大模型训练需要的语料量非常庞大,但由于历史原因,语料在不同语言之间存在局部的不均匀性问题。
一个典型的例子是,绝大多数源代码是用英语书写的,但代码语法本身是基于英文单词设计。这导致不少模型即使参数量很大,却无法准确地捕捉到中文术语和源代码的对应规律,无法在中文用户的提示下写出同等质量的代码。
高质量数据需求迫在眉睫,现有语料库质量堪忧,而国内数据标注行业还似一盘散沙,标贝针对该困局,提出了自己的解法。
根据标贝官方消息,其将公开一系列数据集,旨在解决这类局部不均匀性的问题。
标贝的思路是,将代码中的备注内容替换成了高质量的、符合表达规律的中文汉字。之后,还会按照实际业务需求和国内开源大模型的发展情况,定期设计和公开类似的数据集。
在这之中,标贝将更好地利用存量代码进行数据增强处理,以提高大模型在书写代码、专业长篇讨论时处理中文文本的能力。同时,标贝也呼吁更多的数据标注厂商能够参与进来,共同提高GPT-4等大模型语料库的数据质量。
在业内看来,GPT-4等大模型潜力无限,标贝科技也有能力把好数据标注的关,使得大模型能够产出更高质量的数据。同时,数据标注行业仍需更多数据标注厂商共同合作,丰富数据集,改善语料库质量,共商行业标准,厘清商业模式,高效率地产出高质量数据。
正如地平线创始人余凯为《深度学习革命》一书写的序言“人工智能领域能得到快速发展,关键在于有着众多的合作者来推动这项事业”。而作为技术底座的数据标注行业,更是如此。
本文来自投稿,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/quan/94802.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