

![]()
▲阿里推出了AI大模型“通义千问”,并拟将阿里所有产品都接入。
文 | 佘宗明
01
ChatGPT如此多娇,引无数大厂竞折(对)腰(标)。
在国内,首个折腰的是百度。3月16日,文心一言正式发布。10年在AI上砸了千亿的百度,由此拉开了国内AI大模型混战的序幕。
这几天,AI大模型市场更是燥起来了:
4月9日,基于360GPT大模型开发的人工智能产品矩阵“360智脑”开放内测;
4月10日,“AI四小龙”中的第一股商汤科技发布“日日新SenseNova”大模型体系;
同日,搜狗创始人王小川正式官宣成立百川智能,表示“争取年内发布国内最好的大模型”,昆仑万维宣布大模型“天工3.5”4月17日启动测试……
这其中,最能引爆市场的,要数全球首个突破10万亿参数的AI大模型——阿里“通义千问”的面世。
在4月4日用“鸟鸟分鸟”测试了下舆论反应、4月7日来了波定向邀测后,4月11日,在2023阿里云峰会现场,阿里正式发布“通义千问”。
阿里巴巴董事会主席兼CEO、阿里云智能总裁张勇透露,阿里大模型将会“两条腿走路”:对内改造业务产品,阿里所有产品都将接入;向外做企业专属模型“底座”,可以为每家企业打造属于自己的大模型。
短短几日,国内AI大模型赛道锣鼓喧天、鞭炮齐鸣、红旗招展、人山人海。
接下来准备登场的,还有腾讯“混元”、华为“盘古”、京东“言犀”、字节自研大模型、科大讯飞1+N认知智能大模型、浪潮“源1.0”……
这跟国外“微软系”的OpenAI推出ChatGPT和GPT-4、谷歌公布LaMDA和PaLM等大模型、Meta发布开源大模型LLaMA的激烈竞争节奏遥相呼应。
可以这么说:AI大模型热,热过东京。
在此情形下,对AI行情过热的担心也随之出现。
盛产灼见的冯大辉老师就写了篇《ChatGPT时代的大炼钢铁》,感慨“网上涌现出来不少基于ChatGPT的衍生项目,有点像当年的小锅炉土法上马大炼钢铁。推特上现在很热闹,更是人均一个GPT小锅炉。”
他倒没有抨击AI大模型热,只是在对衍生项目“创新的活力在涌动”表示欣赏的同时,对套壳上马或借机炒作拉升股价的做法表示了不欣赏。
但在网上,有些人将“大炼钢铁”“大跃进”的评价,送给了这轮类ChatGPT产品研发的热潮。
有人嘲讽,ChatGPT在中国即将“亩产过万”;也有人调侃,下个阶段该是“全民大模型,ChatGPT进万家”了吧;还有人直言,ChatGPT是怀胎十月的结果,“凑10对夫妻,想1个月生出小孩”就是胡闹。
02
在我看来,批评跟风追潮无可厚非,但无需将这视作“大炼钢铁”“大跃进”。
大炼钢铁大跃进,终究是那个特殊年代“计划”出来的产物。
这轮AI大模型热固然也带有大干快上的意味,但与之没有可比性:它跟具有特定指向的“大炼钢铁”“大跃进”无关,毕竟它是市场自发秩序下的产业躁动。
倒不是说这股热潮没有可堪诟病之处,泡沫大、套路多的问题就摆在那。
眼下,就算是很多跟AI八竿子打不着的企业,也在想方设法往ChatGPT上硬套——就像去年上半年一堆不沾边的企业都想往元宇宙上硬蹭那样。
以至于有人调侃,干脆弄个ChinaGPT概念股,茅台、五粮液可以碾压一大片。
这显然不太正常。类ChatGPT产品又不是公用WIFI,说蹭就能蹭上。
拿AI大模型研发来说,阿里云CTO周靖人就表示,动辄超千亿参数的大模型研发,不是单一的算法问题,也不是靠简单堆积GPU就能实现的,这是囊括了底层算力、网络、存储、大数据、AI框架、AI模型等复杂技术的系统性工程,需要AI-云计算的全栈技术能力。
说得通俗些就是:一般玩家没那个技术积淀,也没那个资金规模。
可眼下AI领域热火朝天的景象,很容易让人看到国产芯片和操作系统研发一哄而上、一地鸡毛的影子。
很多人担心AI大模型热变成又一个“大炼钢铁大跃进”,其实是曲线表达某种顾虑:
这会不会导致产能过剩、资源浪费?
又是否会变成让股民为泡沫买单的割韭菜游戏?
