

作者|王嘉攀 司马洁
本报告由势乘资本和光锥智能联合发布
在后摩尔时代,存算一体作为可10倍提升单位功耗下算力的颠覆性技术之一,其底层原理、应用前景及可实现性如何?当前的产业现状及行业创新创业机遇如何?本文从底层技术原理、产业需求变革说起,全面梳理存算一体产业创新浪潮与投资机遇图景:

一、核心判断及观点
1.存算一体属于芯片的底层架构创新,阶段非常早期,其产业链空白度及机遇挑战不亚于20年前从头开始发展GPU。
2.相对于量子计算、光子芯片、非硅基芯片等前沿算力方案,受益于介质等技术成熟,存算一体芯片更有希望在3-5年内广泛落地。
3.存算一体领域属于少有的国内外同时起步的芯片领域,中国更有希望做出引领世界的产品。
4.当前产业界及投资方认为产业链上下游仍不完善,仍需5-10年才能投入使用,但这也意味着更为全面的创新机遇。
5.当前行业玩家竞争主要集中在不同的存储介质,长期来看存储介质路线并无差别,在设计方法论、测试、量产、软件、场景选择等方面全方位竞争是长期关键。
6.第一款、第二款芯片场景的选择非常重要,率先取得商业化验证,打造爆款是未来三年胜出关键。
7.作为新兴技术,产业人才主要集中于学界而非企业界,因此院校技术、人才转化资源非常关键。
8.除创业公司外,大学院校及巨头也在同步做研发,长期来看,真正强劲的竞争对手可能是观望中的巨头。
9.存算一体芯片相对于CPU/GPU等主流算力并非是取代关系,未来将会成为主流算力的重要补充,更侧重于高能效的算力。
二、存算一体技术的背景及原理