着眼现实看,两个问题的答案都是肯定的。
这么多企业扎堆入场,重复造轮子的情况在所难免,这势必会带来算力浪费。
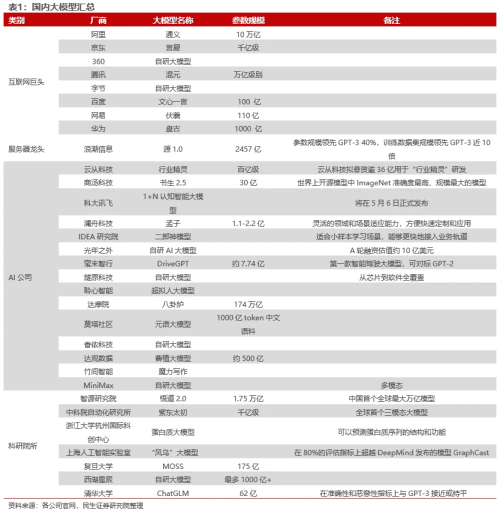
![]()
▲国内大模型汇总。图片来源:民生证券研究院。
很多人在谈论算力时都容易忽略或回避这点:计算会带来能源消耗和碳排放增量。
2009年谷歌方面曾透露,在谷歌上的每次搜索,会产生0.2克的二氧化碳排放量,哈佛大学物理学家阿历克斯·维兹纳尔·格罗斯则称,每次搜索产生的二氧化碳排放量高达7克。
随着技术进步,如今单位算力耗能的确少了,但合起来仍是个天文数字。在算力已成新生产力的时下,跟计算量指数级上升伴生的,也是巨大能耗。
第三方分析估计,仅训练GPT-3就消耗了1287兆瓦时,并导致超过550吨二氧化碳当量的排放。ChatGPT的参数更多,碳排放就更大了。
如果说,单车“垃圾围城”与退押金难题是共享单车平台将酣战的负外部性向社会转嫁,那碳排放就是AI大模型热的主要负外部性所在。
至于很多企业瞄准股市G点玩对韭当割的把戏,只能说是可鄙。
据说对ChatGPT套皮最多的企业,就来自于咱们这。一堆卖账号卖课的,已经成了第一波靠GPT致富的人了。
调用ChatGPT大模型没问题,搞山寨、玩套路,无疑逾越了底线。
对这些问题,该正视就得正视。
03
饶是如此,不能在看到感冒症状后,开出的却是治癌药。
在舆论场中,主张用“集中力量办大事”来避免一堆企业各自“建小高炉大炼钢铁”的声量不小,呼吁有关部门出来管一管的声音就更多了。
在有些人看来,“群雄并起”式的无序竞争,必定会带来AI市场过热,也带来重复性建设的问题,导致本该用来攻坚的大量资金弹药被浪费。
他们认为,该将所有科技企业的AI技术研发“拧成一股绳”、组成“抗OpenAI联盟”,或是该由AI“国家队”来主攻,科技企业打配合。
一边将AI大模型热说成裹着计划底色的“大炼钢铁大跃进”,一方面开出带有计划烙印的药方,这着实有些分裂。
事实上,担心当前局面下的AI大模型热变成翻版“大炼钢铁大跃进”,或许是杞人之忧。
即便是“非理性繁荣”,AI领域的市场竞争白热化,对中国AI的整体发展也是好事。
管理学者迪伊·沃德·霍克说:“我们正好处在一个历时400年的时代即将结束、另一个时代正冲破阻力而来这样一个时刻。”
而通用AI将成为提升21世纪整体社会生产力最为重要的赋能技术,AI的iPhone时刻已到……诸如此类的叙事,就与之扣合。
这时候,科技企业想抢滩布局未来,再正常不过。虽说AI大模型很烧钱,可场景化应用有钱景。百度阿里的“模型+工具平台+生态”三层共建模式,就连着广阔的前景。
可在很多人看来,AI研发就该十指成拳,而非各自为战,不然没法呈现“中国AI军团”的合力。
问题来了:国内头部科技企业都在摩拳擦掌,你让谁上场,让谁退出?是抽签决定,还是竞标筛选?
但这么一哄而上,不会造成资源浪费吗?有些人会这样反驳。
就这么说吧:要看到充分市场竞争下的资源浪费,更要看到缺乏足够竞争下的资源浪费,后者通常比前者更严重。
换句话说:竞争必然带来浪费,但不竞争经常带来更大的浪费。
应看到,这些年来,中国市场的强敏捷性,让它对每个风口的反应能力都极快,得益于数字基建与制造能力上的积淀,国内许多企业抓住了新兴制造领域以往很难抓住的机遇。
比如,智能手机。
iPhone出来后,华为、小米、oppo、vivo都跟上了,360、联想、乐视、魅族、锤子也接连登场,华强北也跟着躁动不安,将国内外手机市场卷成了红海。
浪费吗?当然会有产能浪费。但正是凭着激烈竞争,在功能机时代没有姓名的中国手机制造业,在移动互联网时代跻身世界前列。
再如,新能源汽车。
特斯拉出来后,比亚迪和蔚小理都跟上了,哪吒问界极氪零跑等也紧随其后,去年10月,里斯战略定位咨询在《全球新能源汽车品类趋势研究报告》中指出,中国新能源汽车品牌的数量高达150多个,整车制造企业数量有 198 家,系全球最多。数据显示,我国现存新能源汽车相关企业60.58万家。
浪费吗?同样会有各类资源浪费。但也是凭着激烈竞争,在燃油车时代身处德系日系巨头夹缝的中国汽车制造业,在新能源汽车时代做大做强。
依照部分人的逻辑,之前一堆企业下场造手机造车,何尝不是大炼钢铁大跃进?