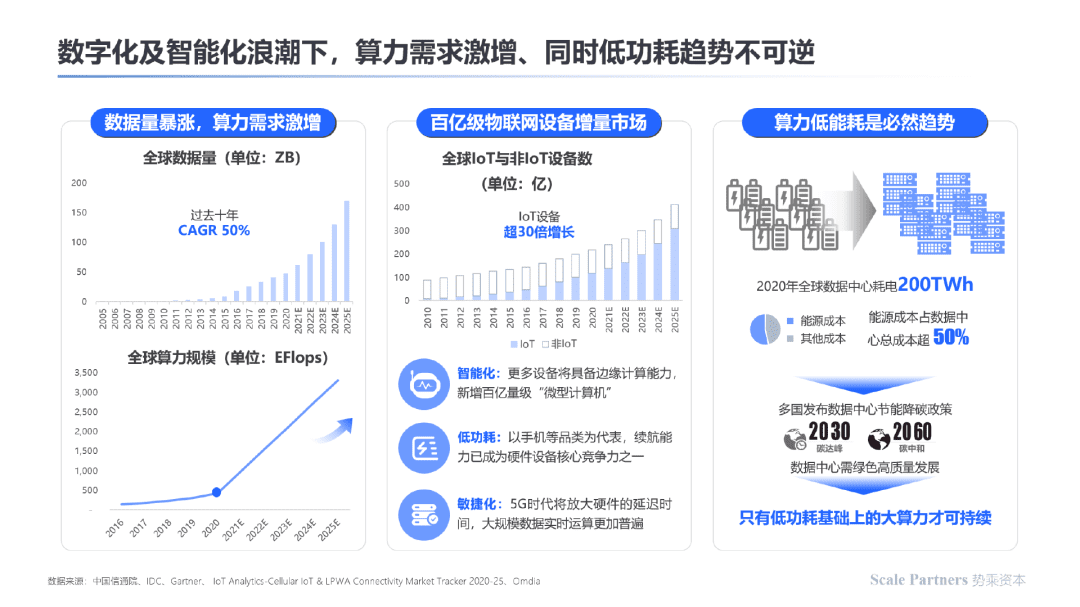
在全球数据量呈指数级暴涨,算力相对于AI运算供不应求的现状下,存算一体技术主要解决了高算力带来的高能耗成本矛盾问题,有望实现降低一个数量级的单位算力能耗,在功耗敏感的百亿级AIoT设备上、高能耗的数据中心、自动驾驶等领域有望发挥其低功耗、低时延、高算力密度等优势。
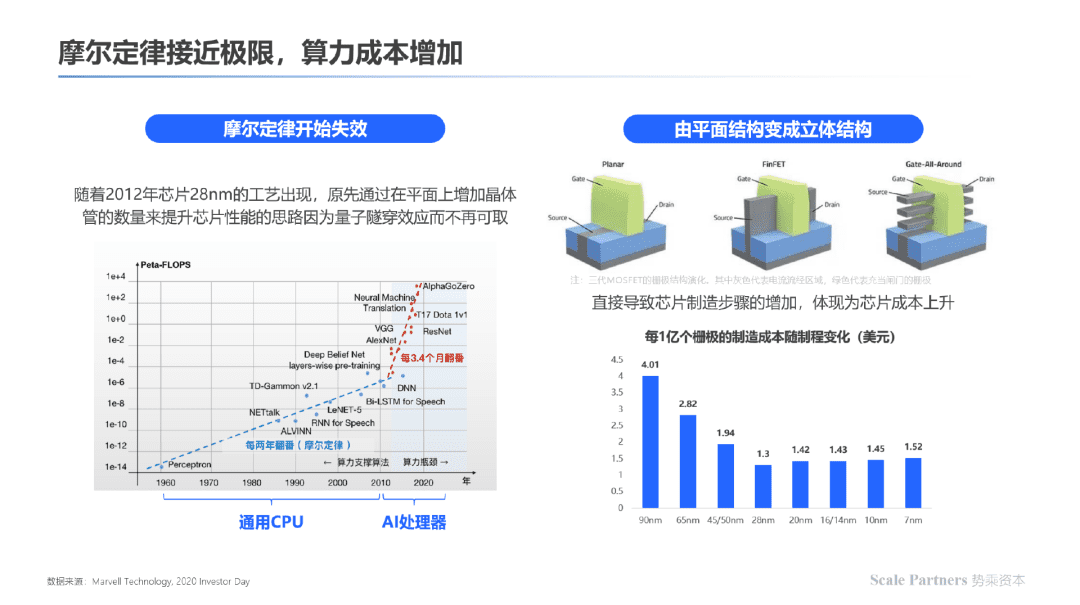
在现有的成熟架构及工艺下,当前依靠制程技术进步,增加晶体管密度提升算力、降低功耗已逐步趋于物理极限,且成本逐步提高;
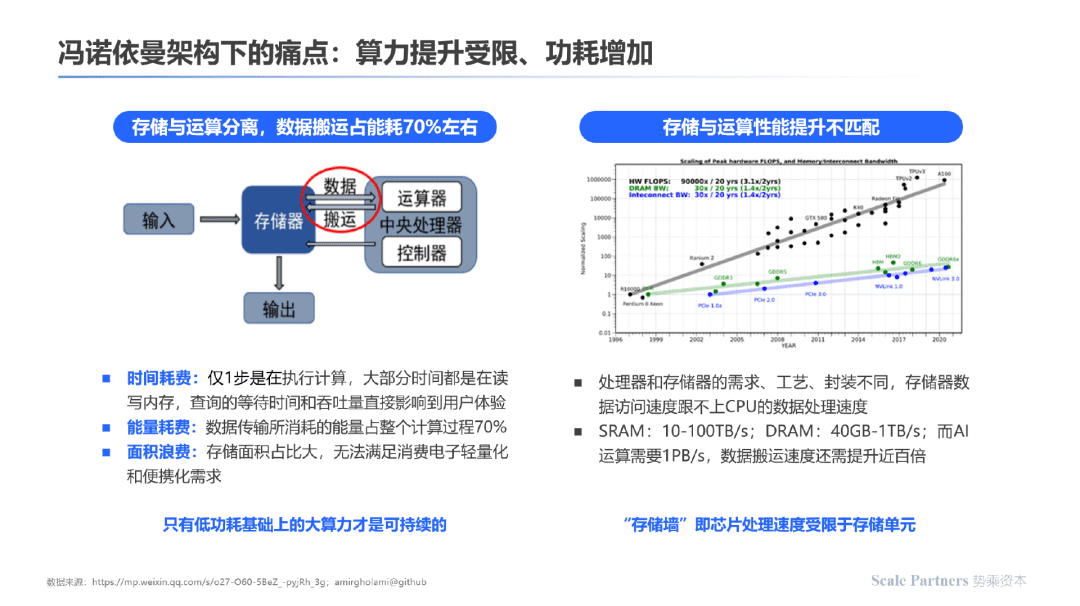
在冯诺依曼架构下,由于数据存储与运算单元分离,算力提升受限,功耗增加:
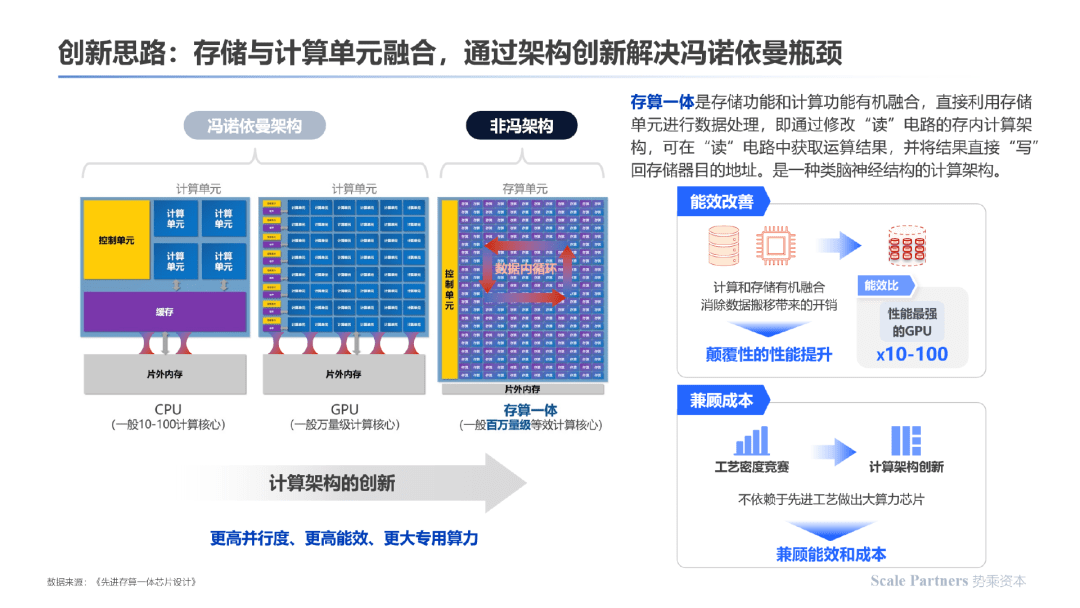
应对存储单元与计算单元分离的现状,存算一体技术思路应运而生,在器件单元上存储与计算单元融合,通过底层的架构创新解决冯诺依曼架构的固有瓶颈:
由于存储介质技术在近年来不断突破,此外AIoT时代对于设备的智能化、低功耗、体积小、低时延等特性提出了天然要求(而现有的技术路线未能很好的满足需求),在技术突破叠加市场需求的双重作用力下,存算一体技术当前已到达产业化爆发拐点:
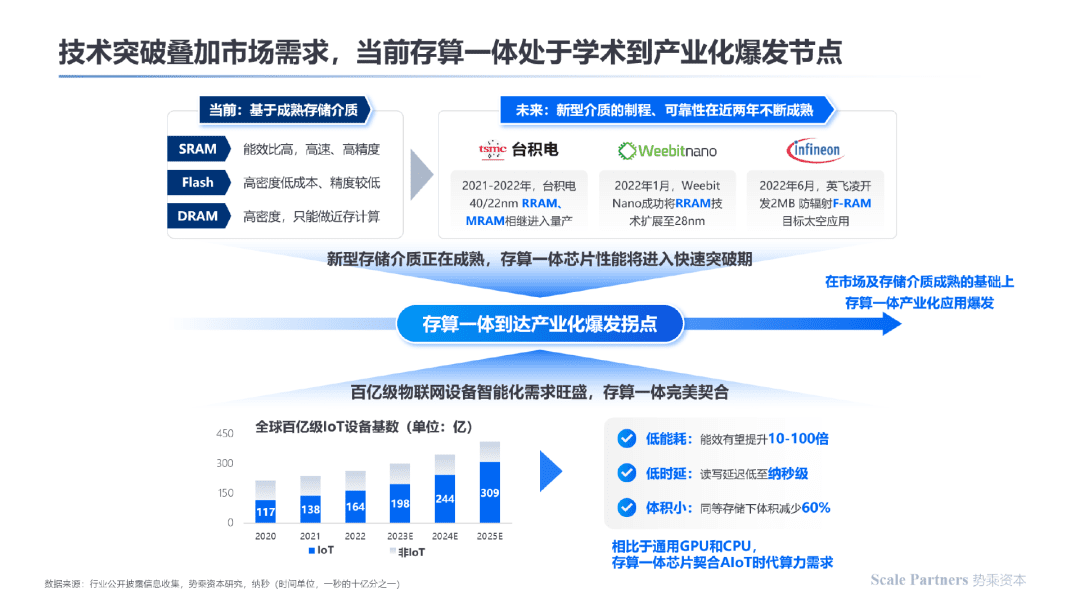
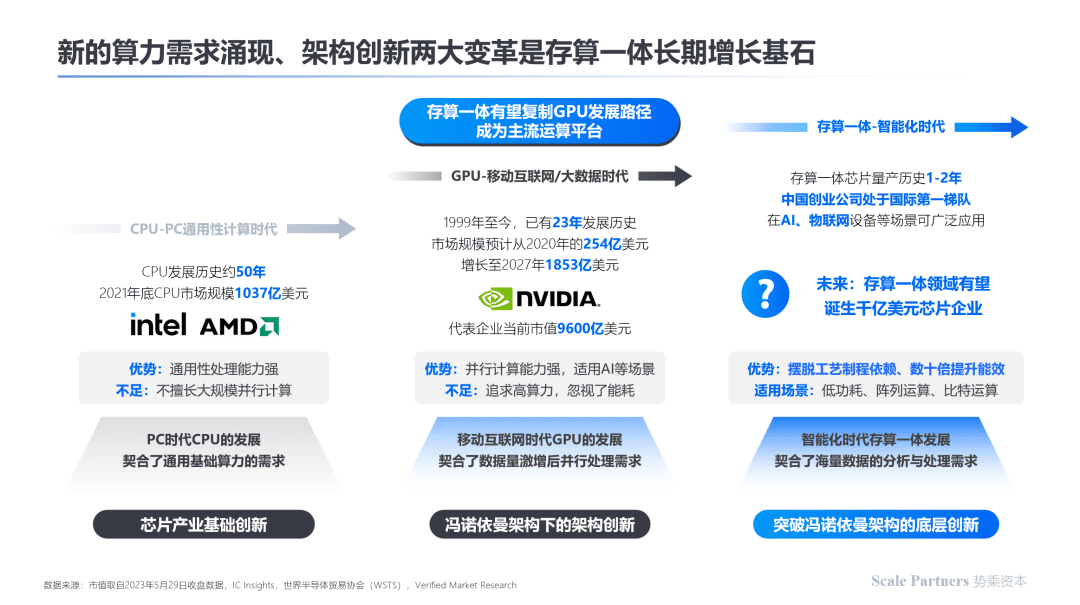
相对于五十多年前CPU的诞生以及二十多年前GPU的诞生,当前存算一体技术仍处于早期阶段,未来依靠其更好的并行度、更好的能效比等特性,有望成为智能化时代的主流算力平台之一,与现有的算力解决方案互为补充。
伴随架构创新的巨大机遇和算力需求的变化,在存算一体领域有希望孕育下一个千亿美元级的芯片巨头,当前我国存算一体技术研发与国外处于齐头并进的阶段,我国存算一体技术及产业有望引领世界。
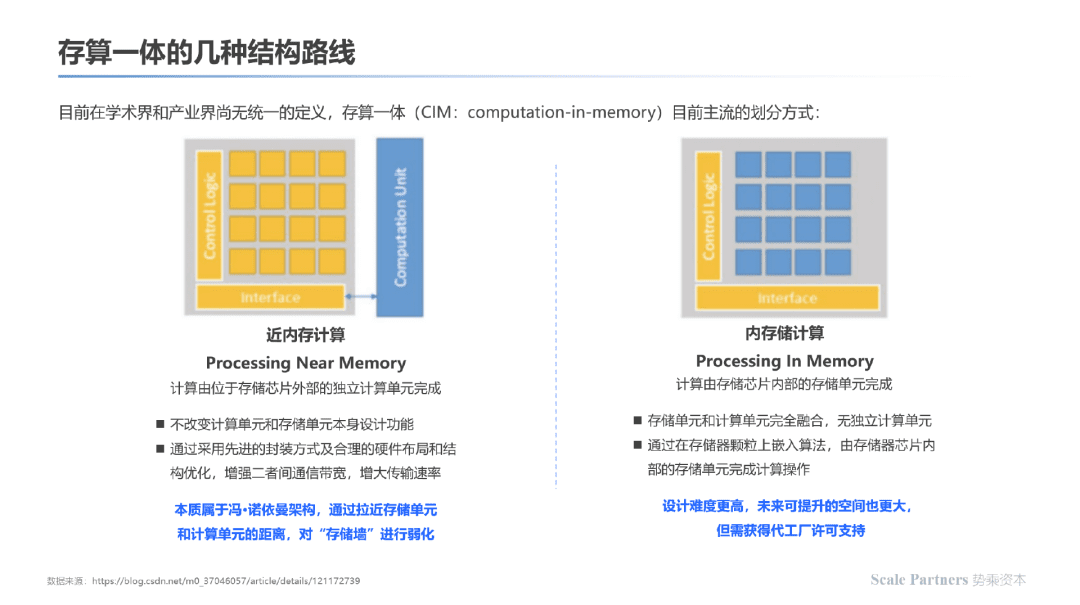
存算一体当前有一些相似的称呼(如近存计算),其内在结构差别如下:
近存计算:不改变计算单元和存储单元本身设计功能,通过采用先进的封装方式及合理的硬件布局和结构优化,增强二者间通信宽带,增大传输速率;本质上属于冯诺依曼架构,通过拉近存储单元和计算单元的距离,对“存储墙”进行优化。
内存储计算:存储单元与计算单元完全融合,无独立计算单元,通过存储器颗粒上嵌入算法,由存储器芯片内部的存储单元完成计算操作;其设计难度更高,未来可提升的空间也更大,但需要获得代工厂许可支持。本文所探讨是存算一体/存内计算企业主要集中于这类。
三、存储介质技术路线的选择
分析存算一体,当前存算一体芯片研发企业/机构在成熟介质上的切入点集中在SRAM、Nor-Flash和DRAM等;部分学术机构选择切入RRAM等新型介质研发。
从存储介质的分类来讲,分为易失性存储器和非易失性存储器。
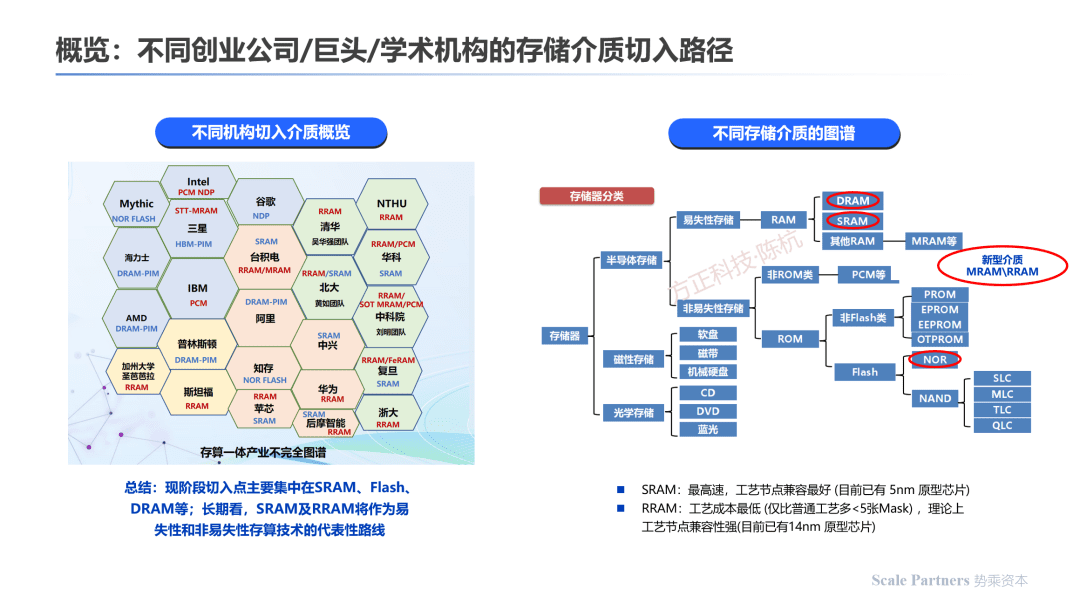