这里面,圈地套补之类的乱象确实该治理。但就所谓的产能浪费而言,它本质上也是由此锻造出来的强大产业链供应链能力的成本。
没有此前的白热化竞争及伴生成本,中国制造整体实力何以做强?
04
说起来,资源浪费是很多人反对充分化市场竞争的关键依据——虽说他们会说自己反对的不是竞争,而是“无序竞争”。
之前互联网企业扎堆“造车”时,不少人就认为,这会带来过度建设。
经济学家曹远征就说得挺好:市场过程中有失灵,有弊端,但是你要理解,它的本质是,只要市场竞争,就一定会有过剩,然后靠竞争优胜劣汰出来,这是它规律性的表现。
他对“先过剩供给再优胜劣汰,付出的代价太高”的说法驳斥道:
这个想法是错误的。计划经济就是这个想法,叫人为配置资源。但最后我们发现,所有事都是事后知道的。你说当年我要这样就好了,但是你在当年是不知道这些情况的。你只有选择了多样性,然后才会优胜劣汰出最终的选择。
看不见的手就是看不见的,你想努力把它看见,但最后发现你还是看不见。
模拟市场是模拟不出来的,这就是市场的魅力。回头看时,市场经济发展中,好像是会出现重复建设,过剩浪费,但它是有效的。计划经济看起来也产生了很多东西,但计划经济造成的浪费,是永久性的。
在他看来,肯为创新承担风险的企业家有着天然的敏感性,他们会发现市场的诉求,打通市场的堵点。
这跟哈耶克说的有相通之处:社会的发展就是要增加机遇,促使个人在天赋和环境间形成某种特别的组合。
那有没有办法去减少激烈竞争下的“非必要浪费”?
有些学界业界人士将目光看向了包括超算算力底座在内国家级数字化基建的供给。
如平安首席科学家肖京就认为,在未来人工智能的大模型浪潮中,我国更应该利用集中优势力量的体制优势,避免各家分别“建小高炉大炼钢铁”,而是整体统筹,加快打造国家级数字化底座建设。
他主张,通过协调各方资源,引导重大科技基础设施、高校及科研院所、头部企业共同参与,集中贡献算力、数据、资金、人才及场景等各方资源,建立共享、共建、共用、共创机制和数字化底座的市场化运营机制,强化通用数字化建设底座的打造。
周鸿祎也提出将政、产、学、研、用打通,打造“理想主义+实用主义”的科研生态的设想。
他提出,应该发挥新型举国体制,把知名大学、国家实验室、科研机构、科研体系和已在大模型自然语言处理有跟踪和研究的科技公司结合起来,通过合作方式推进。既然技术上别人已经领先了,不要再去重新“大炼钢铁”,重复发明轮子。
这类想法,似乎契合经济学家常修泽描述的情形:非市场化的“社会巨型科层”与新古典的“纯粹市场体系”从组织资源配置的“两极”向“中间地带”靠拢,以寻求现代市场与科层结构的新组合。它是否可取可行,仍待讨论。
可以肯定的是,ChatGPT是市场创新生态体系上结出的果子,打造AI大模型也需要笃定市场导向。这并非要拒斥算力基础设施的供给,只是说要让有形的手止于该止的地方,其他的交给无形的手来。
在激烈的市场竞争下,有的企业也会以开放为手段提升自身竞争力。阿里云表示要为企业级市场提供普惠AI基础设施,帮企业搭建专属模型,就是提升自身竞争力的方式。
事实证明,大浪淘沙,最终会淘出最具竞争力的“硕果”来。
05
说到底,没必要将AI大模型热视作“大炼钢铁大跃进”。即便存在所谓的“过度竞争”,那也是生成式AI发展到Gartner第二阶段“期望膨胀期”的表现。
吐槽泡沫没问题,但不能对中国版ChatGPT抱有双标式矛盾心态:AI大模型出来前,批中国科技企业没有硬科技实力;多个AI大模型出来后,又批市场过热。
认为AI大模型要“不多不少”才好,未尝不是“计划思维”在作祟。
只要遵循市场规律,不随意拉踩也不揠苗助长,在当前的数字基建支撑下,国内科技企业们自然会有足够动力,去用AI技术突破赢得市场地位。
不要只认为AI技术攻坚攸关国家数字主权,它也关乎企业未来竞争力。谁又不想抓住未来的Window、iOS、Android呢?
当此之时,社会该做的,也许就是厚植创新沃土,为创新激励型环境营造做加法。
厄休拉·M ·富兰克林在《技术的真相》中说:(技术)尺寸是生长的自然结果,但生长本身是不能被强取的,它只能通过提供一种适宜的环境而得到培育和鼓励。生长是发生性的,不是制造出来的。在一个生长模式之内,人类所能做的就是发现对生长而言最适宜的条件,并努力满足这些条件。在目前每一种环境中,生长有机体都是按自身的比率发展的。
要想让中国版ChatGPT加速成长,就该给自发性市场竞争以包容空间,而非轻易将白热化竞争斥为“大炼钢铁”“大跃进”。
本文来自投稿,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/quan/95232.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 