上图引自方正证券研报
当前不同的存储介质在计算机架构中均承担着必要的工作任务,其中SRAM距离CPU最近,响应时间最快,存储容量较小;
其次分别是DRAM、NAND-Flash等介质,在传输速率、存储容量上各有其特点:
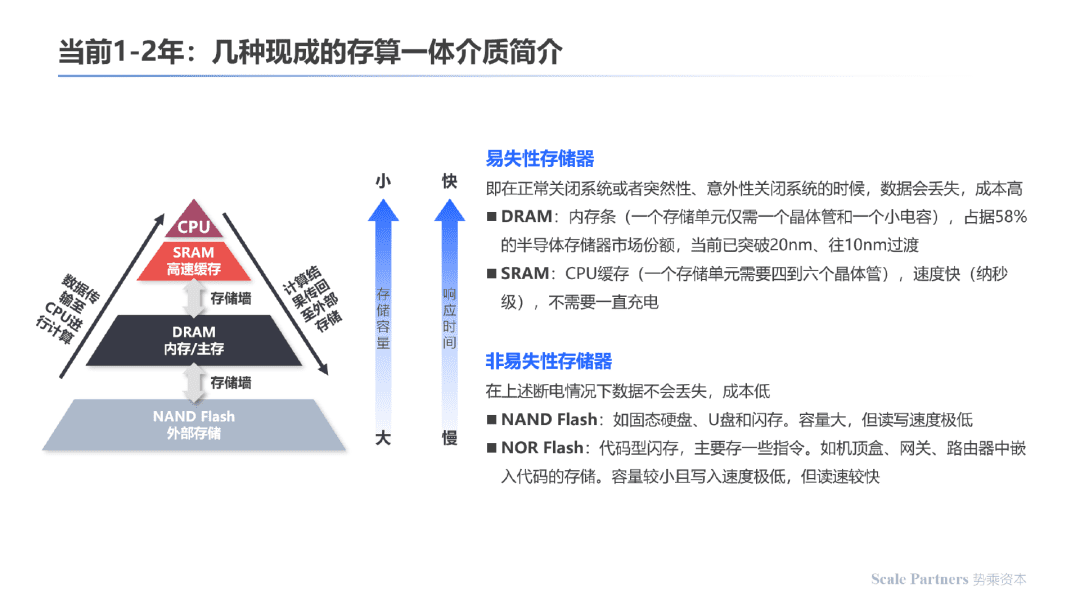
1.易失性存储器:即在正常关闭系统或者突然性、意外性关闭系统的时候,数据会丢失,成本高。
DRAM:内存条(一个存储单元仅需一个晶体管和一个小电容),占据58%的半导体存储市场份额,当前已突破20nm,往10nm过渡。
SRAM:CPU缓存(一个存储单元需要4-6个晶体管),特点是速度最快(纳秒级),不需要一直充电。
2.非易失性存储器:在上述断电情况下数据不会丢失,成本低。
NAND Flash:如固态硬盘、U盘和内存;容量大,但读写速度极低。
NOR Flash:代码型内存,主要存一些指令;如机顶盒、网关、路由器中嵌入代码的存储;容量较小且写入数据极低,但读速较快。
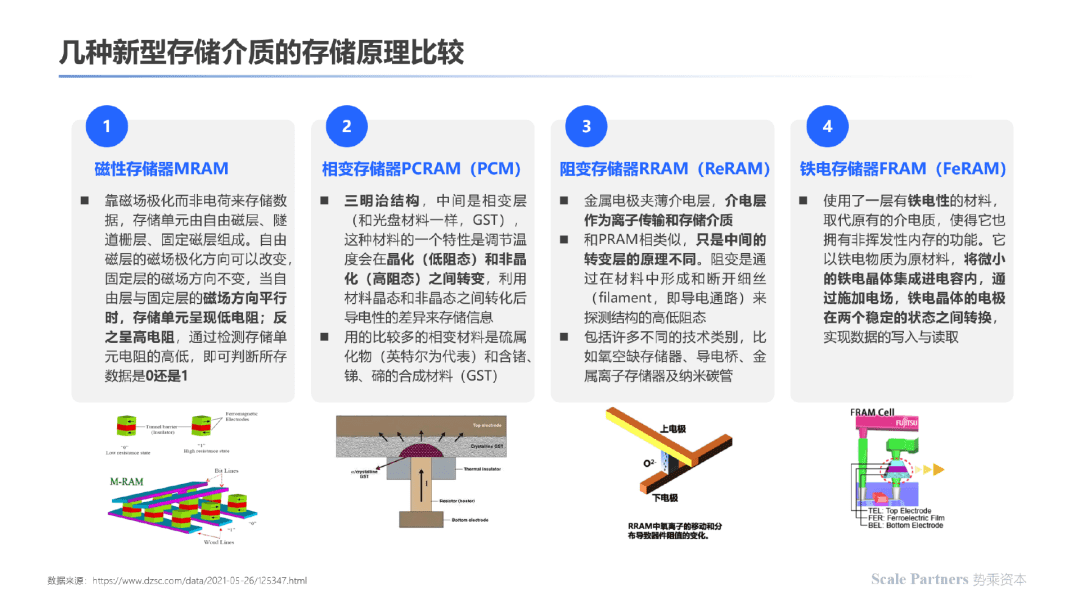
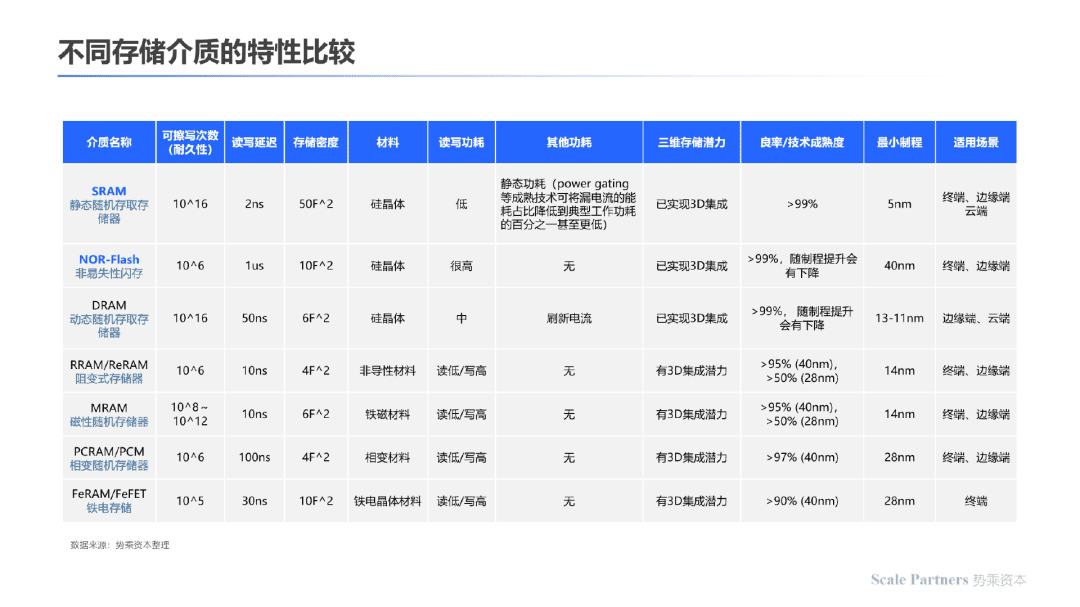
长期来看,存算一体芯片产品化的快速发展离不开新型存储介质成熟度提升的助推,以下为不同新型存储介质的原理比较:
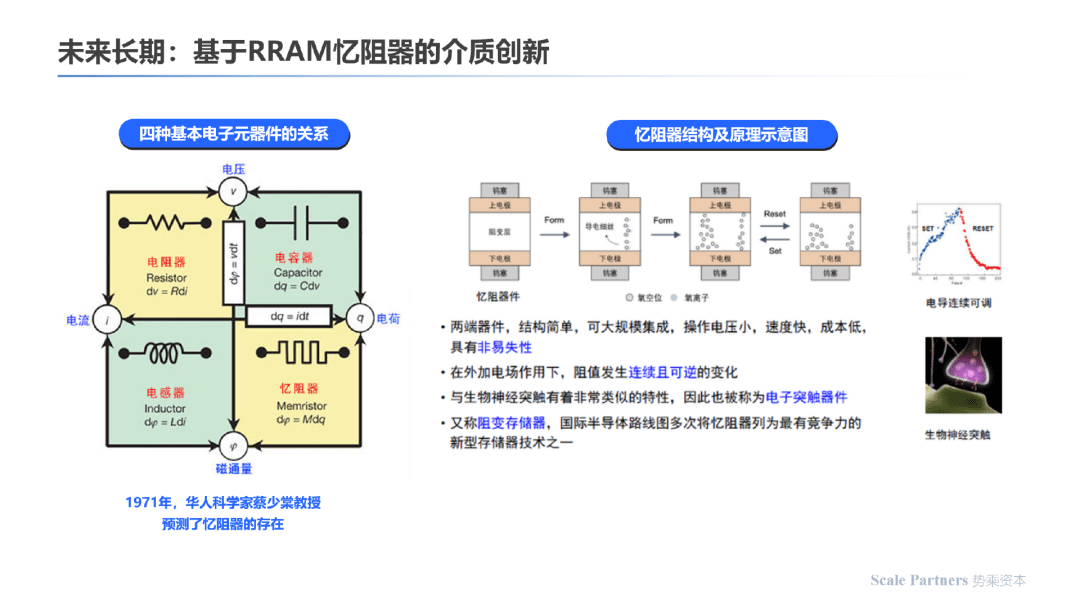
长期来看,RRAM(忆阻器)是除了电阻器、电容器、电感器之外的一大新发现;其与生物神经突触有着非常类似的特性,因此也被成为电子突触器件。
以下为新型存储介质的性能比较:
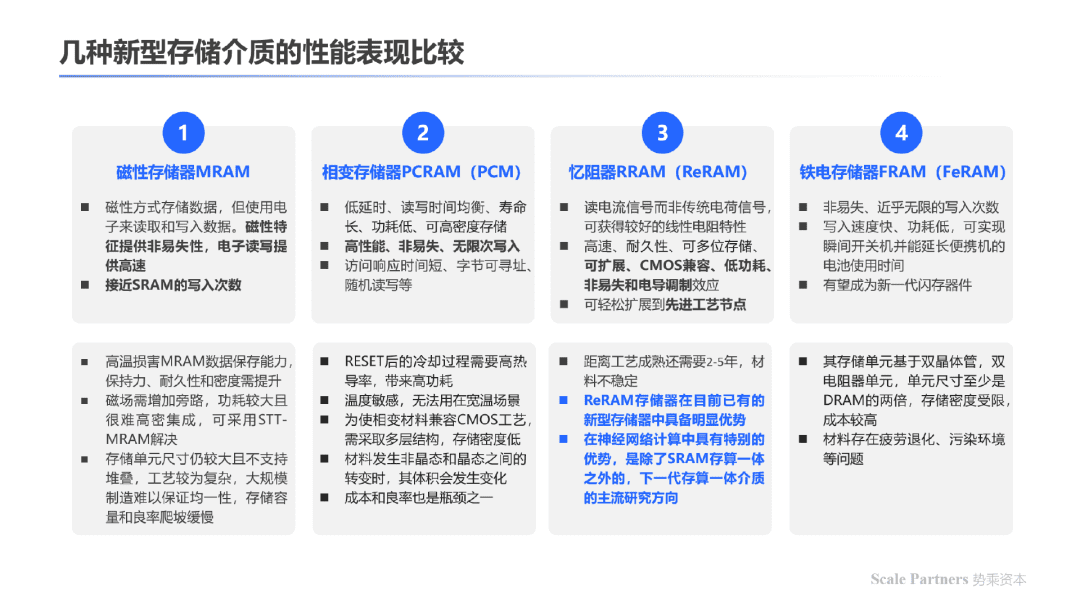
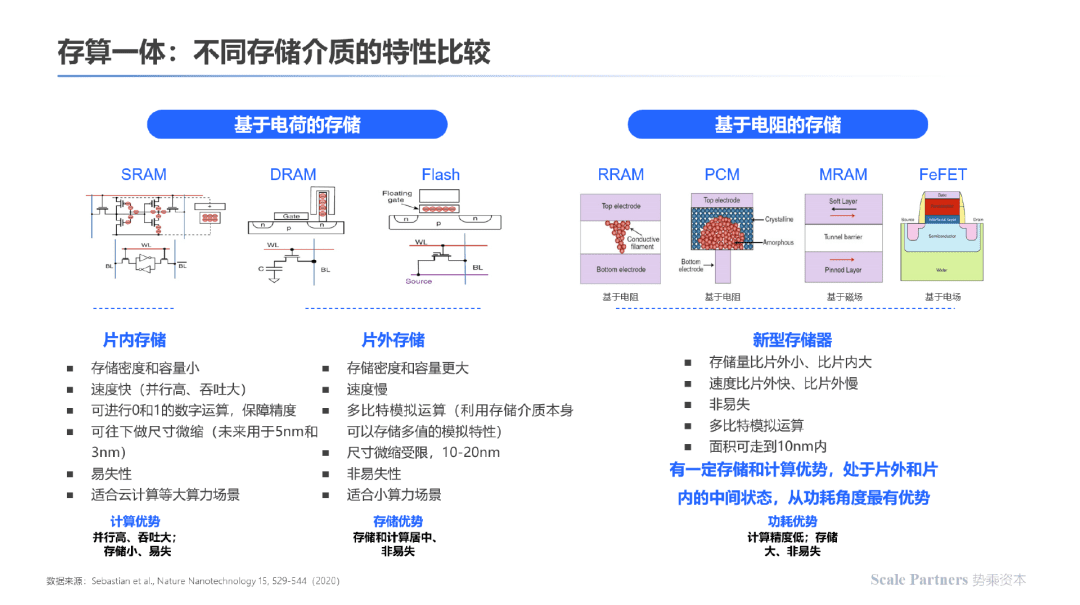
以下为不同存储介质的存储原理及客观性能比较;其中成熟的存储介质如SRAM、DRAM、Flash基于电荷的移动完成数据存储;新型存储介质与RRAM、MRAM等基于电阻大小的变化完成数据存储功能。

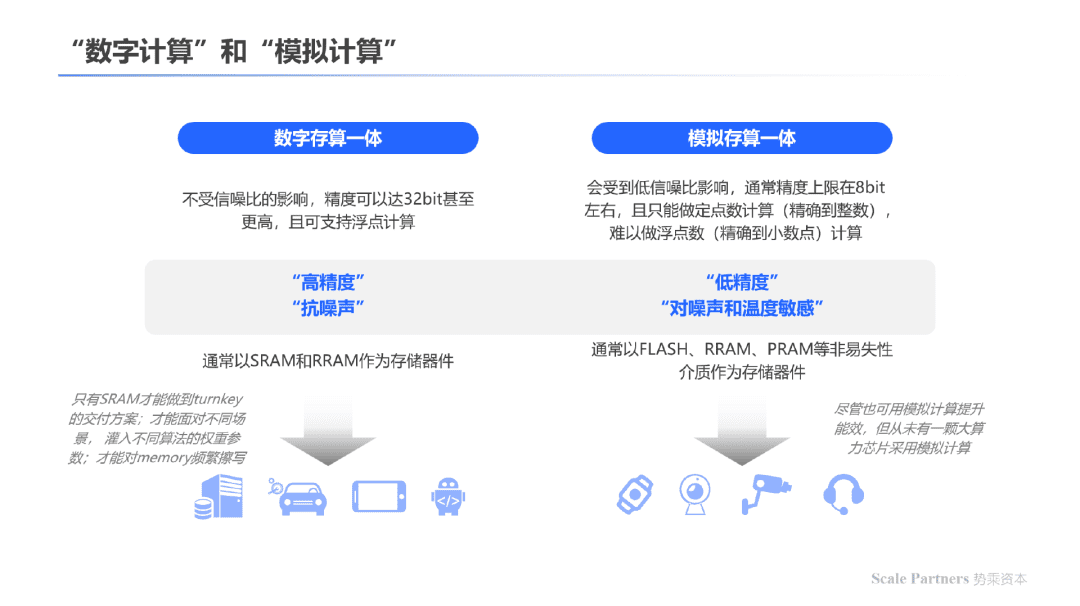
除介质以外,选择数字计算与模拟计算也是影响存算一体芯片性能的因素之一;其中数字计算精度更高。
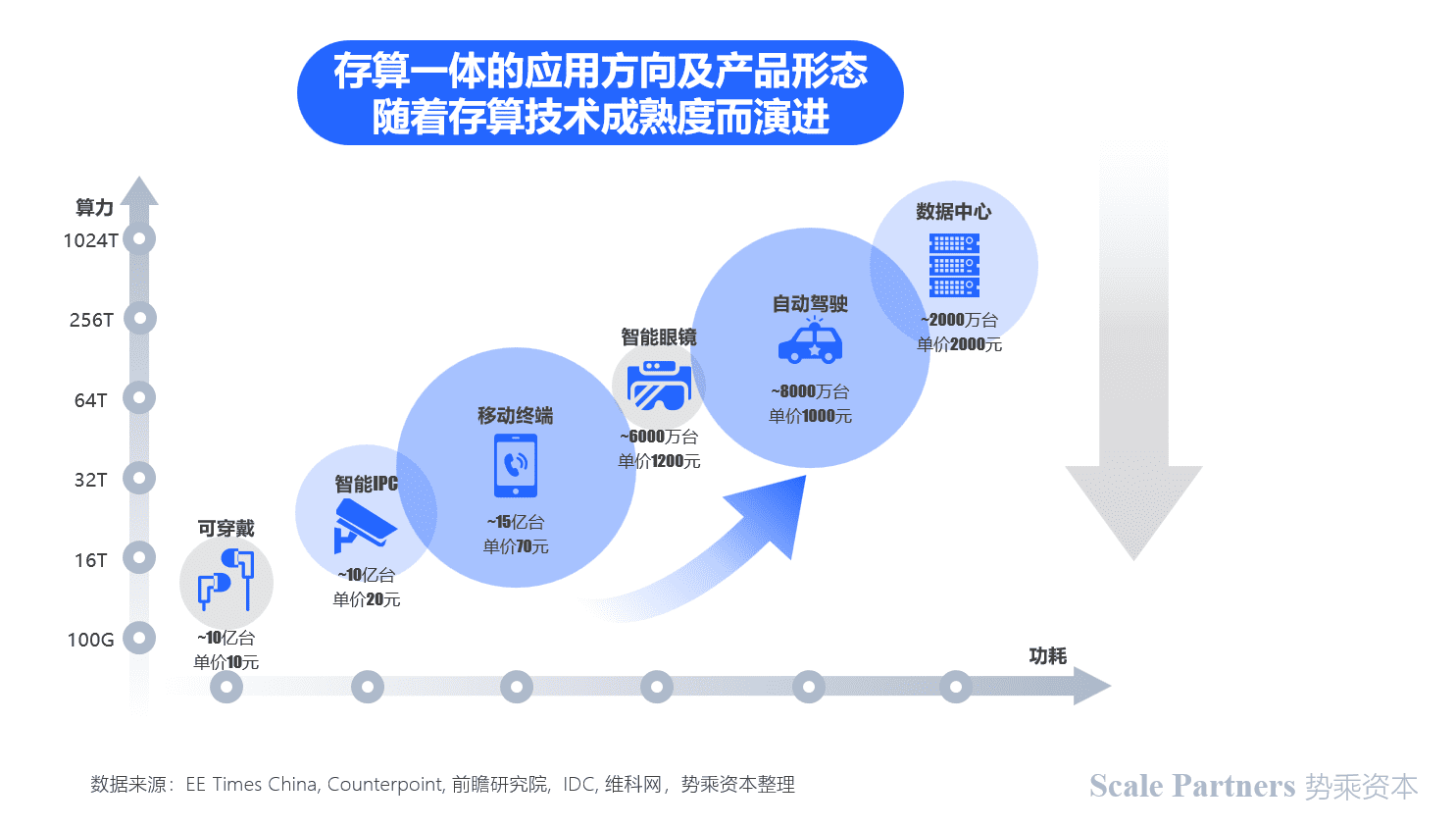
四、存算一体应用场景
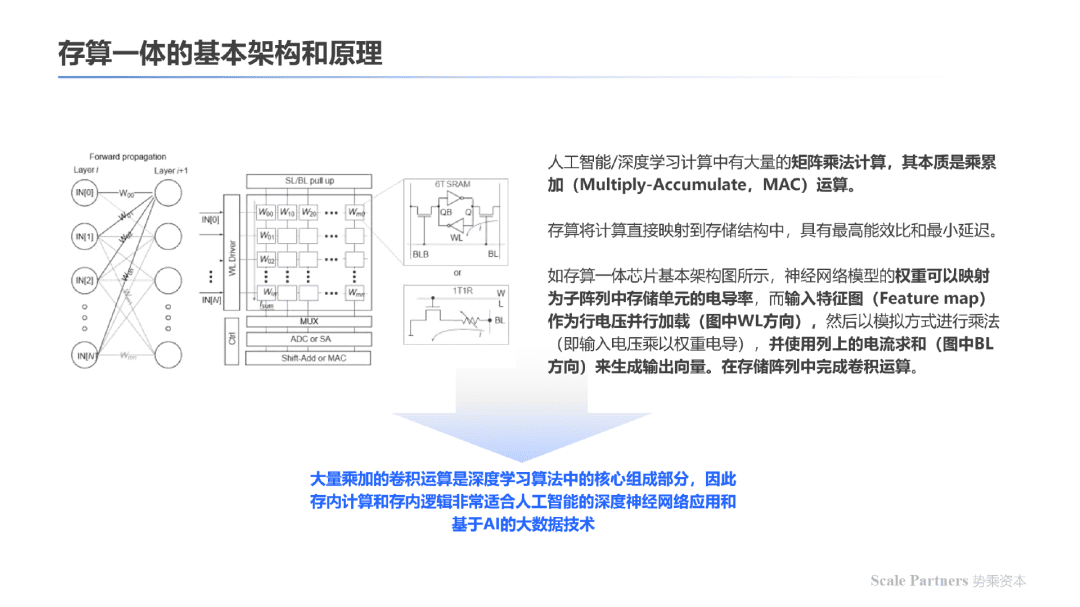
1.存算一体架构与深度学习网络运算模型高度重合。
通用性计算芯片在服务特定AI算法方面并不具备性价比优势,为AI定制的芯片将成为人工智能产业链条上的底层核心技术。
存内计算作为创新芯片架构形式,突破了存储墙问题,且其本质是乘积累加运算(Multiply Accumulate, MAC)操作加快的体现,与深度学习网络运算模型中的基本算子高度契合,使得基于存内计算架构的芯片相比于市场已有的AI加速芯片,在计算效率(TOPS/W)方面有数量级上的提升。
智能时代里,从可穿戴到自动驾驶,功耗约束下场景里的计算效率都是永恒的主题,存内计算是解放算力、提升能效比最强有力的武器之一。
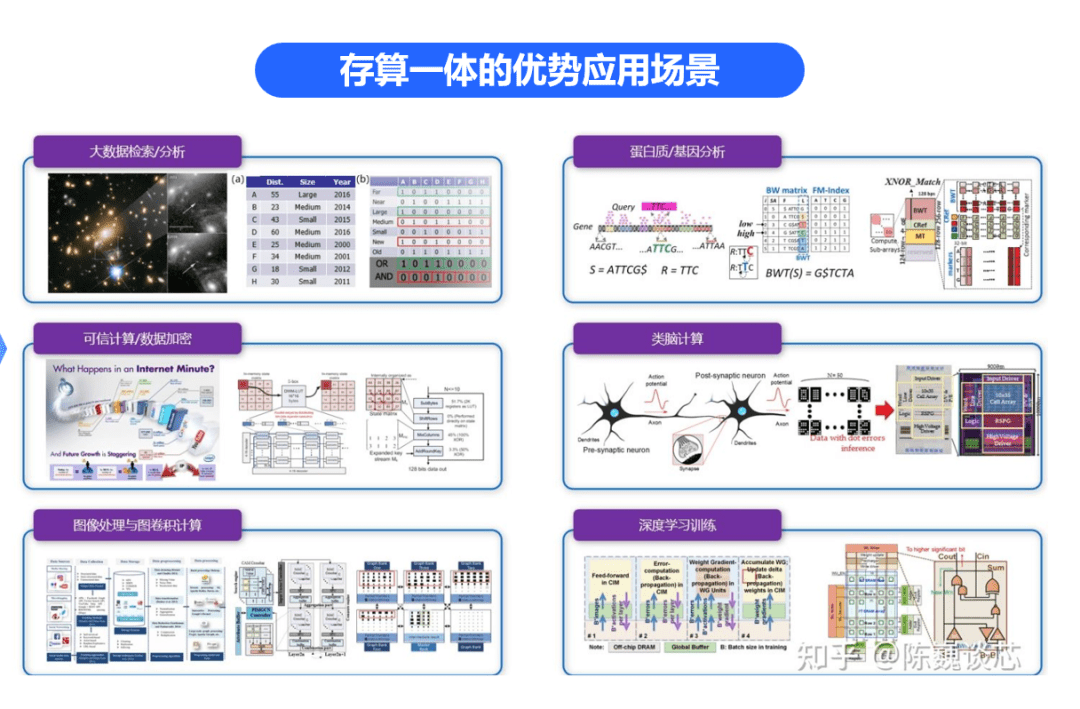
资料来源:《先进存算一体芯片设计》、知乎陈巍探芯
2.存算一体芯片适用的行业/场景
(1)小算力场景:边缘侧对成本、功耗、时延、开发难度非常敏感
中早期的存算一体芯片算力较小,从小算力1TOPS开始往上走,解决的是音频类、健康类及低功耗视觉终端侧应用场景,AI落地的芯片性能及功耗问题。
我们预测从边缘端接入的智能设备的市场体量将快速增长,智能产品覆盖面积越来越大,产品形态的多样性将迎来爆发式的增长。可以预见,由于传输延迟或数据安全考虑,很多数据处理及推理运算将在端侧发生。
(2)大算力场景:GPU在算力和能效上都无法同时与专用加速芯片竞争
目前云计算算力市场,GPU的单一架构已经不能适应不同AI计算场景的算法离散化特点,如在图像、推荐、NLP领域有各自的主流算法架构。
随着存算一体芯片算力不断提升,使用范围逐渐扩展到大算力应用领域。针对大算力场景>100TOPS,在无人车、泛机器人、智能驾驶,云计算领域提供高性能大算力和高性价比的产品。
存算技术可支持成熟制程下匹配传统结构+高级节点才能提供的计算能力,节约制造成本,绕过工艺封锁等问题。
自动驾驶要求很高,算力、可靠性、稳定性需要同时达标,需要数年,目前仍有工艺挑战和迭代,现在也还做不到数据中心的水平。
3.存算一体的其他延伸应用:感存算一体、类脑计算
存算一体作为基础原理,同样也衍生了如感存算一体、类脑计算等创新技术方向:
(1)感存算一体:
传统芯片,需要先利用传感器芯片收集信息、存储芯片进行存储、利用计算芯片来处理数据。感存算一体集传感、储存和运算为一体,在存算一体的基础上增加了传感,三位合一提高整体效率。
在传感器自身包含的AI存算一体芯片上运算,来实现零延时和超低功耗的智能处理。
研究成果来看,包括压力、光学、气体三大类;从当前应用方向来看,包括实现更高效的机器视觉和类脑计算。
(2)类脑计算:
类脑计算又被称为神经形态计算,是借鉴生物神经系统信息处理模式和结构的计算理论、体系结构、芯片设计以及应用模型与算法的总称。
试图借鉴人脑的物理结构和工作特点,让计算机完成特定计算任务,从而高速处理信息,属于大算力高能效领域。
存算一体天然是将存储和计算结合在一起的技术,天然适合应用在类脑计算领域,并成为类脑计算的关键技术基石。
五、产业现状与未来趋势
1.存算一体技术当前面临的挑战:
存算一体技术是一门非常复杂的综合性创新,产业还算不上成熟,在产业链方面仍旧存在上游支撑不足,下游应用不匹配的诸多挑战,但诸多的挑战同时也构成了当前存算一体创新未来可构筑的综合性壁垒。

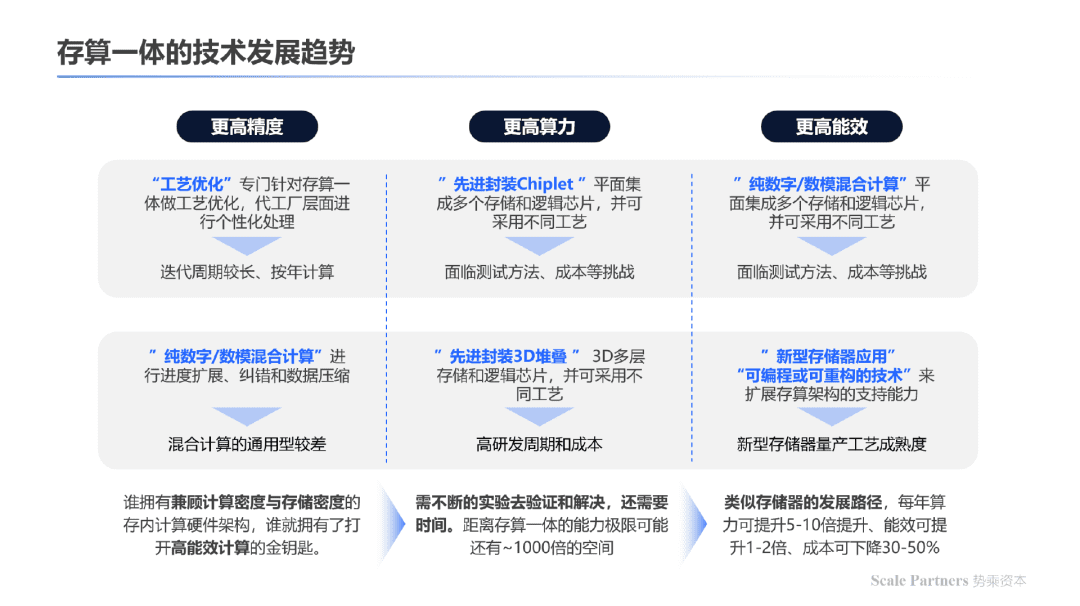
2.存算一体技术发展趋势:更高精度、更高算力、更高能效。
3.当前产业面临的人才及生态问题:
(1)作为一个新领域,存算一体芯片复合型人才稀缺,人才更多在学术界。
完成存算一体芯片的产品化开发,需同时具备较强的学术原创能力(存算一体的架构和编译器设计、存算相关的量化算法开发等)及工程实践能力(场景理解能力、芯片落地能力)。
(2)从上游到下游的生态不完整,既是挑战也是机遇。
存算一体芯片的大规模落地需与芯片厂商、软件工具厂商以及应用集成厂商等产业生态合作伙伴的大力协同研发和推广应用。
需有一套方便、可用的工具链和软件,让采购方迁移成本低。
兼容现有的软件生态,让采购方用起来“无感”,如可直接利用现有GPU训练软件框架。
引导采购方逐步切入专用工具链进行模型适配、压缩等,更好利用存算一体的优势,逐步建立生态。
六、行业相关企业分析
当前我国存算一体芯片创新企业与海外创新企业属于齐头并进阶段,共同探索存算一体技术产业化落地及应用场景,在AIoT时代巨大的应用场景下,未来我国存算一体领域有望产生引领世界的创新企业。
国内存算一体芯片企业有:苹芯科技、后摩智能、知存科技、亿铸科技、智芯科、千芯科技、九天睿芯等创新企业;国外有如Mythic、Syntiant等公司。
以下为国内外部分存算一体企业简介:









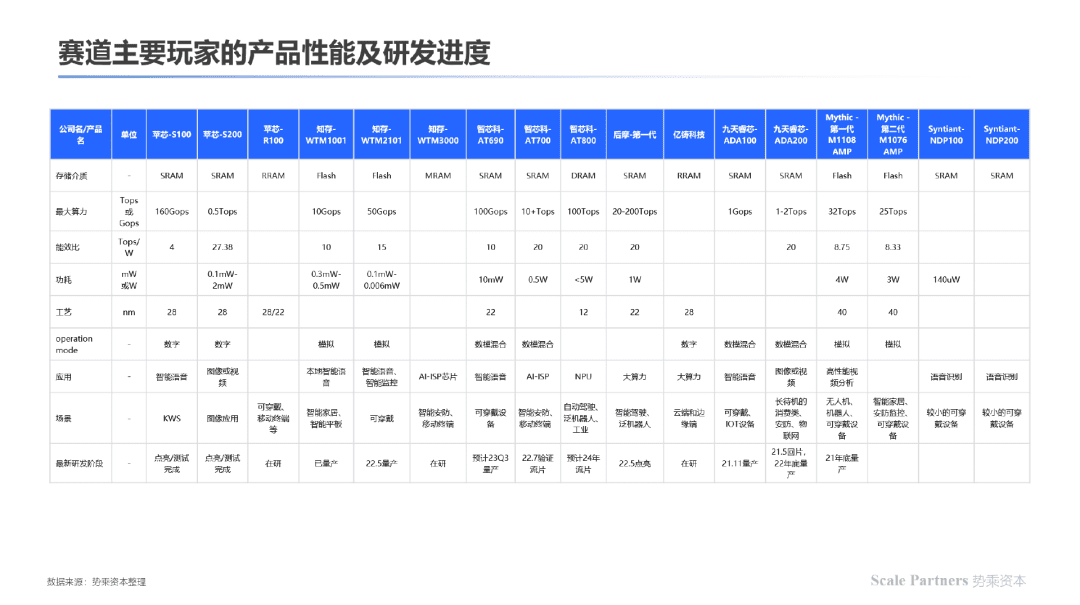
附录:赛道内主要玩家的部分产品进展及性能
本文来自投稿,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/quan/98710.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 